


Étude de cas sur la fiabilité des usines pharmaceutiques
Les professionnels de la maintenance et de la fiabilité peuvent faire la différence. Dans la plupart des usines de fabrication, cela signifie un travail ciblé qui permet aux opérations d'obtenir plus de produits finis (qu'il s'agisse de boissons gazeuses, de motos, d'ampoules électriques, de voitures, de cupcakes, de chauffe-eau, etc.) à la porte.
À l'usine d'insuline humaine biosynthétique (BHI) d'Eli Lilly à Indianapolis, faire la différence prend une importance accrue.
 Le groupe d'ingénierie de fiabilité de l'usine Eli Lilly BHI comprend (de gauche à droite) l'ingénieur principal en fiabilité Vadim Redchanskiy, fiabilité la technicienne en ingénierie Mary Ann Dust, le chef d'équipe de maintenance et de fiabilité Ken Swank et l'ingénieur senior en fiabilité Mark Lafever.
Le groupe d'ingénierie de fiabilité de l'usine Eli Lilly BHI comprend (de gauche à droite) l'ingénieur principal en fiabilité Vadim Redchanskiy, fiabilité la technicienne en ingénierie Mary Ann Dust, le chef d'équipe de maintenance et de fiabilité Ken Swank et l'ingénieur senior en fiabilité Mark Lafever. Près de 21 millions de personnes en Amérique – et 200 millions de personnes dans le monde – souffrent de diabète. Aux États-Unis seulement, près d'un million de nouveaux cas sont diagnostiqués chaque année. De nombreuses personnes atteintes de diabète ont besoin d'insuline pour contrôler leur glycémie (glucose), et la plante BHI aide à combler ce besoin. Ouvert à la production en 1992, le site produit un pourcentage important de l'insuline médicinale mondiale. Les travaux de maintenance et de fiabilité qui améliorent la productivité permettent à l'entreprise de mettre des médicaments de haute qualité et vitaux à la disposition de ceux qui en ont besoin.
 Eli Lilly produit de l'insuline médicinale depuis plus de 80 ans.
Eli Lilly produit de l'insuline médicinale depuis plus de 80 ans. Que vous travailliez pour une entreprise qui fabrique des puces informatiques ou des chips, lorsque vous ajoutez de la valeur à la partie prenante ou à l'économie, cela ne peut en aucun cas être sous-estimé », déclare Ken Swank, chef de l'équipe de maintenance et de fiabilité de l'usine. « Peu importe ce que vous faites. C'est important. Il y a cependant une différence distincte. J'ai travaillé pour une entreprise de revêtements industriels. Nos revêtements sont entrés dans tout, des balles de golf à la navette spatiale en passant par les instruments chirurgicaux. Quand j'ai vu le produit final, j'ai su que j'en faisais partie. Mais quand vous travaillez pour une entreprise pharmaceutique. . . cela signifie beaucoup sur le plan personnel.
J'ai rencontré un couple ce week-end qui a un jeune fils. Nous avons commencé à parler et j'ai découvert que le garçon avait le diabète. Je lui ai demandé s'il avait le type 1 ou le type 2. Le père a demandé, comment en savez-vous autant sur le diabète ? Le garçon m'a dit qu'il était de type 1. Je l'ai regardé et j'ai dit :« Devine ce que je fais dans la vie ? Je fais de l'insuline. Je travaille chez Eli Lilly et je fabrique Humulin.' Il a dit:'Merci. J'aime beaucoup ma médecine. Cela me fait me sentir beaucoup mieux.'
« Mon service est chargé de s'assurer que ce bâtiment fabrique le médicament qu'il est censé fabriquer à chaque fois. Il y a des millions de personnes qui en dépendent et s'en servent chaque jour."

Le campus de l'entreprise à Indianapolis contient
des sites de fabrication et des bureaux.
Demandes croissantes
L'usine BHI est grande et techniquement complexe. Il abrite plus de 17 000 équipements, 13 000 points d'entrées/sorties et 600 blocs opératoires. La méthode de traitement pour générer la molécule BHI implique plusieurs étapes de centrifugation, une poignée de réactions, de nombreuses étapes de purification et diverses étapes d'échange de solvant. En conséquence, environ un tiers des unités d'exploitation sont classées comme une opération à haut risque ou critique pour la sécurité.
Il y a quelques années, les responsables de la maintenance et de la fiabilité ont décidé qu'il était nécessaire de procéder à des changements substantiels afin de maximiser le temps, les compétences, les ressources et l'impact potentiel du service sur l'usine. BHI fonctionnait à plus du double de sa capacité de conception initiale et la demande commerciale a continué d'augmenter. Les techniciens étaient surchargés, les efforts de remédiation étaient fréquemment redéfinis pour répondre aux besoins du moment, et les systèmes cruciaux ne recevaient pas un juste pourcentage d'attention.
 Eli Lilly produit 25 % de l'approvisionnement en insuline dans le monde.
Eli Lilly produit 25 % de l'approvisionnement en insuline dans le monde. Nous n'avons jamais été préoccupés par le fonctionnement de notre équipement dans un état qualifié », déclare Swank. « Mais comme le reste de l'industrie pharmaceutique à l'époque, nous n'avons pas accordé une importance particulière à notre équipement, si ce n'est que nous voulions toujours la plus grande disponibilité possible afin de fabriquer le plus de médicaments possible. Mais lorsque vous envisagez de faire sortir autant de kilos que possible, nous sommes arrivés au point où vous vous demandez :« Continuons-nous à ajouter des installations ou le faisons-nous intelligemment d'un point de vue commercial et nous nous concentrons sur la fiabilité ? » »
C'était quelque chose que de nombreuses installations d'Eli Lilly réfléchissaient à la fin des années 1990. Par exemple, Ron Reimer, directeur de l'ingénierie de BHI, a dirigé les efforts visant à augmenter le travail proactif et la disponibilité et à réduire les coûts de maintenance sur le site des laboratoires de Clinton (Ind.). Dans le cadre de ce projet, qui a ensuite été systématisé et baptisé Gestion proactive des actifs, il a embauché le premier ingénieur en fiabilité de l'entreprise.

Implication directe de tous les acteurs clés de la fiabilité de l'usine
(production, HSE, contrôle qualité, finances, ingénierie et
gestion) contribue à assurer le succès de l'initiative de priorisation de la fiabilité
.
Les efforts d'amélioration de BHI ont commencé avec l'ajout d'un ingénieur de fiabilité en 1999 et l'introduction de projets de maintenance centrée sur la fiabilité (RCM) et d'analyse des causes de défaillance (RCFA). Ces efforts se sont intensifiés lorsque les organismes de réglementation tels que la Food and Drug Administration et l'Environmental Protection Agency ont commencé à examiner de près la maintenance dans l'industrie pharmaceutique. Le message des agences était simple :maintenance rime avec fiabilité des installations; la fiabilité de l'usine équivaut à la fiabilité du produit ; et la fiabilité globale équivaut à la conformité. Les entreprises « peu fiables » peuvent faire face à des sanctions, y compris l'arrêt des opérations.
Importance de la communication
Selon le chef de l'équipe de maintenance et de fiabilité Ken Swank, la communication joue un rôle majeur dans le succès de l'initiative de priorisation de la fiabilité de l'usine BHI.
« La communication est l'une des parties les plus importantes de mon travail », dit-il. « Je rencontre fréquemment les responsables de la production et leur explique ce qui se passe. Je reçois leur engagement et les aide à comprendre la valeur qu'il ajoute. Ils doivent aussi mobiliser des ressources. Une analyse appropriée n'est pas seulement notre département, évidemment. Cela implique l'ingénierie, la maintenance, la fiabilité, les opérations, les services techniques, l'automatisation parfois. Nous passons beaucoup de temps à nous assurer qu'ils comprennent la valeur.
Je dois faire pas mal de danse et de chant pour les aider à comprendre. Mais de tous les comptes, le buy-in a été bon."
« C'est à ce moment-là, je pense, que la fiabilité a commencé à prendre l'accent qu'elle a aujourd'hui », déclare Swank. « Dans notre cheminement pour devenir une usine vraiment fiable, la vision est que lorsque la production utilise un morceau de l'équipement, il est dans un état qualifié, il est disponible quand ils en ont besoin et il fonctionnera au niveau de performance prédéterminé. Nous y jouons évidemment un grand rôle. État qualifié. En outre, la profondeur des stratégies de maintenance tient compte de l'utilisation ou du temps de disponibilité requis. Certaines opérations dans l'installation fonctionnent plus que d'autres, ont moins de redondance que d'autres ou sont plus essentielles que d'autres. Celles-ci nécessitent plus d'attention et une enquête plus détaillée ."
Une initiative de hiérarchisation qui a commencé au début de 2004 a été au cœur de cette stratégie pour offrir une disponibilité et une fiabilité aux unités d'exploitation qui méritent le plus d'attention.
Comment Eli Lilly définit les rôles de fiabilité
Selon les responsables de la maintenance et de la fiabilité d'Eli Lilly BHI, les fonctions et les responsabilités de leurs ingénieurs de fiabilité comprennent :
- Minimiser les pannes d'équipement via RCFA, FMEA, analyse RCM, enquêtes sur les écarts de plomb, etc.
- Développer des métriques pour optimiser les efforts et les ressources de fiabilité.
- Propres plans de maintenance (revoir/générer/approuver) pour les équipements nouveaux et existants.
- Fournir des projets axés sur la fiabilité qui ont un impact sur l'ensemble du flux.
- Concentrez les pratiques commerciales sur la maintenance et la fiabilité pour augmenter la disponibilité des équipements.
- Encadrer des techniciens en fiabilité.
- Intégrez les équipes de la salle de contrôle pour soutenir efficacement leur entreprise.
- Rechercher et mettre en œuvre de nouvelles technologies pour améliorer les performances et la disponibilité des équipements.
Les fonctions et les responsabilités des techniciens en fiabilité comprennent :
- Soutenir les initiatives du site.
- Remplir et traiter les formulaires de saisie de données GMAO.
- Assister les ingénieurs de fiabilité avec les RCFA, l'exploration de données, les AMDEC, les RCM, les écarts, les contrôles de changement, la vérification sur le terrain, l'amélioration des données de la GMAO, etc.
- Projets spéciaux - soutenir les efforts de fiabilité, etc.
Faites-en une priorité
Swank raconte les ordres de marche qui mèneraient finalement à un remède de fiabilité.
« Mon patron à l'époque m'a dit : « Découvrez comment nous allons rendre l'installation de BHI plus fiable. Nous devons maîtriser cela », déclare Swank. « Ce qu'il voulait vraiment dire, c'est : « Vous et votre équipe devez comprendre les besoins commerciaux de l'installation, déterminer une méthode pour définir une voie à suivre pour remédier aux lacunes de fiabilité correctement hiérarchisées, la vendre à l'entreprise, l'exécuter et faire c'est durable. »
Cela semble assez facile, du moins le pensait-il.
« Nous avons commencé en février (2004) et avons supposé que nous aurions terminé en mars ou avril », dit-il. « Nous nous sommes vite rendu compte que c'était plus compliqué et plus complexe que prévu. De plus, nous voulions faire les choses correctement. »
Le plan de match serait de développer une analyse qui utilise les données existantes pour prioriser la correction du système en tant qu'effort d'amélioration continue en dehors des efforts de soutien quotidiens du département. Les exigences d'analyse étaient les suivantes :
- cela prendrait les systèmes identifiés et les classerait en fonction de l'impact commercial sur la base des données ;
- toutes les parties prenantes seraient représentées ;
- l'analyse pourrait être exécutée en moins d'une semaine-homme (40 heures).
Ce défi a été placé sur les épaules de la partie de l'ingénierie de fiabilité du ministère. Le groupe comprenait les ingénieurs principaux en fiabilité Mark Lafever, Vadim Redchanskiy et Rod Matasovsky (maintenant à la retraite) et les techniciens en ingénierie de fiabilité David Doyle, Mary Ann Dust et Matt O'Dell. Ils ont commencé à élaborer une stratégie sur le contenu de l'analyse.
« Ce sont les intelligents. J'étais le traducteur de la direction aux gars sur le terrain », explique Swank. "Ils ont compris les systèmes de données, et ce qui avait du sens et ce qui n'en avait pas."
Le groupe a reconnu que pour obtenir un soutien pour cette initiative, l'analyse devrait être basée sur des faits et doit impliquer directement et être significative pour toutes les parties prenantes clés de la fiabilité de l'usine - production ; santé, sécurité et environnement (HSE); contrôle qualité (CQ); la finance; ingénierie; et le management. Cela allait être un exercice d'équilibre incroyable.
« N'importe qui peut sortir et extraire un tas de données », explique Lafever. « Nous avons dû décider d'où extraire les données, comment nous allions les extraire et déterminer si les données allaient nous indiquer les informations dont nous avions besoin pour prendre les bonnes décisions. »
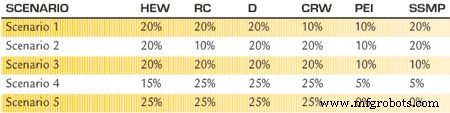
Tableau 1. Résumé des pondérations pour les cinq scénarios.
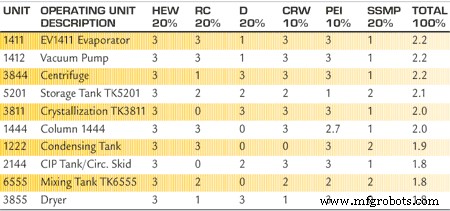
Tableau 2. Exemple de la première analyse de sensibilité du scénario.
Après plusieurs itérations - et "beaucoup de frictions", explique Lafever - l'équipe a finalisé une analyse qui a pris en compte les parties prenantes en utilisant les données existantes des 12 derniers mois. Ces données incluent :
1) Heures de travail d'urgence, assimilées à des temps d'arrêt de l'équipement, pour satisfaire la production. Cela a été collecté à partir du système informatisé de gestion de la maintenance de l'usine, qui enregistre toutes les heures imputées à chaque unité d'exploitation. Le travail d'urgence a été défini comme « un travail qui ne peut pas attendre ». Bien qu'il ne s'agisse pas d'une mesure traditionnelle des temps d'arrêt du système, cela est directement corrélé à la quantité de perturbations de la production ressentie lorsque le système ne fonctionnait pas correctement.
2) Classification des risques, selon la gestion globale de la sécurité des processus (GIPSM) de Lilly, pour satisfaire aux exigences HSE. Le système de classification a quatre possibilités :opération critique pour la sécurité, le principal facteur de risque; un risque élevé, qui implique des risques considérables pour l'environnement, la santé et l'incendie ; l'intégrité mécanique, qui est définie par l'Administration de la sécurité et de la santé au travail ; et aucun risque ou « aucun des éléments ci-dessus ».
3) Nombre d'écarts du processus causés par des pannes d'équipement pour satisfaire le CQ. Cela ciblait les écarts qui résultaient de problèmes de fiabilité de l'équipement, et non d'une erreur de l'opérateur ou d'autres problèmes non liés à l'équipement. Le nombre d'écarts a été pris en compte ainsi qu'un niveau (1, 2 ou 3) qui a identifié l'impact de l'écart sur la qualité du produit.
4) Coût du travail réactif pour satisfaire les finances. Cela a encore été tiré de la GMAO, qui suit toutes les charges budgétaires imputées aux unités opérationnelles. Ce coût comprenait toutes les pièces et la main-d'œuvre associées au travail réactif effectué sur le système.
5) Entrée d'ingénieur de processus pour satisfaire l'ingénierie. L'ingénieur de processus responsable de chaque système a été interrogé sur des sujets tels que l'âge du système, les heures de temps d'arrêt potentiels générés par une défaillance du système et l'impact réglementaire.
6) État du plan de maintenance du système, également pour satisfaire l'ingénierie. Cela a été conçu pour inclure quatre niveaux :niveau 1, aucun entretien de routine effectué, qui a été considéré comme le plus sévère; Niveau 2, une maintenance préventive existe sur le système ; Les évaluations de qualification périodiques (PQE) de niveau 3, conçues pour garantir que le système est dans un état constant de qualification et apte à être utilisé, sont exécutées ; et, niveau 4, une analyse basée sur le RCM a été utilisée sur le système pour générer un plan de maintenance.
Ces données ont créé une évaluation des « équipements essentiels » qui a examiné les 420 unités d'exploitation et a identifié celles qui pourraient soit arrêter la production, soit provoquer un incident à signaler par l'OSHA ou l'EPA.
« La façon dont notre structure est configurée dans notre GMAO et la façon dont nous contrôlons notre base de données d'incidents, l'unité opérationnelle était la meilleure voie à suivre », explique Lafever. « Parfois, une unité opérationnelle est un équipement. La plupart du temps, il s'agit d'un équipement majeur, et bien plus encore. »
Par exemple, Redchanskiy dit que l'unité d'exploitation EV1411 (processus d'évaporation) comprend « 50 à 60 pièces d'équipement et d'instrumentation, telles que des vannes, des échangeurs de chaleur et des pompes ».
L'évaluation a réduit la liste initiale de 70 %, passant de 420 unités opérationnelles à 135.
Les faits ne mentent pas
Quand il s'agit de déterminer l'importance d'une unité opérationnelle particulière, il est difficile d'argumenter avec les faits.
« Avant de faire cette analyse, tout ce dont la production parlait était la centrifugeuse sur la partie frontale », déclare Ken Swank, chef de l'équipe de maintenance et de fiabilité d'Eli Lilly. « Après l'analyse et leur avoir montré ce que nous avions trouvé – j'ai souligné que la centrifugeuse était classée 63e (sur la liste des 135 unités opérationnelles) – ils ne demandent pas grand-chose à ce sujet.
« Cela nous amène également à regarder en dehors de la définition de l'équipement de production. Avant l'analyse, les gens ont oublié d'inclure les réservoirs de déchets, les appareils de traitement de l'air, etc. Ils n'ont pas pensé au réservoir 1099 dans la salle de contrôle 2, où vont tous les drains de sol. La chasse d'eau passe par les drains et dans le réservoir. Si ce réservoir n'est pas opérationnel, nous devons arrêter nos étapes de purification."
Poids et mesures
Pour assurer une hiérarchisation appropriée des 135 unités restantes, le groupe a décidé d'appliquer une pondération à chaque source de données et a effectué une poignée d'analyses de sensibilité.
« Nous n'avons pas eu l'impression que les six critères étaient pondérés de la même manière », déclare Swank. « Nous avons estimé que la sécurité et la qualité avaient un impact plus important que, disons, le montant d'argent que nous dépensions pour des travaux de type urgence. »
Un système de notation (zéro à 3, zéro étant le moins d'impact et de gravité et 3 étant le plus d'impact et de gravité) a été développé pour chaque ensemble de données et appliqué à chaque unité opérationnelle. La répartition était la suivante :
Heures de travail d'urgence (HEW) :moins de 15 heures (score de zéro), 15 à moins de 25 heures (un), 25 à moins de 40 heures (deux) et 40 heures ou plus (trois).
Classification des risques (RC) :aucun risque HSE (zéro), système d'intégrité mécanique (un), processus à haut risque (deux) et opération critique pour la sécurité (trois).
Écarts (D) :Quatre regroupements ont été effectués en tenant compte des niveaux et des nombres d'écarts. Il a été déterminé qu'un écart de niveau 2 était égal à trois fois un écart de niveau 1 et un écart de niveau 3 était égal à deux fois un écart de niveau 2. Cela fait un écart de niveau 1 valant un point, un écart de niveau 2 valant trois points et un écart de niveau 3 valant six points. Cela a été appliqué à chaque écart. En conséquence, les valeurs étaient :deux ou moins (zéro), plus de deux à cinq (un), plus de cinq à huit (deux) et plus de huit (trois).
Coût du travail réactif (CRW) :moins de 5 000 $ (zéro), 5 000 $ à moins de 7 499 $ (un), 7 500 $ à 14 999 $ (deux) et 15 000 $ ou plus (trois).
Entrée de l'ingénieur de processus (PEI) :système d'impact minimal (zéro) et escalade jusqu'au système d'impact maximal (trois).
Plan de maintenance de l'état du système (SSMP) :analyse RCM effectuée sur le système (zéro), PQE exécuté sur une base de routine (un), PMs effectué (deux) et aucune maintenance de routine effectuée (trois).
Des scores ont été appliqués aux 135 unités opérationnelles. Les informations ont ensuite été chargées dans une feuille de calcul et diverses pondérations ont été appliquées pour souligner l'importance de divers ensembles de données. Le projet d'analyse de sensibilité comprenait cinq scénarios de pondération différents pour garantir qu'un seul point de données n'entraînait pas la priorisation d'un système.
Les scénarios variaient d'une distribution de poids assez uniforme (HEW, HSE, D et SSMP, 20 % chacun ; CRW et PEI, 10 % chacun) à l'élimination de deux catégories (HEW, HSE, D et CRW, 20 % chacun ; PEI et SSMP, zéro pour cent). Dans ce dernier scénario, les ensembles de données restants étaient de « vraies données » qui changeaient en fonction du niveau de fiabilité démontré par le système. Les scénarios sont présentés dans le tableau 1.
Chaque scénario de l'analyse de sensibilité a pris le facteur de risque et l'a multiplié par la pondération de ce scénario particulier. Le produit de chaque catégorie a été additionné pour chaque unité opérationnelle. Le tableau 2 montre un exemple du premier scénario.
Une fois les cinq scénarios terminés, les scores finaux des unités opérationnelles ont été représentés graphiquement et examinés par l'équipe de fiabilité. Avant de déterminer les classements finaux et les plans d'assainissement, d'autres facteurs ont été pris en compte. L'unité en question a-t-elle été remplacée récemment ou son remplacement est-il prévu dans le plan d'immobilisations ? Les plans d'assainissement de cette unité peuvent-ils être appliqués à d'autres unités ? Quels groupes fonctionnels sont nécessaires pour cette remédiation et sont-ils disponibles ? Quelles activités de remédiation ont été effectuées dans le passé ?
« Par exemple, l'une des centrifugeuses est arrivée en tête de liste, mais nous savions qu'un autre site effectuait un RCM sur un système très similaire », explique Swank. "Nous n'avons pas eu besoin de dupliquer les efforts."
La liste finale des activités d'assainissement proposées variait, selon l'unité d'exploitation, d'une analyse RCM approfondie à l'absence d'assainissement du système.
À ce stade, l'équipe savait qu'elle avait un plan complet.
« C'était une corvée », dit Lafever. « Nous avons élaboré un plan à trois reprises – cela semblait être 30 fois – et nous n'arrêtions pas de dire : « Ce n'est pas assez bon. » « Qu'en penserait le contrôle de la qualité à ce sujet ? « Qu'en penserait l'ingénierie des procédés ? » Nous étaient très perplexes. Nous devions nous assurer d'aborder toutes les facettes et toutes les questions potentielles. »
Swank ajoute:"Le premier coup de couteau était comme," Wow, ce n'est même pas proche. " Il est devenu évident pourquoi cela n'avait pas été fait avant. C'est beaucoup de travail. Il y a aussi des trucs du quotidien qui ne cessent de vous arracher à quelque chose comme ça. Mais nous nous sommes dit que nous allions nous en tenir à cela et le faire. »
Par écrit
Le 21 septembre 2004, Swank a officiellement présenté le modèle de priorisation à l'équipe principale de l'usine, qui comprend le responsable du site et tous les responsables fonctionnels. Les sept mois de travail épuisants ont porté leurs fruits.
« Il n’y a eu ni troc ni discussion dans les deux sens », dit-il. "Ils se disaient:" C'est génial. Continuez.’”
Bien sûr, un hochement de tête et un signe de la main ne vont pas loin. Ainsi, Swank a demandé à Lafever de créer un rapport qui résumait le processus d'évaluation et détaillait comment l'analyse cruciale de l'équipement serait effectuée année après année. Le rapport servirait de modèle pour les évaluations futures.
« J'ai dit aux membres de l'équipe principale de le signer », dit Swank. « Ils l'ont fait. Je l'ai par écrit. Il n'y avait aucune hésitation. Cela montre que l'analyse que nous avons faite était vraiment solide. »
Le 28 février 2005, l'analyse cruciale de l'équipement a été formalisée et approuvée par l'équipe principale, et les activités de remédiation pour les unités opérationnelles les plus vitales de l'usine ont été incluses dans les plans d'affaires 2005 et 2006 de l'usine.
Le modèle a rendu les évaluations ultérieures presque transparentes.
"L'année dernière, l'analyse a été un jeu d'enfant", déclare Lafever.
Le plan de 2006 a été achevé en mai.
Résultats de Remedy
Les responsables du service de maintenance et de fiabilité de cette usine d'Eli Lilly déclarent qu'ils ne sont actuellement pas en mesure de quantifier l'impact en dollars et en cents sur le résultat net de l'initiative de hiérarchisation de la fiabilité.
« Ce qui est malheureux, c'est que nous ne voyons pas toujours les résultats de notre travail année après année », déclare Lafever. "Il peut y avoir un an de retard, car cela prend du temps de travailler dans le système."
Mais cela ne veut pas dire qu'il n'y a pas eu d'avantages et de résultats.
Redchanskiy et Doyle disent qu'il y a des économies de coûts inévitables simplement en réévaluant la façon dont la maintenance est effectuée sur un actif donné.
"Lors de l'analyse, nous avons découvert que nous dépensions une somme d'argent considérable sur quelques systèmes qui n'avaient aucun travail réactif", explique Redchanskiy. « Nous avons dépensé une tonne en maintenance préventive. Nous en avons trop fait sur les MP. Nous avons changé la façon dont nous effectuions la maintenance de ces systèmes. »
« Le plus grand changement par rapport à cela est que pour certains systèmes, les gens peuvent désormais dire qu'il est en fait acceptable de fonctionner jusqu'à l'échec », explique Doyle. « Si tel est notre diagnostic et notre plan pour ce système particulier, tout va bien. C'est une toute autre philosophie pour nous. »
Swank dit que des points positifs peuvent être tirés des niveaux de productivité de l'usine.
"Le fait que nous ayons atteint nos niveaux de stocks et le fait que notre modèle d'entreprise évolue vers une productivité accrue montre que nous avons déjà atteint notre première étape importante", déclare-t-il.
Lafever pense que la participation à des projets de remédiation a permis d'améliorer les connaissances techniques et la disponibilité.
« Lorsque la plupart des personnes chargées de la maintenance et de l'exploitation sortent d'une analyse RCM, elles peuvent être classées comme des experts de ce système », dit-il. « Tout le monde a une meilleure compréhension des fonctions individuelles des groupes et de la façon dont ils travaillent ensemble pour effectuer leur part de réparation d'un équipement ou d'identification lorsqu'il y a un problème avec un équipement. Cette interaction elle-même, je pense, réduit la quantité de travail d'urgence qui se développe. »
Le meilleur indicateur de succès ?
« Cela rend notre haute direction heureuse », déclare Doyle.
« Et cela me rend heureux », déclare Swank.
Toutes ces améliorations pourraient expliquer pourquoi BHI a reçu le Making Medicine Award 2005, qui est décerné à l'usine Eli Lilly qui « répond le mieux aux besoins de l'entreprise et incarne ce que la fabrication est censée être dans l'entreprise ».
D'autres usines de Lilly prennent note de l'initiative de priorisation et examinent la faisabilité de l'adoption. Cela a conduit à une visibilité accrue à l'échelle de l'entreprise pour la maintenance et la fiabilité.
« Une partie du bien a été la compréhension et la sensibilisation de l'entreprise à la valeur ajoutée de la maintenance », déclare Reimer. « C'est quelque chose dont nous voulons vraiment profiter. »
Cette équipe démontre quotidiennement que les professionnels de la maintenance et de la fiabilité peuvent faire la différence.
Entretien et réparation d'équipement
- Étude de cas :Entraînements et rétrofits sur refendeuse-bobineuse de papeterie
- L'usine à pistons adopte une approche proactive de la fiabilité et de l'OEE
- Drew Troyer :L'impact des processus métier sur la fiabilité
- Comment la fiabilité de l'usine affecte une implémentation Lean
- La centrale hydroélectrique d'Hawaï augmente son efficacité et sa fiabilité
- Société saoudienne d'électricité pour améliorer la fiabilité de la centrale électrique
- Système sans fil pour augmenter la fiabilité de la centrale électrique du Nevada
- L'amélioration de la disponibilité va bien au-delà de la maintenance
- NV Energy installe une solution sans fil pour augmenter la fiabilité de l'usine