


Tolérance aux pannes et son impact sur la fiabilité du système
Les équipements et systèmes conçus sans tolérance aux pannes ont souvent une fiabilité (plus) médiocre.
C'est pourquoi une conception de système tolérant aux pannes est un choix évident pour la plupart des ingénieurs de conception et de fiabilité, en particulier lorsqu'il s'agit d'équipements critiques dont la défaillance peut compromettre la fiabilité, la disponibilité, la maintenabilité et la sécurité (RAMS) de l'ensemble du système. partie.
Rejoignez-nous pour explorer les caractéristiques des systèmes tolérants aux pannes et discuter des moyens d'améliorer la tolérance aux pannes grâce à des conceptions redondantes.
Qu'est-ce que la tolérance aux pannes ?
La tolérance aux pannes représente la capacité de tout système ou équipement à maintenir son fonctionnement en cas de panne.
Les systèmes et équipements à haute tolérance aux pannes, en fonction du mécanisme de tolérance aux pannes adopté, sont capables de maintenir complètement ou partiellement leur fonctionnement en cas de panne. Pour que cela fonctionne dans la pratique, de tels systèmes ne peuvent pas avoir de point de défaillance unique (SPOF).
L'essence des conceptions tolérantes aux pannes
Le développement d'une conception tolérante aux pannes nécessite un examen attentif des défaillances qui peuvent se manifester tout au long du cycle de vie de l'équipement, ainsi que de leurs causes et conséquences probables.
Cependant, les ingénieurs de conception doivent également prendre en compte les facteurs de coût et de ressources nécessaires pour atteindre le niveau requis de tolérance, de fiabilité et de fiabilité de l'équipement.
Il est souvent mal compris qu'une conception tolérante aux pannes devrait fournir une tolérance complète à tous les types de pannes. Ce n'est pas vrai. Une bonne conception doit correspondre au degré de tolérance à la criticité du défaut de manière à ce que l'optimisation globale de l'efficacité des coûts et des ressources puisse être réalisée.
Par exemple, il peut ne pas être rentable de dépenser de l'argent pour la refonte d'un produit, simplement pour remédier à un défaut qui a extrêmement peu de chances de se produire.
Caractéristiques des systèmes tolérants aux pannes
Pour créer un système tolérant aux pannes, des efforts sont nécessaires à chaque étape du cycle de vie de l'équipement. Cela inclut, mais sans s'y limiter, la spécification et la phase de conception (en intégrant les contrôles de détection des défauts dans la conception), la validation et la vérification (V&V), la maintenance et l'exploitation (en utilisant des pièces de rechange approuvées par l'OEM et des directives pour la maintenance de routine), et même l'étape de mise au rebut .
Chaque étape peut adopter des combinaisons des techniques indiquées ci-dessous pour développer de nouvelles conceptions ou améliorer les conceptions actuelles afin d'améliorer leur niveau de tolérance aux pannes :
- détection et affichage des défauts
- diagnostic et confinement des pannes
- masquage et compensation des défauts
1) Détection et affichage des défauts
La détection de défaut fait référence à la capacité du système/équipement à détecter et afficher le défaut. C'est l'aspect fondamental de tout système tolérant aux pannes . Tous les autres aspects dépendent de l'efficacité du processus de détection des défauts. Si le système n'est pas conçu pour détecter son défaut, ou détecte un défaut d'une manière ou d'une autre de manière incorrecte, le reste des aspects sera également inefficace.
Par exemple, un simple capteur de pression d'air dans un système de surveillance de la pression des pneus de voiture (TPMS) peut détecter le débordement d'air et avertir le conducteur via le tableau de bord de la voiture.
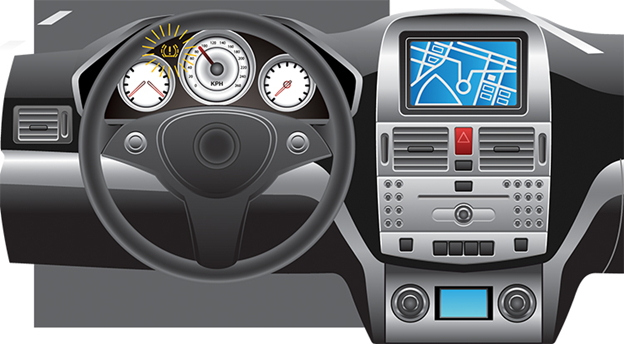
Une représentation de l'activation TPMS
Dans ce cas, la détection et l'affichage sont le seul niveau de tolérance acceptable pour cet événement de défaut. Le client peut débrancher le tuyau d'air en toute sécurité avant de rompre le pneu.
Si la détection de pression est inexacte, le conducteur peut désengager le tuyau trop tôt/tard et subir une défaillance des pneus pendant la conduite. Puisqu'il n'y a pas de correction automatique de la pression d'air, l'aspect de tolérance pour ce défaut se limite à la détection et à l'affichage.
2) Diagnostic et confinement des défauts
Dans les systèmes plus sophistiqués, des couches supplémentaires sont souvent ajoutées au stade de la conception du produit. Leur objectif est de diagnostiquer et d'effectuer le confinement en plus de la détection et de l'affichage. Ces couches supplémentaires sont justifiées en raison de la criticité du système ou en raison de divers problèmes de sécurité.
Par exemple, un système de contrôle distribué (DCS) - un système de contrôle pour les usines de traitement - non seulement surveille les paramètres de processus critiques via un ensemble de capteurs, mais effectue également un diagnostic pour détecter l'emplacement du défaut et effectuer le confinement nécessaire.
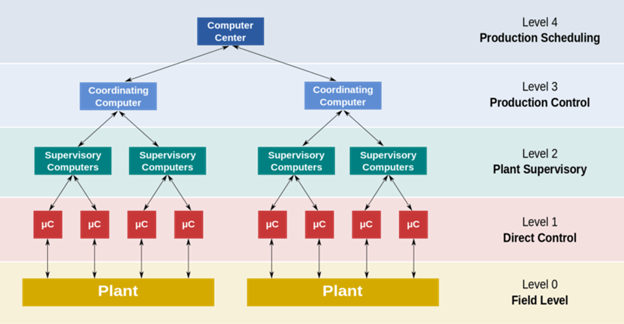
Une représentation du système DCS
Par exemple, en cas de surpression de produits pétroliers dans une cuve, le système est déclenché par des capteurs de pression pertinents. Il ouvre la soupape de sécurité et évacue les vapeurs dans la torchère.
Dans cet exemple, le confinement est réalisé en détournant les vapeurs inflammables à haute pression vers la cheminée d'échappement, protégeant ainsi le système d'un incendie ou d'une explosion.
3) Masquage et compensation des défauts
Une autre approche efficace de la tolérance aux pannes consiste à masquer l'état de panne. Il est très efficace pour les équipements qui peuvent être surveillés et contrôlés via la technologie Internet des objets (IoT).
Avec un tel équipement, l'un des défis les plus importants se présente sous la forme de menaces de cybersécurité. Ces types de menaces peuvent tenter d'induire la panne en modifiant l'état de l'équipement par l'injection de fausses données d'équipement dans le serveur.
Avec des enregistrements d'état d'équipement incorrects, le système de contrôle et de surveillance même destiné à l'origine à protéger peut à la place provoquer la défaillance de l'actif. Alternativement, il peut être « trompé » en pensant que l'actif est en bon état alors qu'il ne l'est pas en réalité – laissant la détérioration conduire à une défaillance sans déclencher aucune alerte.
En incorporant le masquage des défauts, le système est conçu de manière à pouvoir reconnaître et masquer ces valeurs incorrectes.
Par exemple, dans les réseaux électriques, les disjoncteurs sont souvent contrôlés et surveillés via le contrôle de supervision et l'acquisition de données (SCADA).
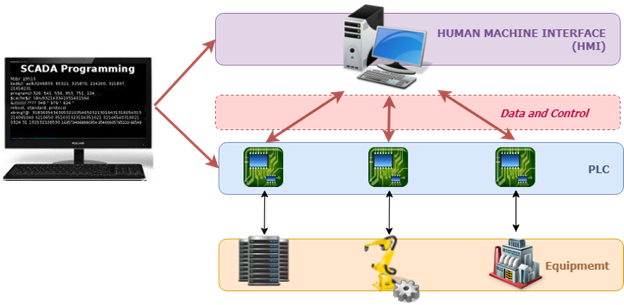
Une représentation du système SCADA
Un tel système surveille de près les paramètres de tension et de fréquence des équipements électriques et provoque leur fermeture ou leur ouverture pour maintenir la stabilité du réseau électrique.
Une cyberattaque entrante pourrait modifier les limites de tension et de fréquence de l'équipement. Conséquences? Le système pourrait provoquer une panne de courant au lieu de l'empêcher.
Le masquage des défauts est souvent effectué au moyen d'algorithmes qui détectent des flux de données anormaux et injectent de fausses données dans le but de masquer les données qui représentent l'état défectueux de l'équipement. Cela empêche les mauvais acteurs des données de propager la faute et d'exacerber davantage la fiabilité du réseau.
Améliorer la tolérance aux pannes grâce à des conceptions redondantes
L'une des actions simples qui peuvent être prises pour augmenter la tolérance aux pannes consiste à intégrer des redondances dans la conception. La redondance signifie simplement la présence d'un système ou d'une solution alternative qui peut prendre en charge la fonction prévue en cas de défaillance du système principal.
Bien que la redondance améliore la tolérance aux pannes, l'ajout de systèmes au hasard ne devrait pas être l'objectif, car le montant des coûts requis pour ajouter un nouveau système peut considérablement l'emporter sur les avantages de fiabilité réalisables.
Du point de vue de l'équipement physique, ils peuvent être globalement classés comme actifs ou licenciements passifs .
Licenciements actifs
Des redondances actives peuvent être établies lorsque plusieurs équipements sont exploités simultanément. Dans cette configuration, chaque équipement contribue pour sa part à l'atteinte de la fonction prévue tout en agissant comme redondance l'un pour l'autre.
Une redondance active simpliste est le fonctionnement en parallèle de deux pompes à la moitié de leurs capacités nominales. Les deux pompes fonctionnent conjointement pour atteindre la pression de refoulement souhaitée. Si une pompe tombe en panne, l'autre pompe peut encore être augmentée à sa capacité nominale pour atteindre par elle-même la pression de refoulement prévue. Pour réaliser des économies de conception, les ingénieurs de fiabilité ont mis au point divers autres moyens compliqués d'obtenir des redondances actives telles que des redondances K sur N et une dégradation gracieuse.
Dans K de N licenciements , un sous-ensemble donné d'équipements est toujours en fonctionnement. Cela augmente la fiabilité du système car certains équipements sont toujours en attente directe et peuvent rejoindre le fonctionnement en cas de panne de certains équipements. Cela garantit une plus grande fiabilité par rapport au simple fonctionnement en parallèle de deux pompes car il y aura un plus grand nombre de petites pompes en fonctionnement.
Dégradation gracieuse est une alternative à l'ajout de systèmes identiques et parallèles coûteux. Il garantit que les caractéristiques ou la fonctionnalité de l'ensemble de l'équipement se dégradent proportionnellement au nombre de composants défaillants. Pour obtenir une telle dégradation évolutive, un examen de toutes les défaillances possibles au sein de tous les composants doit être effectué. Leur impact sur les performances globales du système doit être analysé et documenté.
De telles techniques offrent une tolérance aux pannes partielles et permettent au système de continuer à fonctionner avec une capacité dégradée.
Licenciements passifs
La redondance passive est la redondance de secours où l'équipement alternatif est présent - mais elle ne peut prendre en charge la fonction prévue qu'en cas de défaillance de l'équipement principal.
On peut distinguer deux types de licenciements passifs :
- opérer des licenciements passifs
- licenciements passifs hors exploitation
Gérer des licenciements passifs sont ceux où l'équipement alternatif est présent en tant que disque de secours. L'équipement de secours est chaud car il pourrait fonctionner à vide. Dans certains cas, il peut remplir une fonction qui n'entre pas dans la définition de la fonction de l'équipement principal.
En cas de défaillance de l'équipement principal, l'équipement de secours en fonctionnement peut être automatiquement mis en œuvre pour remplir la fonction d'équipement principal.
Un exemple d'exploitation de redondances passives peut être un alternateur secondaire qui fonctionne dans des conditions à vide et répond à toutes les autres conditions de mise en parallèle telles que la même tension aux bornes, la même fréquence et la même séquence de phases. En cas de panne de l'alternateur primaire, l'alternateur secondaire peut être automatiquement synchronisé avec le système et reprendre la charge.
En cas de licenciements passifs hors exploitation , l'équipement de secours est hors tension. En cas de défaillance de l'équipement primaire, l'équipement de secours peut être automatiquement ou manuellement mis aux conditions de fonctionnement et prendre en charge la fonctionnalité de l'équipement primaire.
Un bon exemple de redondance passive non opérationnelle est une pompe à eau municipale de secours qui peut être démarrée et actionnée manuellement pour fournir de l'eau aux résidents en cas de dysfonctionnement de la pompe à eau principale. Le rétablissement du fonctionnement n'étant pas critique, un opérateur peut aller démarrer la pompe (et la synchroniser avec le système ultérieurement, au besoin).
Techniques de fiabilité pour l'analyse de la tolérance aux pannes
La tolérance aux pannes fait partie des efforts d'ingénierie de fiabilité et nécessite un examen attentif de toutes les pannes possibles pouvant survenir au sein de l'équipement. L'analyse de l'effet du mode de défaillance (FMEA) et l'analyse de l'arbre de défaillance (FTA) sont deux techniques bien connues pour analyser la conception du système à partir d'approches ascendantes et descendantes respectivement.
Pour mieux comprendre la tolérance, la séquence de défaillance et les dépendances doivent être analysées et étudiées. Une technique particulièrement utile pour analyser les dépendances et la séquence est le modèle de Markov où la probabilité de tout événement de défaillance dépendrait de l'état de l'événement précédent.
De même, une autre technique puissante est la simulation Monte Carlo qui peut être utilisée pour modéliser l'impact des incertitudes de tout événement de défaillance sur les performances du système.
Tolérance aux pannes et opérations de maintenance
Les systèmes tolérants aux pannes nécessitent-ils moins de maintenance ? Eh bien, oui et non.
En raison des redondances et d'autres caractéristiques dont nous avons parlé précédemment, de tels systèmes peuvent généralement prendre plus de défauts avant que leur fonctionnalité ne soit compromise. Cependant, si les problèmes ne sont pas résolus, l'accumulation de défauts entraînera éventuellement une panne du système ou de l'équipement. Par conséquent, les équipes de maintenance doivent utiliser un système de GMAO pour s'assurer que les actions de maintenance correctives sont prises en temps voulu.
Dans un certain sens, la tolérance aux pannes donne aux équipes de maintenance et de support plus de marge de manœuvre. Ils doivent encore régler le problème, mais peut-être pas tout de suite.
Alors que les conceptions tolérantes aux pannes ont leurs défis en termes de coûts et de complexité accrus, elles les compensent sous la forme d'une fiabilité améliorée de l'équipement.
Entretien et réparation d'équipement
- Meilleurs performances en maintenance et fiabilité
- Maintenance et fiabilité - ce n'est jamais assez bon
- Les détails comptent pour la maintenance et la fiabilité
- Fournisseurs de maintenance et de fiabilité :attention aux acheteurs
- Fabrication flexible et fiabilité peuvent coexister
- Application de l'entropie à la maintenance et à la fiabilité
- UT renomme le programme en Centre de fiabilité et de maintenance
- Un point de vue des kayakistes sur la fiabilité et la sécurité
- ISA publie un livre sur la sécurité et la fiabilité des systèmes de contrôle