


La startup emballe 1 000 cœurs RISC-V dans une puce d'accélérateur d'IA
La puce écoénergétique de la startup cible M.2 sockets d'accélérateur pour accélérer les modèles de recommandation dans les centres de données.
Coïncidant avec la conférence Hot Chips, la startup Esperanto est sortie du mode furtif cette semaine avec la puce commerciale RISC-V la plus performante à ce jour – un accélérateur d'IA à mille cœurs conçu pour les centres de données à grande échelle. Alors que la puce peut fonctionner dans un certain nombre de profils de tension et de puissance entre 10 et 60 W, son "sweet spot" est de 20 W de puissance par puce, une configuration qui permet de monter six puces sur une carte accélératrice Glacier Point, en gardant consommation totale inférieure à 120 W. La performance totale de six puces est d'environ 800 TOPS.
L'ET-SoC-1 d'Esperanto est présenté comme ayant le plus grand nombre de cœurs RISC-V jamais construits sur une seule puce :1 093. Le nombre comprend 1 088 cœurs RISC-V personnalisés ET-Minion qui servent de moteurs d'accélération d'IA écoénergétiques. Sont également inclus quatre cœurs ET-Maxion RISC-V et un processeur de service RISC-V. L'ensemble de la conception est axé sur l'efficacité énergétique.
Avant les Hot Chips, EE Times s'est entretenu avec le vétéran de l'industrie Dave Ditzel, fondateur et président exécutif de l'espéranto. (Les références de Ditzel incluent la co-rédaction avec David Patterson de l'article fondateur "The Case for the Reduced Instruction Set Computer" publié en 1980.)

Dave Ditzel (Source :Espéranto)
"Nous sommes les premiers à mettre un millier de cœurs RISC-V sur une seule puce", a déclaré Ditzel. « Les gens parlent de processeurs multicœurs depuis des années, mais nous n'en avons pas vu beaucoup. La plupart des éléments RISC-V disponibles sont destinés à l'intégration.
"Nous avons dit:" Montrons-leur que RISC-V peut faire du haut de gamme… Nous allons leur montrer ce que les concepteurs de processeurs vraiment chevronnés peuvent faire ici. "
Exigences du client
L'équipe de concepteurs de processeurs de Ditzel a pu extraire des détails des opérateurs de centres de données à grande échelle sur leurs besoins.
"Ils ne voulaient pas de puce d'entraînement, ils n'ont pas de problème avec l'entraînement", a déclaré Ditzel. La formation à l'IA est souvent un problème hors ligne, et l'énorme capacité du processeur x86 des hyper-scalers n'est pas toujours à la charge maximale. Par conséquent, cette capacité peut être utilisée pour la formation lorsqu'elle est disponible. "Leur vrai problème est l'inférence", a ajouté Ditzel. « C’est ce qui motive leur publicité. Ils ont besoin d'une réponse en 10 millisecondes ou moins. »
Par conséquent, l'accélération du moteur d'inférence de recommandations pour la publicité en ligne est devenue un objectif de la puce du centre de données. Les exigences des hyper-scalers pour accélérer ce type de modèle étaient assez explicites.
« Nos clients voulaient 100 mégaoctets de mémoire sur puce – tout ce qu'ils voulaient faire avec l'inférence tient dans 100 mégaoctets », a-t-il déclaré. Les clients voulaient également une interface externe pour la mémoire hors puce. "Le vrai problème est de savoir combien vous pouvez conserver sur la carte d'accélérateur", a expliqué Ditzel. « Considérez la carte comme l'unité de calcul, pas la puce. Une fois que vous pouvez obtenir de la mémoire sur la carte, vous pouvez accéder aux choses beaucoup plus rapidement que de traverser le bus PCIe jusqu'à l'hôte. »
cliquez pour l'image en taille réelle

L'espéranto installe six doubles cartes M.2, chacune avec une puce, sur une carte accélératrice Glacier Point. (Source :Espéranto)
Le système de mémoire sur puce possède des caches L1, L2 et L3 et un système de mémoire principale complet avec des fichiers de registre pour un total d'un peu plus de 100 Mo. Le système de mémoire sur carte peut contenir la plupart des poids et activations du modèle dans environ 100 Go.
Les modèles de recommandation sont notoirement difficiles à accélérer, ce qui est l'une des raisons pour lesquelles ils s'exécutent toujours sur les serveurs CPU existants.
« Lorsque vous choisissez parmi 100 millions de clients et ce qu'ils ont acheté récemment, vous devez accéder à cette… mémoire sur la carte, et vous effectuez toutes sortes d'accès mémoire aléatoires, donc les caches ne le font pas. travail. Vous avez vraiment besoin de plus d'un ordinateur classique », a déclaré Ditzel. Les « serveurs x86 gèrent de bonnes quantités de mémoire et ils ont une pré-extraction, et les processeurs à usage général gèrent très bien cette charge de travail. Il a été difficile pour les accélérateurs de percer dans le secteur des recommandations à cause de cela. »
La prise en charge de INT8 avec les types de données FP16 et FP32 est également requise. L'exigence de calculs à virgule flottante découle à la fois de la nécessité de maintenir la précision de prédiction la plus élevée possible et du manque d'inclination à porter ou à réécrire des programmes pour des calculs de moindre précision. Ditzel a déclaré que les principaux fabricants de puces de serveur x86 n'ont ajouté que récemment des extensions vectorielles 8 bits aux processeurs de serveur.
« La plupart des déductions effectuées dans [un centre de données à grande échelle] sur leurs millions de serveurs x86 sont toujours des données flottantes 32 bits », a-t-il déclaré.
La puce d'Esperanto sur une double carte M.2 est conçue pour s'insérer dans les emplacements d'accélérateur au sein de l'infrastructure de serveur CPU x86 existante. Cela se traduit par une limite de puissance de 120 W, nécessitant un refroidissement par air.
Ditzel a déclaré que la conception de l'espéranto ne concurrence pas directement les efforts internes tels que les TPU de Google ou Inferentia d'Amazon Web Services. Les hyper-scalers « essaient d'amener toute la communauté à construire des puces d'accélérateur pour eux. Beaucoup de ces entreprises croient en l'informatique ouverte et au [Open Compute Project]. » Par conséquent, « ils achètent des serveurs OCP et ils aimeraient que des éléments standardisés y soient intégrés. S'il y a de la concurrence, ils adorent ça… ils essaient d'encourager la concurrence et de montrer aux gens ce qui est possible. »
Pourtant, la startup insiste sur le fait que les opérateurs de grands centres de données ont besoin de fournisseurs externes pour les puces d'accélérateur. « C’est toujours une décision de faire contre acheter. » Par exemple, un client d'espéranto n'avait pas accès à des puces développées en interne et utilisées par une autre division. « Si vous battez ce qu'ils ont, l'entrée dans l'une de ces sociétés est possible. »
Nouvelle approche
L'espéranto a adopté l'approche opposée aux accélérateurs géants de puces énergivores de ses concurrents, offrant une puce de moindre puissance qui peut être utilisée en multiples. L'approche répond aux exigences de bande passante mémoire, car davantage de broches peuvent être utilisées pour les E/S mémoire sans avoir à recourir à un HBM coûteux.
Le matériel de l'espéranto est également conçu comme un ordinateur à usage général; malgré l'accent mis sur les modèles de recommandation, la puce peut accélérer le traitement parallèle, selon Ditzel. Une carte accélératrice à six puces comprend environ 6 000 cœurs parallèles, et chaque cœur peut exécuter deux threads, qui peuvent être « jetés à tout problème arbitraire ».
Un autre atout de l'espéranto est une conception agressive et économe en énergie. Les exigences des clients ont fixé le budget d'alimentation à 120 W au total, tandis que l'espace maximum établi sur une carte Glacier Point était de six puces, soit 20 W par puce. Par comparaison, les accélérateurs d'inférence d'IA fonctionnent à plus de dix fois cette quantité.
L'espéranto a abordé la question sous plusieurs angles. La fréquence d'horloge a été réduite à un niveau optimal d'environ 1 GHz. La tension d'alimentation a été réduite à environ 0,4 V, au-delà de la limite des SRAM. La capacité de commutation a été facilitée par l'utilisation de noyaux RISC-V allégés avec le plus petit jeu d'instructions commercialement viable pour réduire le nombre de transistors. Une technologie de traitement avancée mais stable, TSMC 7 nm, a été choisie.
cliquez pour l'image en taille réelle
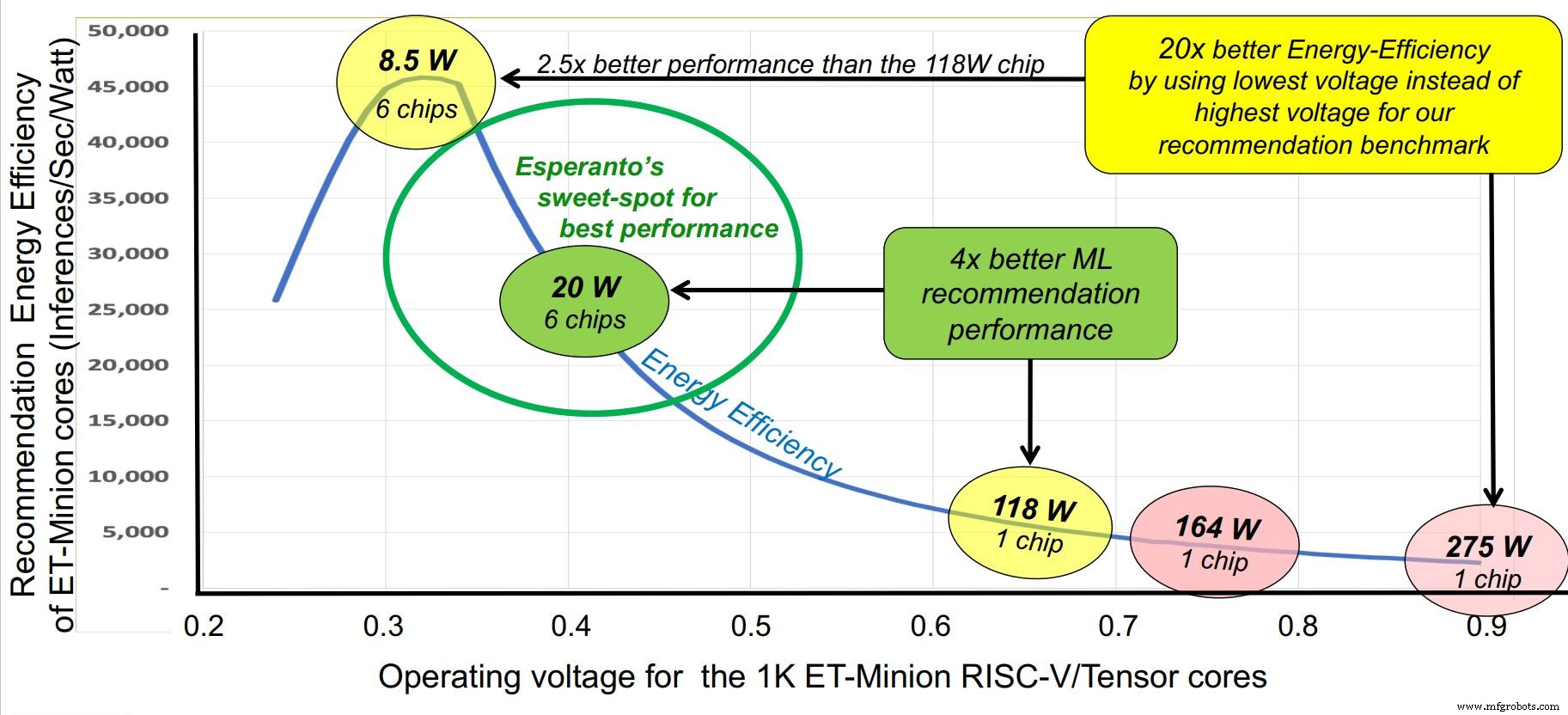
L'espéranto a identifié un "sweet spot" pour un fonctionnement à environ 1 GHz. (Source :Espéranto)
Conception de base
La puce d'Esperanto comprend 1 088 cœurs ET-Minion, qui traitent la charge de travail de l'IA. Les cœurs sont des processeurs RISC-V 64 bits dans l'ordre avec la propre unité de vecteur et de tenseur optimisée pour l'IA d'Esperanto occupant une grande partie de l'espace de la puce. Les MAC à virgule flottante dominent la configuration. Exceptionnellement, les MAC entiers ont deux fois la largeur de traitement de la virgule flottante (selon les exigences du client, a noté Ditzel). Les instructions transcendantales vectorielles telles que les fonctions sigmoïdes courantes dans les modèles d'apprentissage en profondeur sont également prises en charge. Étant donné que les cœurs fonctionnent dans un seul domaine basse tension, davantage de transistors ont été utilisés avec la SRAM dans le petit cache L1 pour garantir des performances robustes.
cliquez pour l'image en taille réelle
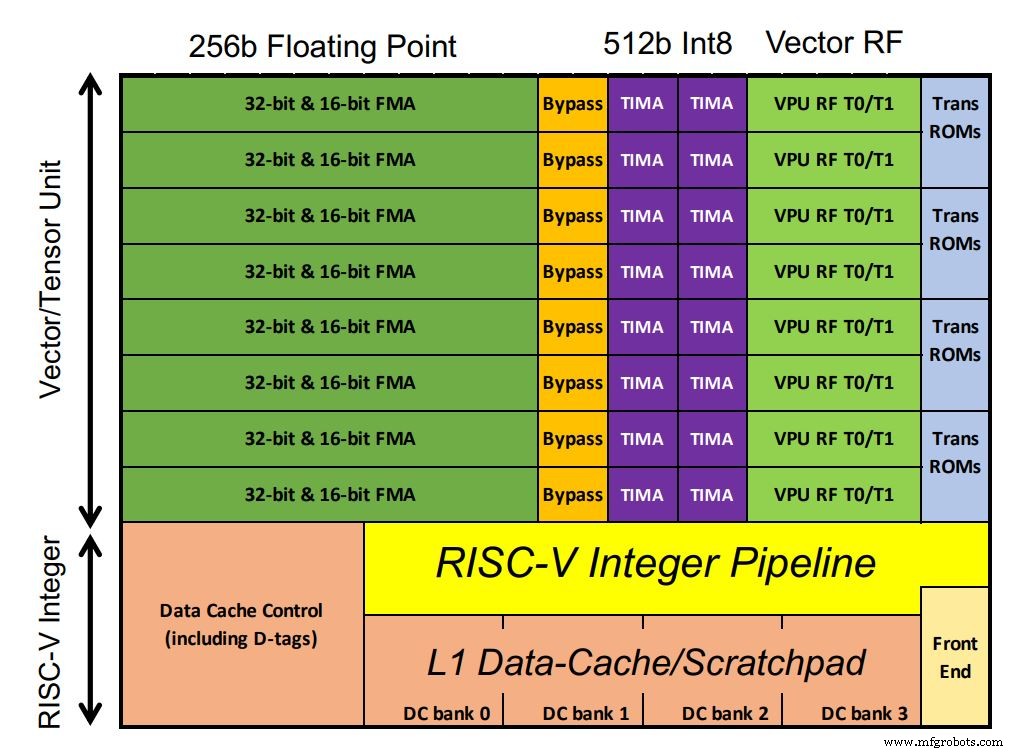
La puce d'Esperanto contient 1 088 cœurs ET-Minion (cliquez sur l'image pour l'agrandir) (Source :Esperanto)
Chaque cœur est capable de 128 GOPS par GHz. Une instruction de tenseur multicycle personnalisée effectue de grandes multiplications matricielles avec un contrôleur séparé prenant le relais et exécutant jusqu'à 512 cycles en utilisant la pleine largeur de 512 bits. Cela permet à l'instruction de tenseur unique d'effectuer plus de 64 000 opérations arithmétiques avant que le contrôleur n'aille chercher la prochaine instruction RISC-V. Cela réduit la bande passante des instructions puisque la majeure partie de la charge de travail utilise l'instruction du tenseur. Par conséquent, une seule instruction par 512 cycles d'horloge est nécessaire.
Huit cœurs ET-Minion constituent un « voisinage » et des instructions modifiées tirent parti de leur proximité physique. Une autre fonctionnalité appelée « charges coopératives » permet aux cœurs de transférer des données directement les uns des autres sans récupération de cache. Cette configuration économise de l'énergie. Les huit cœurs partagent également un grand cache L2 pour une efficacité énergétique.
En dézoomant à nouveau, quatre quartiers à 8 cœurs forment un « Minion Shire », avec 34 shires sur chaque puce, pour un total de 1 088 cœurs. (Le calcul avec seulement 1 024 cœurs pour améliorer le rendement est également possible, a déclaré Ditzel). Quatre cœurs ET-Maxion, chacun avec des performances à peu près comparables à celles d'un bras A-72, sont destinés à un fonctionnement autonome futur, plutôt qu'à la configuration actuelle de l'accélérateur.
La variation de tension de seuil est atténuée en fournissant à chaque Shire sa propre alimentation en tension afin que les tensions individuelles puissent être ajustées avec précision.
Système de mémoire
Chaque puce possède quatre interfaces DDR 64 bits – en fait, chaque interface représente quatre canaux 16 bits – pour un total de 96 canaux 16 bits. La conception utilise LPDDR4x développé comme mémoire basse consommation pour les smartphones. L'énergie par bit est à peu près équivalente à HBM, mais le maintien du total à 1 536 bits sur l'interface mémoire de la carte accélératrice à six puces permet d'obtenir une bande passante mémoire totale plus élevée.
L'espéranto a monté ses puces sur des cartes M.2 à double socket; six tiennent sur une carte accélératrice OCP Glacier Point v2 (trois à l'avant, trois à l'arrière). Cela fournit environ 800 TOPS avec les puces fonctionnant à 1 GHz. Ils peuvent également être montés sur des cartes PCIe à profil bas (mi-hauteur, mi-longueur) qui augmentent le budget de puissance de chaque puce à environ 60 W. Les puces peuvent fonctionner entre 300 MHz et 2 GHz, selon l'application.
Sur la base des résultats de l'émulation matérielle, Ditzel a affirmé que six puces d'espéranto sur une carte Glacier Point peuvent surpasser ses concurrents. L'avantage du démarrage est prononcé pour les références de recommandation lorsque la conception du système de mémoire et les chiffres de performance par watt sont pris en compte, une conséquence de l'accent mis sur une conception à basse tension.
Les futures versions pourraient inclure une version réduite d'ET-SoC-1 pour les applications de périphérie. Ditzel a déclaré que la version actuelle devrait être lancée dans "les deux prochains mois".
>> Cet article a été initialement publié sur notre site frère, EE Fois.
Contenus associés :
- Les SoC compatibles avec l'IA gèrent plusieurs flux vidéo
- Xilinx cible le déchargement du centre de données avec du matériel « composable »
- Reduced operation set computing (ROSC) pour la couverture fonctionnelle NNA
- L'architecture hybride accélère les charges de travail de l'IA et de la vision
- Les accélérateurs matériels servent les applications d'IA
Pour plus d'informations sur Embedded, abonnez-vous à la newsletter hebdomadaire d'Embedded.
Embarqué
- Revolver
- Sommet RISC-V :points saillants de l'ordre du jour
- Arm permet des instructions personnalisées pour les cœurs Cortex-M
- Concevoir avec Bluetooth Mesh :puce ou module ?
- L'architecture de la puce IA cible le traitement des graphes
- Petit module Bluetooth 5.0 intégrant une antenne à puce
- Les chercheurs créent une petite étiquette d'identification d'authentification
- Débuts du processeur radar d'imagerie automobile à 30 ips
- La puce radar de faible puissance utilise des réseaux de neurones à pointes