


Les microcontrôleurs jouent un rôle croissant dans l'IA de pointe
Il y a quelques années à peine, on supposait que l'apprentissage automatique (ML) - et même l'apprentissage en profondeur (DL) - ne pouvaient être effectués que sur du matériel haut de gamme, avec une formation et une inférence à la périphérie exécutées par des passerelles, des serveurs de périphérie ou des données. centres. C'était une hypothèse valable à l'époque car la tendance à la distribution des ressources de calcul entre le cloud et la périphérie en était à ses débuts. Mais ce scénario a radicalement changé grâce aux efforts intensifs de recherche et développement déployés par l'industrie et les universités.
Le résultat est qu'aujourd'hui, les processeurs capables de fournir plusieurs milliers de milliards d'opérations par seconde (TOPS) ne sont pas tenus d'effectuer le ML. Dans un nombre croissant de cas, les derniers microcontrôleurs, certains avec des accélérateurs de ML intégrés, peuvent amener le ML aux appareils de périphérie.
Non seulement ces appareils peuvent effectuer le ML, mais ils peuvent le faire bien, à faible coût, avec une très faible consommation d'énergie, en se connectant au cloud uniquement lorsque cela est absolument nécessaire. En bref, les microcontrôleurs avec accélérateurs ML intégrés représentent la prochaine étape pour amener l'informatique aux capteurs tels que les microphones, les caméras et ceux qui surveillent les conditions environnementales, qui génèrent les données sur lesquelles tous les avantages de l'IoT sont réalisés.
Quelle est la profondeur du bord ?
Alors que la périphérie est généralement considérée comme le point le plus éloigné d'un réseau IoT, elle est généralement considérée comme une passerelle ou un serveur de périphérie avancé. Cependant, ce n'est pas là que le bord se termine réellement. Il se termine au niveau des capteurs à proximité de l'utilisateur. Il devient logique de placer autant de puissance analytique près de l'utilisateur que possible, une tâche pour laquelle les microcontrôleurs sont idéalement adaptés.
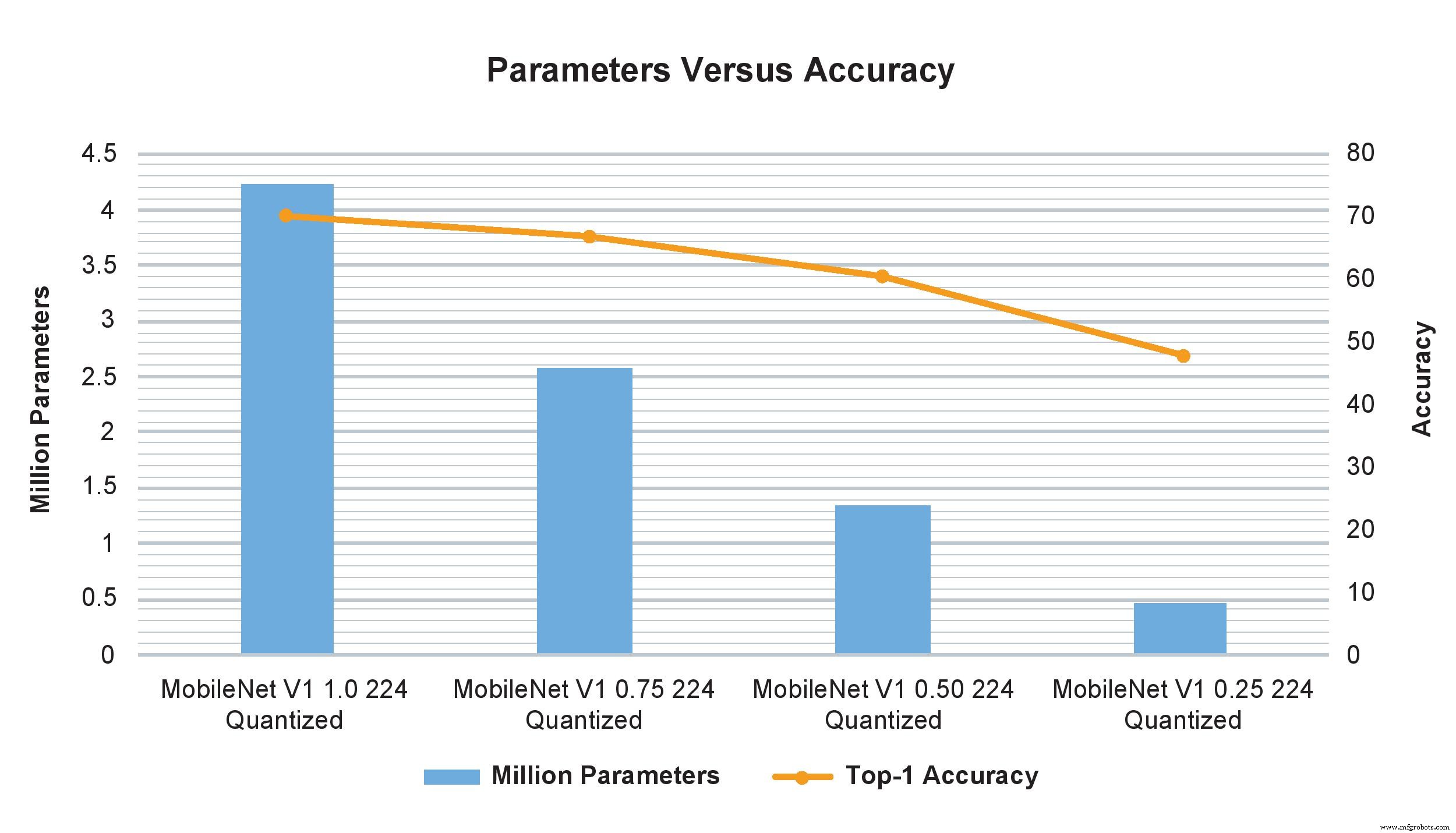
Les exemples de modèle MobileNet V1 de multiplicateurs de largeur variables montrent un impact drastique sur le nombre de paramètres, de calculs et de précision. Cependant, le simple fait de changer le multiplicateur de largeur de 1,0 à 0,75 affecte de manière minimale la précision TOP-1 mais a un impact significatif sur le nombre de paramètres et de calculs (Image :NXP)
On pourrait faire valoir que les ordinateurs à carte unique peuvent également être utilisés pour le traitement à la périphérie, car ils sont capables de performances remarquables et, lorsqu'ils sont en grappes, peuvent rivaliser avec un petit supercalculateur. Mais ils sont encore trop volumineux et trop coûteux pour être déployés par centaines ou par milliers requis dans des applications à grande échelle. Ils nécessitent également une source externe d'alimentation CC qui, dans certains cas, peut dépasser ce qui est disponible, tandis qu'un MCU ne consomme que des milliwatts et peut être alimenté par des piles boutons ou même quelques cellules solaires.
Il n'est donc pas surprenant que l'intérêt pour les microcontrôleurs pour effectuer le ML à la périphérie soit devenu un domaine de développement très chaud. Il a même un nom – TinyML. L'objectif de TinyML est de permettre à l'inférence, et finalement à la formation, d'être exécutée sur de petits appareils à faible consommation de ressources limitées, et en particulier des microcontrôleurs, plutôt que sur des plates-formes plus grandes ou dans le cloud. Cela nécessite que la taille des modèles de réseaux neuronaux soit réduite pour s'adapter aux ressources de traitement, de stockage et de bande passante relativement modestes de ces appareils, sans réduire considérablement la fonctionnalité et la précision.
Ces schémas d'optimisation des ressources permettent aux appareils d'ingérer suffisamment de données de capteur pour atteindre leur objectif tout en ajustant la précision et en réduisant les besoins en ressources. Ainsi, même si les données peuvent toujours être envoyées vers le cloud (ou peut-être d'abord vers une passerelle périphérique puis vers le cloud), elles seront beaucoup moins nombreuses car une analyse considérable a déjà été effectuée.
Un exemple populaire de TinyML en action est un système de détection d'objets basé sur une caméra qui, bien que capable de capturer des images haute résolution, dispose d'un stockage limité et nécessite une réduction de la résolution de l'image. Cependant, si la caméra inclut des analyses sur l'appareil, seuls les objets d'intérêt sont capturés plutôt que la scène entière, et comme les images pertinentes sont moins nombreuses, leur résolution plus élevée peut être conservée. Cette capacité est généralement associée à des appareils plus gros et plus puissants, mais la minuscule technologie ML permet de le faire sur des microcontrôleurs.
Petit mais puissant
Bien que TinyML soit un paradigme relativement nouveau, il produit déjà des résultats surprenants pour l'inférence (avec des microcontrôleurs même relativement modestes) et la formation (sur des plus puissants) avec une perte de précision minimale. Les exemples récents incluent la reconnaissance vocale et faciale, les commandes vocales et le traitement du langage naturel, et même l'exécution de plusieurs algorithmes de vision complexes en parallèle.
Concrètement, cela signifie qu'un microcontrôleur coûtant moins de 2 USD avec un cœur Arm Cortex-M7 à 500 MHz et de 28 Ko à 128 Ko de mémoire peut fournir les performances requises pour rendre les capteurs vraiment intelligents.
Même à ce prix et à ce niveau de performances, ces microcontrôleurs ont plusieurs fonctions de sécurité, y compris AES-128, la prise en charge de plusieurs types de mémoire externe, Ethernet, USB et SPI, et incluent ou prennent en charge divers types de capteurs, ainsi que Bluetooth, Wi-Fi et SPDIF et I 2 C interfaces audio. Dépensez un peu plus et l'appareil aura généralement un Arm Cortex-M7 à 1 GHz, un Cortex-M4 à 400 MHz, 2 Mo de RAM et une accélération graphique. La consommation d'énergie n'est généralement pas supérieure à quelques milliampères à partir d'une alimentation de 3,3 VCC.
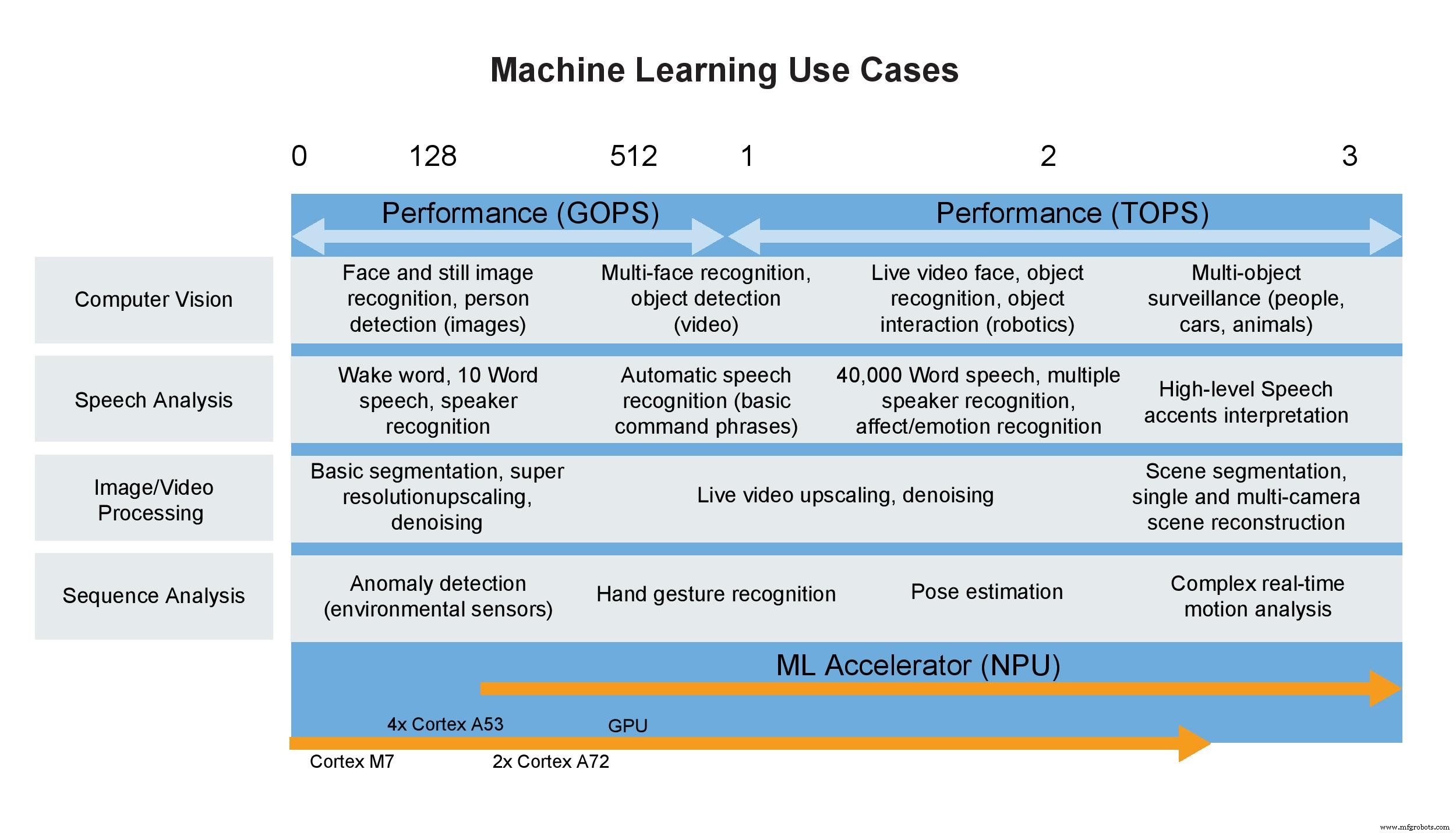
Cas d'utilisation de l'apprentissage automatique (Image :NXP)
Quelques mots sur TOPS
Les consommateurs ne sont pas seuls lorsqu'ils utilisent une seule métrique pour définir les performances; les designers le font tout le temps, et les services marketing adorent ça. C'est parce qu'une spécification de titre rend la différenciation entre les appareils simple, du moins il semblerait. Un exemple classique est le CPU, qui pendant de nombreuses années a été défini par sa fréquence d'horloge. Heureusement pour les designers comme pour les consommateurs, ce n'est plus le cas. Utiliser une seule métrique pour évaluer un processeur revient à évaluer les performances d'une voiture par la ligne rouge du moteur. Cela n'a pas de sens, mais a peu à voir avec la puissance du moteur ou les performances de la voiture, car de nombreux autres facteurs déterminent ensemble ces caractéristiques.
Malheureusement, la même chose est de plus en plus vraie pour les accélérateurs de réseaux de neurones, y compris ceux des MPU ou des microcontrôleurs hautes performances, qui sont spécifiés par des milliards ou des milliards d'opérations par seconde car, encore une fois, c'est un nombre facile à retenir. Mais dans la pratique, GOPS et TOPS à eux seuls sont des mesures relativement dénuées de sens et représentent une mesure (sans aucun doute la meilleure) réalisée en laboratoire plutôt que de représenter un environnement d'exploitation réel. Par exemple, TOPS ne prend pas en compte les limitations de la bande passante mémoire, la surcharge CPU requise, le pré-traitement et le post-traitement et d'autres facteurs. Lorsque tous ces éléments et d'autres sont pris en compte, comme les performances lorsqu'elles sont utilisées sur une carte spécifique en fonctionnement réel, les performances au niveau du système pourraient probablement être de 50 % ou 60 % de la valeur TOPS sur la fiche technique.
Tous ces chiffres vous indiquent le nombre d'éléments de calcul dans le matériel multiplié par leur vitesse d'horloge, plutôt que la fréquence à laquelle les données seront disponibles lorsqu'il devra fonctionner. Si les données étaient toujours immédiatement disponibles, que la consommation d'énergie n'était pas un problème, que les contraintes de mémoire n'existaient pas et que l'algorithme était mappé de manière transparente sur le matériel, elles seraient plus significatives. Mais le monde réel ne présente pas de tels environnements idéaux.
Lorsqu'elle est appliquée aux accélérateurs ML dans les microcontrôleurs, la métrique est encore moins précieuse. Ces petits appareils ont généralement une valeur de 1 à 3 TOPS, mais peuvent toujours fournir les capacités d'inférence requises dans de nombreuses applications ML. Ces appareils reposent également sur des processeurs Arm Cortex spécialement conçus pour les applications ML à faible consommation. Outre la prise en charge des opérations entières et flottantes et des nombreuses autres fonctionnalités du microcontrôleur, il devient évident que TOPS, ou toute autre métrique unique, est incapable de définir correctement les performances, que ce soit seul ou dans un système.
Conclusion
Le désir d'effectuer des inférences sur des microcontrôleurs directement sur ou attachés à des capteurs, tels que des caméras fixes et vidéo, émerge maintenant à mesure que le domaine de l'IoT se rapproche de l'exécution d'autant de traitements que possible à la périphérie. Cela dit, le rythme de développement des processeurs d'application et des accélérateurs de réseaux neuronaux au sein des microcontrôleurs est rapide et des solutions plus performantes apparaissent fréquemment. La tendance est à la consolidation de fonctionnalités plus centrées sur l'IA, telles que le traitement du réseau neuronal, avec un processeur d'application dans le microcontrôleur sans augmenter considérablement la consommation d'énergie ou la taille.
Aujourd'hui, les modèles peuvent être entraînés sur un processeur ou un processeur graphique plus puissant, puis implémentés sur un microcontrôleur à l'aide de moteurs d'inférence tels que TensorFlow Lite pour réduire leur taille afin de répondre aux besoins en ressources du microcontrôleur. La mise à l'échelle peut facilement être effectuée pour répondre à des exigences de ML plus importantes. Bientôt, il devrait être possible d'effectuer non seulement des inférences, mais aussi une formation sur ces appareils, ce qui fera du microcontrôleur un concurrent encore plus redoutable des solutions informatiques plus grandes et plus chères.
>> Cet article a été initialement publié le notre site partenaire, EE Times.
Embarqué
- Rôle du cloud computing dans l'intelligence
- Le refroidissement par chambre à vapeur joue un rôle croissant dans les produits chauds
- La récupération d'énergie RF joue un rôle croissant dans les applications basées sur l'IA
- USB-C trouve un rôle croissant dans les appareils portables et les produits mobiles
- Petit module d'IA basé sur Google Edge TPU
- La carte de capteur intelligent accélère le développement de l'IA de pointe
- La caméra intelligente offre une IA de pointe en vision industrielle clé en main
- Les robots jouent un rôle dans l'industrie 4.0
- Le rôle de l'Edge Computing dans les déploiements IoT commerciaux