


Principes d'ingénierie de la fiabilité pour l'ingénieur d'usine

De plus en plus, les gestionnaires et les ingénieurs responsables de la fabrication et d'autres activités industrielles intègrent une approche axée sur la fiabilité dans leurs plans et initiatives stratégiques et tactiques. Cette tendance affecte de nombreux domaines fonctionnels, y compris la conception et l'approvisionnement des machines/systèmes, les opérations de l'usine et la maintenance de l'usine.
Avec ses origines dans l'industrie aéronautique, l'ingénierie de la fiabilité, en tant que discipline, s'est historiquement concentrée principalement sur la garantie de la fiabilité des produits. De plus en plus, ces méthodes sont utilisées pour assurer la fiabilité de la production des usines et des équipements de fabrication - souvent en tant que catalyseur de la production au plus juste. Cet article fournit une introduction à la plus pertinente et la plus pratique de ces méthodes pour l'ingénierie de la fiabilité des installations, notamment :
- Calculs de fiabilité de base pour le taux de défaillance, le MTBF, la disponibilité, etc.
- Une introduction à la distribution exponentielle - la pierre angulaire des méthodes de fiabilité.
- Identification des dépendances de temps de défaillance à l'aide du système polyvalent Weibull.
- Développer un système efficace de collecte de données sur le terrain.
Historique de l'ingénierie de fiabilité
Les origines du domaine de l'ingénierie de la fiabilité, du moins la demande, remontent au moment où l'homme a commencé à dépendre des machines pour sa subsistance. La Noria, par exemple, est une ancienne pompe considérée comme la première machine sophistiquée au monde. Utilisant l'énergie hydraulique provenant du débit d'une rivière ou d'un ruisseau, le Noria utilisait des seaux pour transférer l'eau vers des auges, des viaducs et d'autres dispositifs de distribution pour irriguer les champs et fournir de l'eau aux communautés.
Si la communauté de Noria échouait, les personnes qui en dépendaient pour leur approvisionnement en nourriture étaient en danger. La survie a toujours été une grande source de motivation pour la fiabilité et la fiabilité.
Bien que les origines de sa demande soient anciennes, l'ingénierie de la fiabilité en tant que discipline technique a véritablement prospéré avec la croissance de l'aviation commerciale après la Seconde Guerre mondiale. Il est rapidement devenu évident pour les dirigeants d'entreprises de l'industrie aéronautique que les accidents sont mauvais pour les affaires. Karen Bernowski, éditrice de Quality Progress , révélé dans l'une de ses recherches éditoriales sur la valeur médiatique de la mort par divers moyens, qui a été menée par le professeur de statistique du MIT Arnold Barnett et rapportée en 1994.
Barnett a évalué le nombre d'articles de presse en première page du New York Times pour 1 000 décès par divers moyens. Il a découvert que les décès liés au cancer ont généré 0,02 articles de presse en première page pour 1 000 décès, les homicides ont généré 1,7 pour 1 000 décès, le SIDA 2,3 pour 1 000 décès et les accidents liés à l'aviation ont généré un énorme 138,2 articles pour 1 000 décès !
Le coût et la nature très médiatisée des accidents liés à l'aviation ont contribué à motiver l'industrie aéronautique à participer fortement au développement de la discipline de l'ingénierie de la fiabilité. De même, en raison de la nature critique des équipements militaires pour la défense, des techniques d'ingénierie de fiabilité sont utilisées depuis longtemps pour assurer la disponibilité opérationnelle. Bon nombre de nos normes dans le domaine de l'ingénierie de fiabilité sont des normes MIL ou ont leur origine dans des activités militaires.
Qu'est-ce que l'ingénierie de fiabilité ?
L'ingénierie de la fiabilité traite de la longévité et de la fiabilité des pièces, des produits et des systèmes. Plus poignant, il s'agit de contrôler le risque. L'ingénierie de la fiabilité intègre une grande variété de techniques analytiques conçues pour aider les ingénieurs à comprendre les modes de défaillance et les modèles de ces pièces, produits et systèmes. Traditionnellement, le domaine de l'ingénierie de la fiabilité s'est concentré sur la fiabilité des produits et l'assurance de la fiabilité.
Ces dernières années, les organisations qui déploient des machines et d'autres actifs physiques dans des environnements de production ont commencé à déployer divers principes d'ingénierie de fiabilité à des fins de fiabilité de production et d'assurance de la fiabilité.
De plus en plus, les organisations de production déploient des techniques d'ingénierie de fiabilité telles que la maintenance centrée sur la fiabilité (RCM), y compris l'analyse des modes de défaillance et des effets (et de la criticité) (FMEA, AMDEC), l'analyse des causes profondes (RCA), la maintenance conditionnelle, des schémas de planification du travail améliorés, etc. Ces mêmes organisations commencent à adopter des stratégies de conception et d'approvisionnement basées sur les coûts du cycle de vie, des programmes de gestion du changement et d'autres outils et techniques avancés afin de contrôler les causes profondes d'une mauvaise fiabilité.
Cependant, l'adoption des aspects plus quantitatifs de l'ingénierie de la fiabilité par la communauté de l'assurance de la fiabilité de la production a été lente. Cela est dû en partie à la complexité perçue des techniques et en partie à la difficulté d'obtenir des données utiles.
Les aspects quantitatifs de l'ingénierie de la fiabilité peuvent, à première vue, sembler compliqués et intimidants. En réalité, cependant, une compréhension relativement basique des méthodes les plus fondamentales et les plus largement applicables peut permettre à l'ingénieur en fiabilité de l'usine d'acquérir une compréhension beaucoup plus claire de l'endroit où les problèmes se produisent, de leur nature et de leur impact sur le processus de production - au moins dans le domaine quantitatif. sens.
Utilisés correctement, les outils et méthodes d'ingénierie de fiabilité quantitative permettent à l'ingénierie de fiabilité de la centrale d'appliquer plus efficacement les cadres fournis par RCM, RCA, etc., en éliminant certaines des conjectures impliquées dans leur application autrement. Cependant, les ingénieurs doivent être particulièrement habiles dans leur application des méthodes.
Pourquoi? Le contexte opérationnel et l'environnement d'un processus de production intègrent plus de variables que le monde quelque peu unidimensionnel de l'assurance de la fiabilité des produits. Cela est dû à l'influence combinée de l'ingénierie de conception, des achats, de la production/des opérations, de la maintenance, etc., et de la difficulté à créer des tests et des expériences efficaces pour modéliser les aspects multidimensionnels d'un environnement de production typique.
Malgré la difficulté accrue d'appliquer les méthodes de fiabilité quantitative dans l'environnement de production, il est néanmoins intéressant d'acquérir une bonne compréhension des outils et de les appliquer le cas échéant. Les données quantitatives aident à définir la nature et l'ampleur d'un problème/d'une opportunité, ce qui donne une vision de la fiabilité dans son application d'autres outils d'ingénierie de fiabilité.
Cet article fournira une introduction aux méthodes d'ingénierie de fiabilité les plus élémentaires applicables à l'ingénieur d'usine qui s'intéresse à l'assurance de la fiabilité de la production. Cela présuppose une compréhension de base de l'algèbre, de la théorie des probabilités et des statistiques univariées basées sur la distribution gaussienne (normale) (par exemple, mesure de la tendance centrale, mesures de la dispersion et de la variabilité, intervalles de confiance, etc.).
Il convient de préciser que cet article est une brève introduction aux méthodes de fiabilité. Il ne s'agit en aucun cas d'une étude complète des méthodes d'ingénierie de la fiabilité, et ce n'est en aucun cas nouveau ou non conventionnel. Les méthodes décrites ici sont couramment utilisées par les ingénieurs en fiabilité et constituent des concepts de connaissances de base pour ceux qui souhaitent obtenir une certification professionnelle par l'American Society for Quality (ASQ) en tant qu'ingénieur en fiabilité (CRE).
Plusieurs livres sur l'ingénierie de la fiabilité sont répertoriés dans la bibliographie de cet article. L'auteur de cet article a trouvé des Méthodes de fiabilité pour les ingénieurs par K.S. Krishnamoorthi et Statistiques de fiabilité par Robert Dovich pour être des références particulièrement utiles et conviviales sur le sujet des méthodes d'ingénierie de la fiabilité. Tous deux sont publiés par la Presse ASQ.
Avant de discuter des méthodes, vous devez vous familiariser avec la nomenclature de l'ingénierie de fiabilité. Pour plus de commodité, une liste très abrégée de termes et définitions clés est fournie en annexe de cet article. Pour une définition plus exhaustive des termes et de la nomenclature de fiabilité, reportez-vous à MIL-STD-721 et à d'autres normes connexes. Les définitions contenues dans l'annexe proviennent de MIL-STD-721.
Concepts mathématiques de base en ingénierie de la fiabilité
De nombreux concepts mathématiques s'appliquent à l'ingénierie de la fiabilité, en particulier dans les domaines des probabilités et des statistiques. De même, de nombreuses distributions mathématiques peuvent être utilisées à diverses fins, notamment la distribution gaussienne (normale), la distribution log-normale, la distribution de Rayleigh, la distribution exponentielle, la distribution de Weibull et bien d'autres.
Pour les besoins de cette brève introduction, nous limiterons notre discussion à la distribution exponentielle et à la distribution de Weibull, les deux plus largement appliquées à l'ingénierie de la fiabilité. Par souci de concision et de simplicité, des concepts mathématiques importants tels que la qualité de l'ajustement de la distribution et les intervalles de confiance ont été exclus.
Taux d'échec et temps moyen entre/jusqu'à l'échec (MTBF/MTTF)
Le but des mesures de fiabilité quantitatives est de définir le taux de défaillance par rapport au temps et de modéliser ce taux de défaillance dans une distribution mathématique dans le but de comprendre les aspects quantitatifs de la défaillance. Le bloc de construction le plus fondamental est le taux d'échec, qui est estimé à l'aide de l'équation suivante :

Où :
λ =Taux d'échec (parfois appelé taux de risque)
T =Temps de fonctionnement total/cycles/miles/etc. pendant une période d'enquête pour les articles échoués et non échoués.
r =Le nombre total de défaillances survenues au cours de la période d'enquête.
Par exemple, si cinq moteurs électriques fonctionnent pendant une durée totale collective de 50 ans avec cinq pannes fonctionnelles au cours de la période, le taux de panne est de 0,1 panne par an.
Un autre concept très basique est le temps moyen entre/jusqu'à défaillance (MTBF/MTTF). La seule différence entre le MTBF et le MTTF est que nous utilisons le MTBF lorsque nous nous référons aux éléments qui sont réparés lorsqu'ils tombent en panne. Pour les articles qui sont simplement jetés et remplacés, nous utilisons le terme MTTF. Les calculs sont les mêmes.
Le calcul de base pour estimer le temps moyen entre défaillance (MTBF) et le temps moyen avant défaillance (MTTF), deux mesures de la tendance centrale, est simplement l'inverse de la fonction de taux de défaillance. Il est calculé à l'aide de l'équation suivante.

Où :
θ =Temps moyen entre/jusqu'à la panne
T =Temps de fonctionnement total/cycles/miles/etc. pendant une période d'enquête pour les articles échoués et non échoués.
r =Le nombre total de défaillances survenues au cours de la période d'enquête.
Le MTBF de notre exemple de moteur électrique industriel est de 10 ans, ce qui est l'inverse du taux de défaillance des moteurs. Incidemment, nous estimerions le MTBF pour les moteurs électriques qui sont reconstruits en cas de panne. Pour les moteurs plus petits qui sont considérés comme jetables, nous indiquerions la mesure de tendance centrale comme MTTF.
Le taux de défaillance est un élément de base de nombreux calculs de fiabilité plus complexes. Selon la conception mécanique/électrique, le contexte d'exploitation, l'environnement et/ou l'efficacité de la maintenance, le taux de défaillance d'une machine en fonction du temps peut diminuer, rester constant, augmenter linéairement ou augmenter géométriquement (Figure 1). L'importance du taux d'échec par rapport au temps sera discutée plus en détail plus tard.
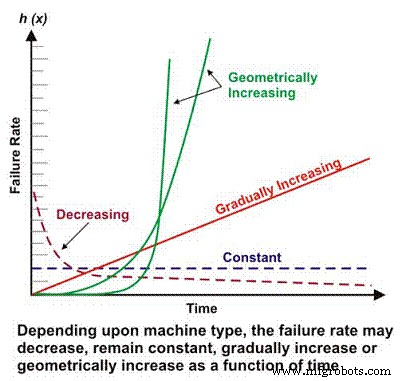
Figure 1. Différents taux d'échec en fonction des scénarios temporels
La courbe « Baignoire »
Les personnes qui n'ont reçu qu'une formation de base en probabilités et statistiques sont probablement plus familières avec la distribution gaussienne ou normale, qui est associée à la courbe de densité de probabilité en forme de cloche familière. La distribution gaussienne est généralement applicable aux ensembles de données où les deux mesures les plus courantes de tendance centrale, moyenne et médiane, sont approximativement égales.
Étonnamment, malgré la polyvalence de la distribution gaussienne dans la modélisation des probabilités de phénomènes allant des résultats des tests standardisés aux poids de naissance des bébés, ce n'est pas la distribution dominante utilisée dans l'ingénierie de la fiabilité. La distribution gaussienne a sa place dans l'évaluation des caractéristiques de défaillance des machines avec un mode de défaillance dominant, mais la principale distribution utilisée en ingénierie de fiabilité est la distribution exponentielle.
Lors de l'évaluation de la fiabilité et des caractéristiques de défaillance d'une machine, nous devons commencer par la courbe de la « baignoire », qui reflète le taux de défaillance en fonction du temps (Figure 2). Dans le concept, la courbe de la baignoire démontre efficacement les trois caractéristiques de base du taux de défaillance d'une machine :en déclin, constant ou en augmentation. Malheureusement, la courbe de la baignoire a été sévèrement critiquée dans la littérature technique de maintenance car elle ne parvient pas à modéliser efficacement le taux de défaillance caractéristique de la plupart des machines d'une installation industrielle, ce qui est généralement vrai au niveau macro.
La plupart des machines passent leur vie dans la petite enfance, ou la mortalité infantile, et/ou les régions à taux de défaillance constant de la courbe de la baignoire. Nous voyons rarement des défaillances systémiques basées sur le temps dans les machines industrielles. Malgré ses limites dans la modélisation des taux de défaillance des machines industrielles typiques, la courbe de la baignoire est un outil utile pour expliquer les concepts de base de l'ingénierie de la fiabilité.
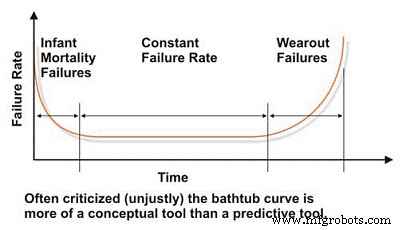
Figure 2. La courbe de la « baignoire » tant décriée
Le corps humain est un excellent exemple d'un système qui suit la courbe de la baignoire. Les gens, et d'autres espèces organiques d'ailleurs, ont tendance à souffrir d'un taux d'échec (mortalité) élevé au cours de leurs premières années de vie, en particulier les premières années, mais le taux diminue à mesure que l'enfant grandit. En supposant qu'une personne atteigne la puberté et survive à son adolescence, son taux de mortalité devient assez constant et y reste jusqu'à ce que les maladies liées à l'âge (temps) commencent à augmenter le taux de mortalité (usure).
De nombreuses influences affectent les taux de mortalité, notamment les soins prénatals et la nutrition de la mère, la qualité et la disponibilité des soins médicaux, l'environnement et la nutrition, les choix de mode de vie et, bien sûr, la prédisposition génétique. Ces facteurs peuvent être métaphoriquement comparés aux facteurs qui influencent la durée de vie de la machine. La conception et l'approvisionnement sont analogues à la prédisposition génétique ; l'installation et la mise en service sont analogues aux soins prénatals et à l'alimentation de la mère ; et les choix de mode de vie et la disponibilité des soins médicaux sont analogues à l'efficacité de la maintenance et au contrôle proactif des conditions d'exploitation.
La distribution exponentielle
La distribution exponentielle, la formule de prédiction de fiabilité la plus basique et la plus largement utilisée, modélise les machines avec un taux de défaillance constant ou la section plate de la courbe de la baignoire. La plupart des machines industrielles passent la majeure partie de leur vie dans un taux de défaillance constant, elle est donc largement applicable. Vous trouverez ci-dessous l'équation de base pour estimer la fiabilité d'une machine qui suit la distribution exponentielle, où le taux de défaillance est constant en fonction du temps.

Où :
R(t) =Estimation de la fiabilité pour une période de temps, cycles, kilomètres, etc. (t).
e =Base des logarithmes népérien (2.718281828)
λ =Taux d'échec (1/MTBF, ou 1/MTTF)
Dans notre exemple de moteur électrique, si vous supposez un taux de défaillance constant, la probabilité de faire fonctionner un moteur pendant six ans sans défaillance, ou la fiabilité prévue, est de 55 %. Ceci est calculé comme suit :
R(6) =2,718281828-(0,1* 6)
R(6) =0,5488 =~ 55%
En d'autres termes, après six ans, environ 45 % de la population de moteurs identiques fonctionnant dans une application identique peuvent vraisemblablement tomber en panne. Il vaut la peine de répéter à ce stade que ces calculs projettent la probabilité pour une population. N'importe quel individu de la population pourrait échouer le premier jour de l'opération alors qu'un autre individu pourrait durer 30 ans. C'est la nature des projections de fiabilité probabilistes.
Une caractéristique de la distribution exponentielle est que le MTBF se produit au point auquel la fiabilité calculée est de 36,78 %, ou au point auquel 63,22 % des machines sont déjà tombées en panne. Dans notre exemple de moteur, après 10 ans, on peut s'attendre à ce que 63,22 % des moteurs d'une population de moteurs identiques servant dans des applications identiques tombent en panne. En d'autres termes, le taux de survie est de 36,78 % de la population.
Nous parlons souvent de la durée de vie projetée des roulements comme de la durée de vie L10. C'est le moment auquel 10 % d'une population de roulements devraient tomber en panne (taux de survie de 90 %). En réalité, seule une fraction des roulements survit au point L10. Nous en sommes venus à accepter cela comme la durée de vie objective d'un roulement alors que nous devrions peut-être viser le point L63.22, indiquant que nos roulements durent, en moyenne, jusqu'au MTBF projeté - en supposant, bien sûr, que les roulements suivre la distribution exponentielle. Nous discuterons de ce problème plus tard dans la section d'analyse Weibull de l'article.
La fonction de densité de probabilité (pdf), ou distribution de durée de vie, est une équation mathématique qui se rapproche de la distribution de fréquence de défaillance. C'est la pdf, ou distribution de fréquence de vie, qui donne la courbe en forme de cloche familière dans la distribution gaussienne, ou normale. Ci-dessous se trouve le pdf pour la distribution exponentielle.

Où :
pdf(t) =Distribution de fréquence de vie pour un temps donné (t)
e =Base des logarithmes népérien (2.718281828)
λ =Taux d'échec (1/MTBF, ou 1/MTTF)
Dans notre exemple de moteur électrique, la probabilité réelle de panne à trois ans est calculée comme suit :
pdf(3) =01. * 2.718281828-(0.1* 3)
pdf(3) =0,1 * 0,7408
pdf(3) =.07408 =~ 7.4%
Dans notre exemple, si nous supposons un taux de défaillance constant, qui suit la distribution exponentielle, la distribution de la durée de vie, ou pdf pour les moteurs électriques industriels, est exprimée dans la figure 3. Ne soyez pas confus par la nature décroissante de la fonction pdf. Oui, le taux d'échec est constant, mais le pdf suppose mathématiquement un échec sans remplacement, de sorte que la population à partir de laquelle des échecs peuvent se produire diminue continuellement - approchant asymptotiquement de zéro.
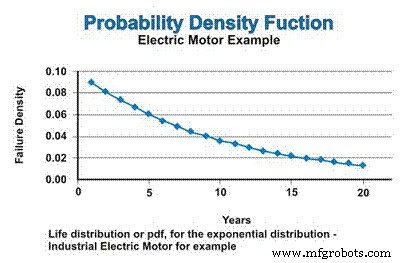
Figure 3. La fonction de densité de probabilité (pdf)
La fonction de distribution cumulative (cdf) est simplement le nombre cumulé de défaillances auquel on peut s'attendre sur une période de temps. Pour la distribution exponentielle, le taux de défaillance est constant, de sorte que le taux relatif auquel les composants défaillants sont ajoutés à la fonction cdf reste constant. Cependant, à mesure que la population diminue en raison d'une défaillance, le nombre réel de défaillances estimées mathématiquement diminue en fonction du déclin de la population. Tout comme le pdf s'approche asymptotiquement de zéro, le cdf s'approche asymptotiquement de un (Figure 4).
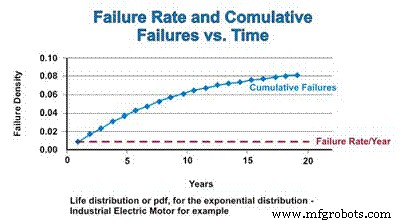
Figure 4. Taux d'échec et fonction de distribution cumulative
La partie décroissante du taux d'échec de la courbe de la baignoire, souvent appelée région de mortalité infantile, et la région d'usure seront discutées dans la section suivante traitant de la distribution polyvalente de Weibull.
Répartition Weibull
Développée à l'origine par Wallodi Weibull, un mathématicien suédois, l'analyse de Weibull est de loin la distribution la plus polyvalente utilisée par les ingénieurs en fiabilité. Bien que cela s'appelle une distribution, il s'agit en fait d'un outil qui permet à l'ingénieur de fiabilité de caractériser d'abord la fonction de densité de probabilité (distribution de fréquence de défaillance) d'un ensemble de données de défaillance pour caractériser les défaillances comme une durée de vie précoce, constante (exponentielle) ou usée. (Gaussien ou log normal) en traçant les données de temps jusqu'à la défaillance sur un papier de traçage spécial avec le journal des temps/cycles/miles jusqu'à la défaillance tracé un axe X à l'échelle du journal par rapport au pourcentage cumulé de la population représentée par chaque défaillance sur un journal -axe Y à l'échelle logarithmique (Figure 5).
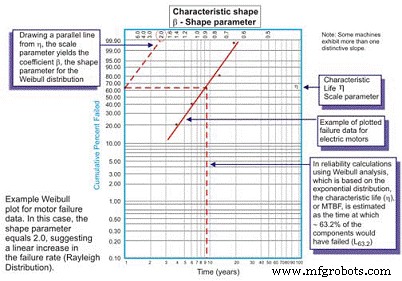
Figure 5. Le tracé simple de Weibull – annoté
Une fois tracée, la pente linéaire de la courbe résultante est une variable importante, appelée paramètre de forme, représentée par â, qui est utilisée pour ajuster la distribution exponentielle pour s'adapter à un grand nombre de distributions de défaillance. En général, si le coefficient â, ou paramètre de forme, est inférieur à 1,0, la distribution présente des échecs de mortalité précoce ou infantile. Si le paramètre de forme dépasse environ 3,5, les données dépendent du temps et indiquent des défaillances d'usure.
Cet ensemble de données suppose généralement la distribution gaussienne ou normale. À mesure que le coefficient â augmente au-dessus de ~ 3,5, la distribution en forme de cloche se resserre, présentant un kurtosis croissant (point culminant en haut de la courbe) et un écart type plus petit. De nombreux ensembles de données présenteront deux, voire trois régions distinctes.
Il est courant pour les ingénieurs de fiabilité de tracer, par exemple, une courbe représentant le paramètre de forme pendant le rodage et une autre courbe pour représenter le taux de défaillance constant ou augmentant progressivement. Dans certains cas, une troisième pente linéaire distincte émerge pour identifier une troisième forme, la région d'usure.
Dans ces cas, le pdf des données de défaillance prend en fait la forme familière de la courbe de la baignoire (figure 6). Cependant, la plupart des équipements mécaniques utilisés dans les usines présentent une région de mortalité infantile et une région de taux de défaillance constant ou augmentant progressivement. Il est rare de voir émerger une courbe représentant l'usure. La durée de vie caractéristique, ou (en minuscule grec « Eta »), est l'approximation de Weibull du MTBF. C'est toujours la fonction du temps, des kilomètres ou des cycles où 63,21% des unités évaluées ont échoué, qui est le MTBF/MTTF pour la distribution exponentielle.
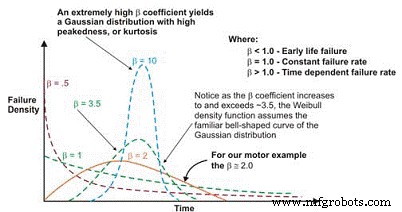
Figure 6. Selon le paramètre de forme, la densité de défaillance Weibull La courbe peut assumer plusieurs distributions, ce qui la rend si polyvalente pour l'ingénierie de fiabilité.
En guise de mise en garde pour lier cet outil à l'excellence dans la maintenance et l'excellence des opérations, si nous devions contrôler plus efficacement les fonctions de forçage qui conduisent à une défaillance mécanique des roulements, des engrenages, etc., telles que la lubrification, le contrôle de la contamination, l'alignement, l'équilibre, fonctionnement approprié, etc., davantage de machines atteindraient en fait leur durée de vie en fatigue. Les machines qui atteignent leur durée de vie en fatigue présenteront la caractéristique d'usure familière.
L'utilisation du coefficient β pour ajuster l'équation du taux de défaillance en fonction du temps donne l'équation générale suivante :

Où :
h(t) =Taux d'échec (ou taux de hasard) pour un temps donné (t)
e =Base des logarithmes naturels (2.718281828)
θ =MTBF/MTTF estimé
β =Paramètre de forme de Weibull à partir du tracé.
Et, la fonction de fiabilité suivante :
Où :
R(t) =Estimation de la fiabilité pour une période de temps, cycles, kilomètres, etc. (t)
e =Base des logarithmes naturels (2.718281828)
θ =MTBF/MTTF estimé
β =Paramètre de forme de Weibull à partir du tracé.
Et, la fonction de densité de probabilité suivante (pdf) :
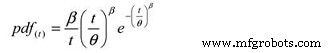
Où :
pdf(t) =Estimation de la fonction de densité de probabilité pour une période de temps,
cycles, miles, etc. (t)
e =Base des logarithmes naturels (2.718281828)
θ =MTBF/MTTF estimé
β =Paramètre de forme de Weibull à partir du tracé.
Il convient de noter que lorsque le est égal à 1,0, la distribution de Weibull prend la forme de la distribution exponentielle sur laquelle elle est basée.
Pour les non-initiés, les mathématiques requises pour effectuer une analyse de Weibull peuvent sembler intimidantes. Mais une fois que vous comprenez la mécanique des formules, le calcul est vraiment assez simple. De plus, le logiciel fera la plupart du travail pour nous aujourd'hui, mais il est important de comprendre la théorie sous-jacente afin que l'ingénieur en fiabilité de l'usine puisse déployer efficacement la puissante technique d'analyse de Weibull.
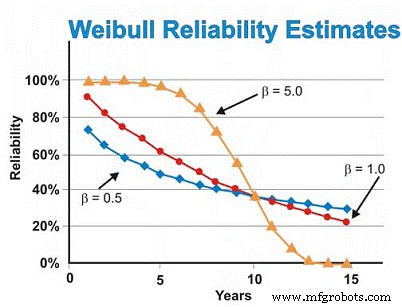
Dans notre exemple de moteurs électriques discuté précédemment, nous avons précédemment supposé la distribution exponentielle. Cependant, si l'analyse de Weibull révélait des défaillances précoces en produisant un paramètre de forme de 0,5, l'estimation de la fiabilité à six ans serait d'environ 46 %, et non d'environ 55 % estimé en supposant la distribution exponentielle. Afin de réduire les défaillances d'usure, nous aurions besoin de nous appuyer sur nos fournisseurs pour fournir une qualité et une fiabilité mieux construites et livrées, mieux stocker les moteurs pour éviter la rouille, la corrosion, le fretting et d'autres mécanismes d'usure statique, et faire un meilleur travail d'installation et démarrer des machines neuves ou reconstruites.
Inversement, si l'analyse de Weibull révélait que les moteurs présentaient principalement des défaillances liées à l'usure, donnant un paramètre de forme de 5,0, l'estimation de la fiabilité à six ans serait d'environ 93 %, au lieu des ~ 55 % estimés en supposant la distribution exponentielle. Pour les défaillances d'usure dépendantes du temps, nous pouvons effectuer une révision ou un remplacement programmé en supposant que nous ayons une bonne estimation du MTBF/MTTF après avoir atteint la région d'usure et un écart type suffisamment petit pour prendre des décisions de reconstruction/remplacement de confiance élevées qui ne sont pas excessivement coûteux.
Dans notre exemple de moteur, en supposant un paramètre de forme de 5,0, le taux de défaillance commence à augmenter rapidement après environ cinq ou six ans, nous pouvons donc vouloir modifier nos données pour nous concentrer uniquement sur la région d'usure lors de l'estimation du remplacement ou de la reconstruction en fonction du temps. temps. Alternativement, nous pouvons améliorer la conception, en ciblant le(s) mode(s) de défaillance dominant(s) dans le but de diminuer les interférences « contrainte-résistance ». En d'autres termes, nous pouvons tenter d'éliminer les fragilités de la machine en modifiant la conception, le but étant d'éliminer ce qui cause les défaillances temporelles.
En supposant que tout est constant, à l'exception du paramètre de forme , la figure 7 illustre la différence que le paramètre de forme a sur l'estimation de la fiabilité en supposant des valeurs de forme de 0,5 (début de vie), 1,0 (constant ou exponentiel) et 5,0 (usure) pour une plage d'estimations de temps. Ce graphique illustre visuellement le concept d'augmentation du risque en fonction du temps (β =0,5), du risque constant en fonction du temps (β =1,0) et de l'augmentation du risque en fonction du temps (β =5).
Figure 7. Diverses projections de fiabilité en fonction du temps pour différents Paramètres de forme Weibull
Le tracé de Weibull à plusieurs pentes
Fréquemment, lors du tracé d'une ligne de régression la mieux ajustée à travers les points de données sur un graphique de Weibull, le coefficient de corrélation est faible, ce qui signifie que les points de données réels s'éloignent beaucoup de la ligne de régression. Ceci est évalué en examinant le coefficient de corrélation R, ou plus prudemment, R2, qui dénote la variabilité des données. Lorsque la corrélation est faible, l'ingénieur de fiabilité doit examiner les données pour évaluer s'il existe deux modèles ou plus, ce qui peut dénoter des différences majeures dans les modes de défaillance, le contexte de fonctionnement, etc. Cela produit souvent deux ou plusieurs estimations de bêta (Figure 8).
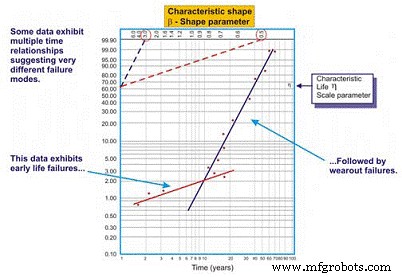
Figure 8. Exemple de tracé Weibull multi-bêta
Comme nous le voyons dans notre exemple de la figure 8, l'ensemble de données fonctionne mieux lorsque deux droites de régression distinctes sont tracées. La première ligne présente un paramètre de forme bêta de 0,5, suggérant des échecs en début de vie. La deuxième ligne présente une forme bêta de 3,0, suggérant que le risque d'échec augmente en fonction du temps. Il est courant que des équipements complexes, en particulier des équipements mécaniques, subissent des défaillances de « rodage » lorsqu'ils sont neufs ou récemment reconstruits. En tant que tel, le risque d'échec est le plus élevé juste après le démarrage initial.
Une fois que le système fonctionne pendant sa période de rodage, qui peut prendre des minutes, des heures, des jours, des semaines, des mois ou des années, selon le type de système, le système entre dans un schéma de risque différent. Dans cet exemple, le système entre dans une période où le risque de panne augmente en fonction du temps une fois que le système sort de sa période de rodage.
Le multi-bêta offre à l'ingénieur fiabilité une estimation plus précise du risque en fonction du temps. Armé de ces connaissances, il ou elle est mieux placé pour prendre des mesures d'atténuation. Par exemple, au début de la vie, nous serions enclins à améliorer la précision avec laquelle nous fabriquons/reconstruisons, installons et mettons en service. De plus, nous pourrions ajouter des techniques de surveillance et/ou augmenter notre fréquence de surveillance pendant la période à haut risque. Après la période de rodage, nous pourrions introduire des techniques de surveillance qui ciblent les défaillances d'usure dépendant du temps qui sont censées affecter le système, augmenter la fréquence de surveillance en conséquence ou planifier des actions de maintenance préventive « difficiles » dans certains cas.
Estimation de la fiabilité du système
Une fois la fiabilité des composants ou des machines établie par rapport au contexte d'exploitation et au temps de mission requis, les ingénieurs d'usine doivent évaluer la fiabilité d'un système ou d'un procédé. Encore une fois, par souci de concision et de simplicité, nous discuterons des estimations de fiabilité du système pour les systèmes redondants en série, en parallèle et à charge partagée (systèmes r/n).
Systèmes de série
Avant d'aborder les systèmes en série, parlons des schémas fonctionnels de fiabilité. Pas un outil compliqué à utiliser, les diagrammes de fiabilité cartographient simplement un processus du début à la fin. Pour un système en série, le sous-système A est suivi du sous-système B et ainsi de suite. Dans le système en série, la possibilité d'utiliser le sous-système B dépend de l'état de fonctionnement du sous-système A. Si le sous-système A ne fonctionne pas, le système est en panne quel que soit l'état du sous-système B (Figure 9).
To calculate the system reliability for a serial process, you only need to multiply the estimated reliability of Subsystem A at time (t) by the estimated reliability of Subsystem B at time (t). The basic equation for calculating the system reliability of a simple series system is:
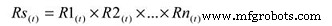
Where:
Rs(t) – System reliability for given time (t)
R1-n(t) – Subsystem or sub-function reliability for given time (t)
So, for a simple system with three subsystems, or sub-functions, each having an estimated reliability of 0.90 (90%) at time (t), the system reliability is calculated as 0.90 X 0.90 X 0.90 =0.729, or about 73%.
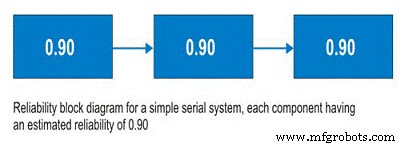
Figure 9. Simple Serial System
Parallel Systems
Often, design engineers will incorporate redundancy into critical machines. Reliability engineers call these parallel systems. These systems may be designed as active parallel systems or standby parallel systems. The block diagram for a simple two component parallel system is shown in Figure 10.
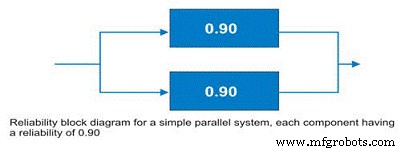
Figure 10. Simple parallel system – the system reliability is increased to 99% due to the redundancy.
To calculate the reliability of an active parallel system, where both machines are running, use the following simple equation:
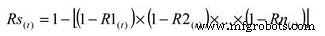
Where:
Rs(t) – System reliability for given time (t)
R1-n(t) – Subsystem or sub-function reliability for given time (t)
The simple parallel system in our example with two components in parallel, each having a reliability of 0.90, has a total system reliability of 1 – (0.1 X 0.1) =0.99. So, the system reliability was significantly improved.
There are some shortcut methods for calculating parallel system reliability when all subsystems have the same estimated reliability. More often, systems contain parallel and serial subcomponents as depicted in Figure 11. The calculation of standby systems requires knowledge about the reliability of the switching mechanism. In the interest of simplicity and brevity, this topic will be reserved for a future article.
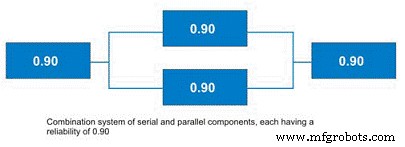
Figure 11. Combination System with Parallel and Serial Elements
r out of n Systems (r/n Systems)
An important concept to plant reliability engineers is the concept of r/n systems. These systems require that r units from a total population in n be available for use. A great industrial example is coal pulverizers in an electric power generating plant. Often, the engineers design this function in the plant using an r/n approach. For instance, a unit has four pulverizers and the unit requires that three of the four be operable to run at the unit’s full load (see Figure 12).
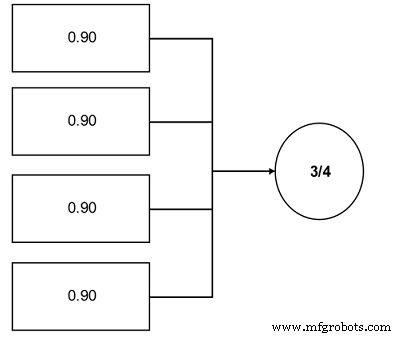
Figure 12. Simple r/n system example – Three of the four components are required.
The reliability calculation for an r/n system can be reduced to a simple cumulative binomial distribution calculation, the formula for which is:
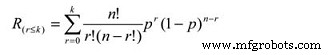
Where:
Rs =System reliability given the actual number of failures (r) is less than or equal the maximum allowable (k)
r =The actual number of failures
k =The maximum allowable number of failures
n =The total number of units in the system
p =The probability of survival, or the subcomponent reliability for a given time (t).
This equation is somewhat more complicated. In our pulverizer example, assuming a subcomponent reliability of 0.90, the equation works out as a summation of the following:
P(0) =0.6561
P(1) =0.2916
So, the likelihood of completing the mission time (t) is 0.9477 (0.6561 + 0.2916), or approximately 95%.
Field Data Collection
To employ the reliability analysis methods described herein, the engineer requires data. It is imperative to establish field data collection systems to support your reliability management initiatives. Likewise, as much as possible, you’ll want to employ common nomenclature and units so that your data can be parsed effectively for more detailed analysis. Collect the following information:
- Basic System Information
- Operating Context
- Environmental Context
- Failure Data
A good general system for data collection is described in the IEC standard 300-3-2. In addition to providing instructions for collecting field data, it provides a standard taxonomy of failure modes. Other taxonomies have been established, but the IEC standard represents a good starting point for your organization to define its own. Likewise, DOE standard NE-1004-92 offers a very nice standard nomenclature of failure causes.
An important benefit derived from your efforts to collect good field data is that it enables you to break the “random trap.” As I mentioned earlier, the bathtub curve has been much maligned – particularly in the Reliability-Centered Maintenance literature. While it’s true that Weibull analysis reveals that few complex mechanical systems exhibit time-dependent wearout failures, the reason, at least in part, is due to the fact that the reliability of complex systems is affected by a wide variety of failure modes and mechanisms.
When these are lumped together, there is a “randomizing” effect, which makes the failures appear to lack any time dependency. However, if the failure modes were analyzed individually, the story would likely be very different (Figure 13). For certain, some failure modes would still be mathematically random, but many, and arguably most, would exhibit a time dependency. This kind of information would arm reliability engineers and managers with a powerful set of options for mitigating failure risk with a high degree of precision. Naturally, this ability depends upon the effective collection and subsequent analysis of field data.
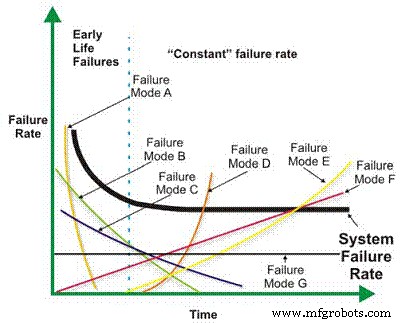
Figure 13. Good field data collection enables you to break the random trap.
This brief introduction to reliability engineering methods is intended to expose the otherwise uninitiated plant engineer to the world of quantitative reliability engineering. The subject is quite broad, however, and I’ve only touched on the major reliability methods that I believe are most applicable to the plant engineer. I encourage you to further investigate the field of reliability engineering methods, concentrating on the following topics, among others:
-
More detailed understanding of the Weibull distribution and its applications
-
More detailed understanding of the exponential distribution and its applications
-
The Gaussian distribution and its applications
-
The log-normal distribution and its applications
-
Confidence intervals (binomial, chi-square/Poisson, etc.)
-
Beta distribution and its applications
-
Bayesian applications of reliability engineering methods
-
Stress-strength interference analysis
-
Testing options and their applicability to plant reliability engineering
-
Reliability growth strategies and management
-
More detailed understanding of field data collection.
Most important, spend time learning how to apply reliability engineering methods to plant reliability problems. If your interest in reliability engineering methods is high, I encourage you to pursue professional certification by the American Society for Quality as a reliability engineer (CRE).
References
Troyer, D. (2006) Strategic Plant Reliability Management Course Book, Noria Publishing, Tulsa, Oklahoma.
Bernowski, K (1997) “Safety in the Skies,” Quality Progress , January.
Dovich, R. (1990) Reliability Statistics, ASQ Quality Press, Milwaukee, WI.
Krishnamoorthi, K.S. (1992) Reliability Methods for Engineers, ASQ Quality Press , Milwaukee, WI.
MIL Standard 721
IEC Standard 300-3-3
DOE Standard NE-1004-92
Appendix:Select reliability engineering terms from MIL STD 721
Availability – A measure of the degree to which an item is in the operable and committable state at the start of the mission, when the mission is called for at an unknown state.
Capability – A measure of the ability of an item to achieve mission objectives given the conditions during the mission.
Dependability – A measure of the degree to which an item is operable and capable of performing its required function at any (random) time during a specified mission profile, given the availability at the start of the mission.
Failure – The event, or inoperable state, in which an item, or part of an item, does not, or would not, perform as previously specified.
Failure, dependent – Failure which is caused by the failure of an associated item(s). Not independent.
Failure, independent – Failure which occurs without being caused by the failure of any other item. Not dependent.
Failure mechanism – The physical, chemical, electrical, thermal or other process which results in failure.
Failure mode – The consequence of the mechanism through which the failure occurs, i.e. short, open, fracture, excessive wear.
Failure, random – Failure whose occurrence is predictable only in the probabilistic or statistical sense. This applies to all distributions.
Failure rate – The total number of failures within an item population, divided by the total number of life units expended by that population, during a particular measurement interval under stated conditions.
Maintainability – The measure of the ability of an item to be retained or restored to specified condition when maintenance is performed by personnel having specified skill levels, using prescribed procedures and resources, at each prescribed level of maintenance and repair.
Maintenance, corrective – All actions performed, as a result of failure, to restore an item to a specified condition. Corrective maintenance can include any or all of the following steps:localization, isolation, disassembly, interchange, reassembly, alignment and checkout.
Maintenance, preventive – All actions performed in an attempt to retain an item in a specified condition by providing systematic inspection, detection and prevention of incipient failures.
Mean time between failure (MTBF) – A basic measure of reliability for repairable items:the mean number of life units during which all parts of the item perform within their specified limits, during a particular measurement interval under stated conditions.
Mean time to failure (MTTF) – A basic measure of reliability for non-repairable items:The mean number of life units during which all parts of the item perform within their specified limits, during a particular measurement interval under stated conditions.
Mean time to repair (MTTR) – A basic measure of maintainability:the sum of corrective maintenance times at any specified level of repair, divided by the total number of failures within an item repaired at that level, during a particular interval under stated conditions.
Mission reliability – The ability of an item to perform its required functions for the duration of specified mission profile.
Reliability – (1) The duration or probability of failure-free performance under stated conditions. (2) The probability that an item can perform its intended function for a specified interval under stated conditions. For non-redundant items this is the equivalent to definition (1). For redundant items, this is the definition of mission reliability.
Entretien et réparation d'équipement
- Le cas de la maintenance mobile :Fiix s'arrête au podcast Asset Reliability @ Work
- Quel est le rôle de l'ingénieur fiabilité ?
- LCE offre un cours de fiabilité pour les managers
- La clé n°1 du succès de la fiabilité
- RH :le chaînon manquant vers la fiabilité
- Le côté non technique de la fiabilité
- Meilleures pratiques pour un nettoyage écologique de la peinture autour de l'usine
- Matière à réflexion :évitez la vision en tunnel dans l'usine
- PLA Corbion total en phase d'ingénierie pour la nouvelle usine PLA en Europe