


De meilleurs résultats commerciaux grâce à l'opérationnalisation de l'intelligence artificielle à grande échelle
L'intelligence artificielle (IA) alimente une nouvelle normalité pour les entreprises de tous les secteurs. Les détaillants peuvent, par exemple, utiliser l'IA pour prédire les bons de commande sur la base des données d'inventaire historiques afin de prendre des décisions de réapprovisionnement intelligentes. Les équipes de support client peuvent utiliser l'IA pour répondre automatiquement aux tickets de support client hautement prioritaires et les acheminer vers les bonnes équipes. Il existe un monde de possibilités dans lesquelles vous pouvez utiliser l'IA, et plus particulièrement le ML, pour générer des résultats commerciaux pratiques.
Selon Deloitte Insights, 83 % des premiers utilisateurs de l'IA d'entreprise ont constaté un retour sur investissement (ROI) positif des projets en production. Celles-ci comprenaient des exemples tels que la mise en œuvre de logiciels d'entreprise tiers utilisant l'IA, l'utilisation de chatbots et d'assistants virtuels et de moteurs de recommandation pour les plateformes de commerce électronique. 83 % des entreprises interrogées prévoyaient d'augmenter leurs dépenses en IA en 2019. Parmi les entreprises investissant dans l'IA, 63 % avaient adopté le ML.
Construire une stratégie pour utiliser de manière pragmatique l'IA et le ML pour atteindre les objectifs commerciaux est une priorité absolue pour de nombreuses entreprises. Pour beaucoup, le principal défi pour opérationnaliser avec succès le ML est de comprendre, de planifier et d'exécuter la gestion d'un déploiement de ML holistique dans toute l'organisation.
Principales considérations pour opérationnaliser le ML
La « bonne » façon d'aborder le cycle de vie de la science des données diffère d'une organisation à l'autre. De nombreuses tentatives ont été faites pour codifier et normaliser les procédures du cycle de vie de la science des données. Cependant, aucune approche n'intègre les besoins de chaque entreprise.
Adopter une stratégie durable et maintenable pour les données et la science des données est un exercice en constante évolution propre à chaque entreprise. Étant donné que les besoins, la structure et les capacités de chaque entreprise sont uniques, les parties prenantes de l'ensemble de l'entreprise doivent être consultées pour créer un modèle de ML flexible et évolutif et exécuter une stratégie globale de science des données.
Les défis opérationnels et les modifications de l'infrastructure et des pratiques de développement auxquelles chaque entreprise doit faire face seront différents.
Il est essentiel que votre organisation tienne compte de votre culture, de vos systèmes et de vos besoins tout en définissant et en faisant évoluer le cycle de vie de la science des données. Disposer d'un cadre de base à présenter à toutes les équipes permet de développer une base commune de communication tout en continuant à développer et à faire évoluer votre opérationnalisation du ML.
Passons en revue un cadre standard qui peut aider votre organisation à démarrer son parcours de ML.
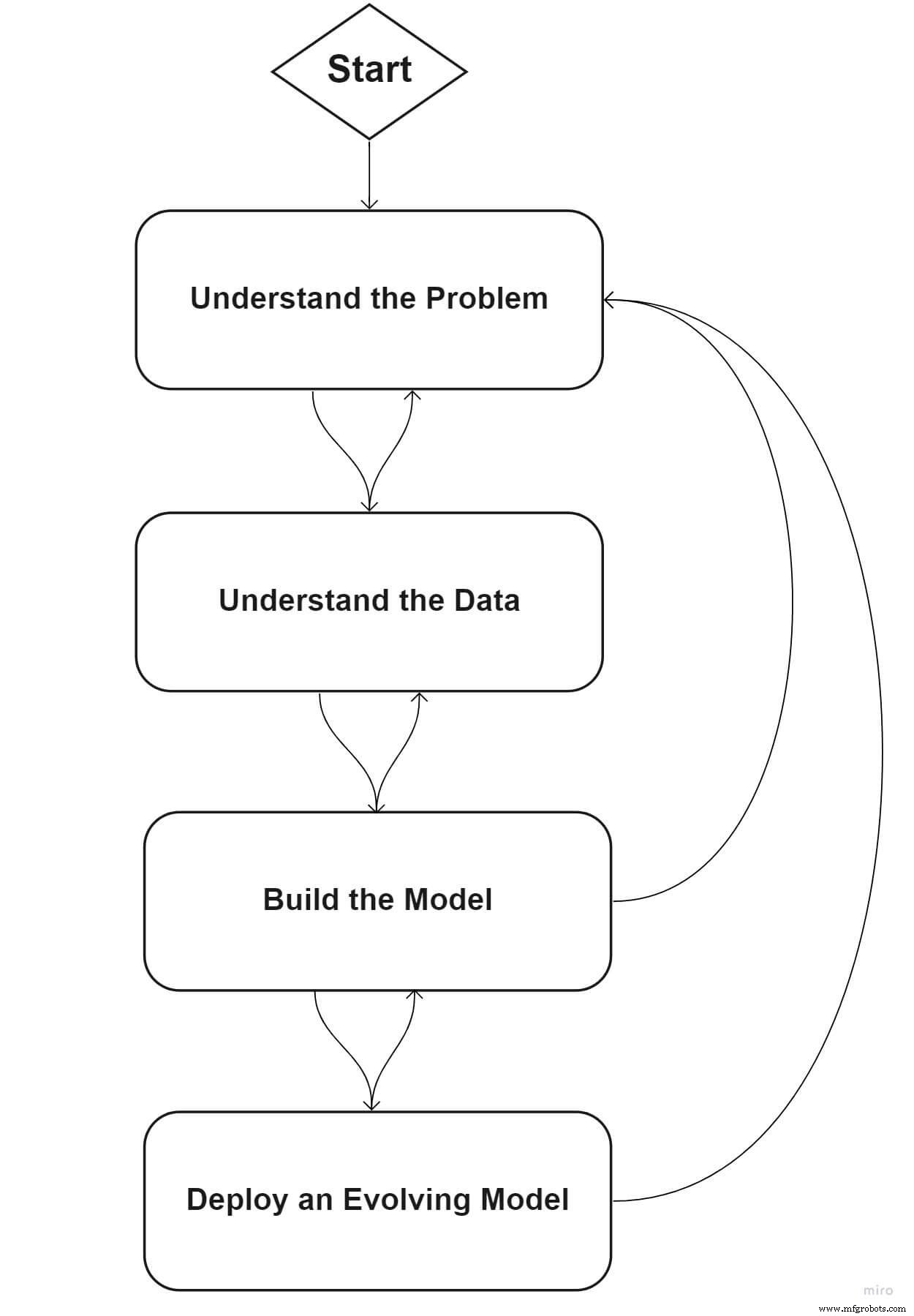
Phase 1 :Définissez votre problème
Au cœur de toute initiative de ML se trouvent deux questions :
1. Quel problème essayez-vous de résoudre ?
2. Pourquoi pensez-vous que le ML et une meilleure compréhension de vos données peuvent vous aider à résoudre le problème ?
Les réponses à ces questions dépendent de la façon dont votre entreprise réfléchit à la stratégie et évalue les problèmes commerciaux.
Au cours de la première phase, les principales parties prenantes doivent se réunir pour définir l'étendue initiale du problème et ses exigences.
Phase 2 :Comprendre vos données
Quelle est l'histoire de vos données ? D'où proviennent vos données et combien de sources de données sont pertinentes pour vous aider à résoudre votre problème métier spécifique ?
Au cours de cette phase, les entreprises se concentrent sur :
-
Cartographier les sources de données pertinentes et les environnements dans lesquels elles vivent (ces environnements peuvent être sur site ou dans le cloud, configurés comme un entrepôt de données, un lac de données ou des plates-formes de données en continu)
-
Définir quels pipelines de données existent actuellement et quels pipelines de données doivent être créés pour la validation, le nettoyage et l'exploration des données
-
Comprendre la fréquence de mise à jour des données
-
Comprendre la fiabilité des données
-
Évaluer les considérations et les exigences en matière de confidentialité des données
-
Permettre l'exploration des données via des visualisations, des propriétés statistiques des données brutes et transformées, etc.
Comprendre vos données n'est pas une mince affaire. Il est important d'aborder cette phase de manière itérative. Au fur et à mesure que vous en découvrirez plus sur vos données, vous découvrirez peut-être des problèmes ayant une incidence sur votre capacité à résoudre le problème, ce qui peut nécessiter en outre que vous redéfinissiez ou redéfinissiez le problème dès la première phase.
Phase 3 :Créer le modèle de ML
Une fois que vous avez les données prêtes, il est temps pour vos data scientists de créer un modèle ML. Voici les étapes courantes pour créer un modèle de ML robuste :
-
Fonctionnalités d'extraction et d'ingénierie (comprend le regroupement, le blanchiment des données et l'application de transformations statistiques)
-
Sélection des fonctionnalités
-
Entraîner le modèle (comprend le fractionnement des données en un nombre quelconque d'ensembles de données d'entraînement, de validation croisée et de validation)
-
Réglage des hyperparamètres
-
Évaluation du modèle
-
Validation de la signification statistique
L'élaboration d'un modèle nécessite une rétroaction continue des parties prenantes de l'entreprise. Par exemple, le problème métier peut faire appel à une affinité de sensibilité vis-à-vis de la spécificité. De même, vous pouvez échanger de légères performances prédictives (par exemple, le score F1) contre des performances opérationnelles du modèle (par exemple, des prédictions plus rapides) ou l'explicabilité du modèle.
L'objectif du scientifique des données est de construire un modèle qui utilise des données pour raconter une histoire claire liée au problème de l'entreprise. À mesure que le problème évolue et que les exigences changent, l'approche de la modélisation doit également évoluer pour servir le contexte actuel.
Phase 4 :Déployer un modèle évolutif
La construction du modèle initial n'est que le début du parcours de ML. Le déploiement d'un modèle évolutif est une étape cruciale dans la création de valeur à long terme pour l'organisation.
Déployer un modèle évolutif nécessite :
-
Servir le modèle (rendre le modèle hautement disponible et évolutif horizontalement)
-
Gestion des versions de modèle (y compris les restaurations et les déploiements Canary/challenger)
-
Réentraîner le modèle (modifier ou créer un nouveau modèle à mesure que de nouvelles données entrent dans le système)
-
Surveillance du modèle (suivi des métriques opérationnelles et d'expérience utilisateur au moment de la diffusion et de la formation)
La surveillance des données et de la dérive des modèles, la spécialisation d'un modèle pour des cas d'utilisation intra-organisationnels ciblés et la maintenance des pipelines de données (entre autres éléments de maintenance) sont essentielles au succès continu d'un modèle.
Les exigences à l'échelle de l'entreprise et de l'industrie peuvent évoluer rapidement et avoir un impact sur les sources et les entrées de données. Par exemple, la gouvernance et la conformité à grande échelle sont des considérations couvrant l'ensemble du cycle de vie de la science des données.
La conformité aux réglementations, telles que le règlement général sur la protection des données (RGPD) de l'Union européenne (UE), nécessite un niveau de traçabilité plus élevé au niveau des versions de données, des versions de modèle et des couches d'entrée de modèle. L'élaboration d'une stratégie pour répondre à ces changements et exigences du secteur grâce aux données peut aider les entreprises à continuer à tirer parti du ML pour obtenir de meilleurs résultats commerciaux tels que la croissance des revenus, la réduction des coûts et la diminution des risques.
Quelle est la prochaine ?
L'opérationnalisation du ML de manière flexible, maintenable et évolutive nécessite de nombreuses étapes et considérations au-delà de la portée de haut niveau de ce que nous avons décrit dans ce blog. Le diable est dans les détails.
Dans notre prochain blog, nous approfondirons les considérations techniques, les défis qui peuvent survenir lors de la mise en œuvre ad hoc d'un système de ML à grande échelle et comment UiPath aide à relever les défis courants des entreprises clientes.
Système de contrôle d'automatisation
- Bosch ajoute l'intelligence artificielle à l'industrie 4.0
- L'intelligence artificielle est-elle une fiction ou une mode ?
- L'intelligence artificielle aura-t-elle tôt ou tard un impact sur l'IoT ?
- Pourquoi l'Internet des objets a besoin d'intelligence artificielle
- Comment créer une stratégie de Business Intelligence réussie
- Évolution de l'automatisation des tests avec l'intelligence artificielle
- AIoT industriel :combiner l'intelligence artificielle et l'IoT pour l'industrie 4.0
- Robots d'intelligence artificielle
- Avantages et inconvénients de l'intelligence artificielle