


PyTorch vs TensorFlow :comparaison approfondie
La popularité croissante de l'apprentissage en profondeur a créé une saine concurrence entre les cadres d'apprentissage en profondeur. PyTorch et TensorFlow se distinguent comme deux des frameworks d'apprentissage en profondeur les plus populaires. Les bibliothèques sont en concurrence directe pour devenir le principal outil d'apprentissage en profondeur.
TensorFlow est plus ancien et a toujours eu une avance à cause de cela, mais PyTorch a rattrapé son retard au cours des six derniers mois. Il y a beaucoup de confusion quant à faire le bon choix lors du choix d'un cadre d'apprentissage en profondeur pour un projet.
Cet article compare PyTorch à TensorFlow et fournit une comparaison approfondie des deux frameworks.
PyTorch et TensorFlow :un aperçu
PyTorch et TensorFlow gardent une trace de ce que font leurs concurrents. Cependant, il existe encore des différences entre les deux cadres.
Remarque : Ce tableau peut défiler horizontalement.
| Bibliothèque | PyTorch | TensorFlow 2.0 |
|---|---|---|
| Créé par | FAIR Lab (Facebook AI Research Lab) | Équipe Google Brain |
| Basé sur | Torche | Théano |
| Production | axé sur la recherche | Concentré sur l'industrie |
| Visualisation | Visdom | Tensorboard |
| Déploiement | Chalumeau (expérimental) | Serveur TensorFlow |
| Déploiement mobile | Oui (expérimental) | Oui |
| Gestion des appareils | CUDA | Automatisé |
| Génération de graphes | Mode dynamique et statique | Mode impatient et statique |
| Courbe d'apprentissage | Plus facile pour les développeurs et les scientifiques | Plus facile pour les projets au niveau de l'industrie |
| U ces cas | Facebook CheXNet Tesla Pilote automatique Uber PYRO | Google Sinovation Entreprises Pay Pal Mobile Chine |
1. Visualisation
La visualisation faite à la main prend du temps. PyTorch et TensorFlow ont tous deux des outils pour une analyse visuelle rapide. Cela facilite la révision du processus de formation. La visualisation est également idéale pour présenter les résultats.
TensorFlow
Tensorboard est utilisé pour visualiser les données. L'interface est interactive et visuellement attrayante. Tensorboard fournit un aperçu détaillé des métriques et des données d'entraînement. Les données sont facilement exportées et ont fière allure à des fins de présentation. Les plugins rendent également Tensorboard disponible pour PyTorch.
Cependant, Tensorboard est lourd et compliqué à utiliser.
PyTorch
PyTorch utilise Visdom pour la visualisation. L'interface est légère et simple à utiliser. Visdom est flexible et personnalisable. La prise en charge directe des tenseurs PyTorch facilite son utilisation.
Visdom manque d'interactivité et de nombreuses fonctionnalités essentielles pour la vue d'ensemble des données.
2. Génération de graphes
Il existe deux types de génération d'architecture de réseau de neurones :
- Graphiques statiques – Architecture de couche fixe. La carte est générée en premier, puis les données y sont poussées.
- Graphiques dynamiques – Architecture de couche dynamique. La carte est définie implicitement avec surcharge de données.
TensorFlow
TensorFlow a utilisé des graphiques statiques dès le départ. Les graphiques statiques permettent une distribution sur plusieurs machines. Les modèles sont déployés indépendamment du code. L'utilisation de graphiques statiques a rendu TensorFlow plus convivial pour la production et plus flexible lorsque vous travaillez avec de nouvelles architectures.
TensorFlow a ajouté une fonctionnalité qui imite les graphiques dynamiques appelés exécution impatiente. TensorFlow 2 s'exécute par défaut sur une exécution rapide. La génération de graphes statiques est disponible lors de la désactivation de l'exécution hâtive.
PyTorch
PyTorch a présenté des graphiques dynamiques dès le départ. Cette fonctionnalité met PyTorch en concurrence avec TensorFlow.
La possibilité de modifier les graphiques en déplacement s'est avérée être une approche plus conviviale pour les programmeurs et les chercheurs pour la génération de réseaux de neurones. Les données structurées et les variations de taille des données sont plus faciles à gérer avec des graphiques dynamiques. PyTorch fournit également des graphiques statiques.
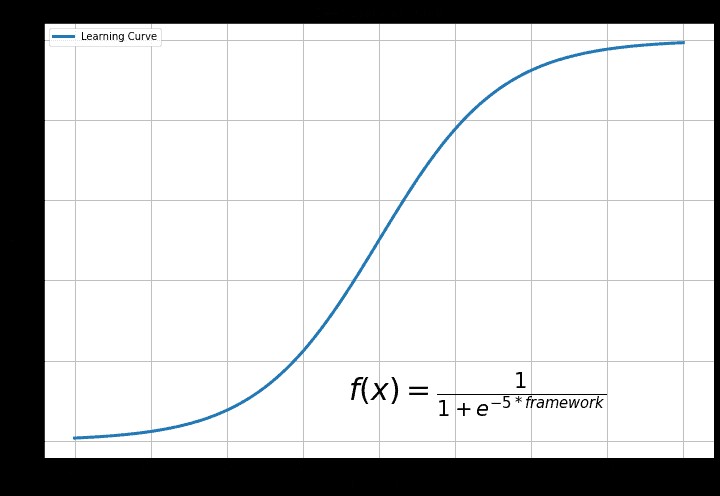
3. Courbe d'apprentissage
La courbe d'apprentissage dépend de l'expérience antérieure et de l'objectif final de l'utilisation de l'apprentissage en profondeur.
TensorFlow
TensorFlow est la bibliothèque la plus difficile. Les fonctions Keras rendent TensorFlow plus facile à utiliser. En règle générale, TensorFlow est difficile à comprendre pour quelqu'un qui débute dans l'apprentissage en profondeur.
La raison en est la diversité des fonctionnalités de TensorFlow. Il existe de nombreuses fonctionnalités à explorer et à comprendre. C'est distrayant et redondant pour un débutant.
PyTorch
PyTorch est la bibliothèque la plus facile à apprendre. Le code est plus facile à expérimenter si Python est familier. Il existe une approche Pythonic pour créer un réseau de neurones dans PyTorch. La flexibilité de PyTorch signifie que le code est convivial pour les expériences.
PyTorch n'est pas aussi riche en fonctionnalités, mais toutes les fonctionnalités essentielles sont disponibles. PyTorch est plus simple à utiliser et à apprendre.
4. Déploiement
Le déploiement est une étape de développement logiciel importante pour les équipes de développement logiciel. Le déploiement de logiciels rend un programme ou une application disponible pour une utilisation par les consommateurs.
TensorFlow
TensorFlow utilise TensorFlow Serving pour le déploiement du modèle. Diffusion TensorFlow est conçu pour les environnements de production et industriels. Le déploiement est flexible et performant avec une API client REST. Diffusion TensorFlow s'intègre bien avec Docker et Kubernetes.
PyTorch
PyTorch a récemment commencé à s'attaquer au problème du déploiement. Service à la torche déploie des modèles PyTorch. Il existe une API RESTful pour l'intégration d'applications. L'API PyTorch est extensible pour le déploiement mobile. Service à la torche s'intègre à Kubernetes.
5. Parallélisme et formation distribuée
Le parallélisme et la formation distribuée sont essentiels pour le Big Data. Les métriques générales sont :
- Augmentation de la vitesse – Rapport de la vitesse d'un modèle séquentiel (GPU unique) par rapport à la vitesse du modèle parallèle (GPU multiples).
- Débit – Le nombre maximal d'images passées dans le modèle par unité de temps.
- Évolutivité – Comment le système gère les augmentations de charge de travail.
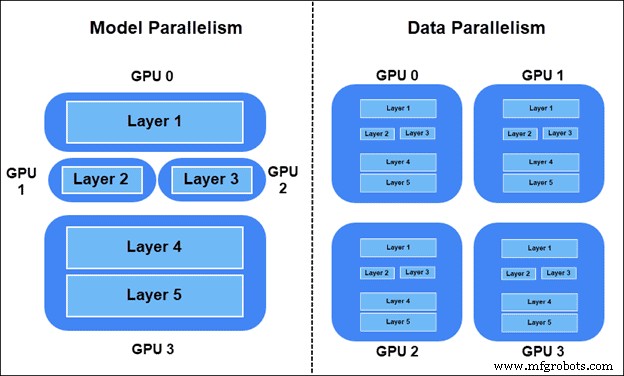
Il existe deux manières de répartir la charge de travail d'entraînement :
- Parallélisme des modèles – Couches du modèle réparties sur différents appareils. Certaines parties du graphique sont utilisées simultanément dans l'entraînement.
- Parallélisme des données – Tous les appareils ont une copie du modèle entier. Chaque appareil s'entraîne sur différents échantillons de données. La méthode synchrone SGD (Stochastic Gradient Descent) est préférée.
Parallélisme du modèle TensorFlow
Pour placer une partie du modèle dans un appareil spécifique dans TensorFlow, utilisez tf.device .
Par exemple, divisez deux couches linéaires sur deux appareils GPU différents :
import tensorflow as tf
from tensorflow.keras import layers
with tf.device(‘GPU:0’):
layer1 = layers.Dense(16, input_dim=8)
with tf.device(‘GPU:1’):
layer2 = layers.Dense(4, input_dim=16) Parallélisme du modèle PyTorch
Déplacez des parties du modèle vers différents appareils dans PyTorch en utilisant le nn.Module.to méthode.
Par exemple, déplacez deux couches linéaires vers deux GPU différents :
import torch.nn as nn layer1 = nn.Linear(8,16).to(‘cuda:0’) layer2 = nn.Lienar(16,4).to(‘cuda:1’)
Parallélisme des données TensorFlow
Pour effectuer un SGD synchrone dans TensorFlow, définissez la stratégie de distribution avec tf.distribute.MirroredStrategy() et encapsulez l'initialisation du modèle :
import tensorflow as tf strategy = tf.distribute.MirroredStrategy() with strategy.scope(): model = … model.compile(...)
Après avoir compilé le modèle avec le wrapper, entraînez le modèle comme d'habitude.
Parallélisme des données PyTorch
Pour SGD synchrone dans PyTorch, enveloppez le modèle dans torch.nn.DistributedDataParallel après l'initialisation du modèle et définissez le rang du numéro d'appareil en commençant par zéro :
from torch.nn.parallel import DistributedDataParallel. model = ... model = model.to() ddp_model = DistributedDataParallel(model, device_ids=[])
6. Gestion des appareils
Des changements massifs de performances se produisent lors de la gestion des appareils. PyTorch et TensorFlow appliquent bien les réseaux de neurones, mais l'exécution est différente.
TensorFlow
TensorFlow passe automatiquement à l'utilisation du GPU si un GPU est disponible. Il y a un contrôle sur les GPU et la façon dont ils sont accessibles. L'accélération GPU est automatisée. Cela signifie qu'il n'y a aucun contrôle sur l'utilisation de la mémoire.
PyTorch
PyTorch utilise CUDA pour spécifier l'utilisation du GPU ou du CPU. Le modèle ne fonctionnera pas sans les spécifications CUDA pour l'utilisation du GPU et du CPU. L'utilisation du GPU n'est pas automatisée, ce qui signifie qu'il y a un meilleur contrôle sur l'utilisation des ressources. PyTorch améliore le processus de formation grâce au contrôle GPU.
7. Cas d'utilisation pour les deux plates-formes d'apprentissage en profondeur
TensorFlow et PyTorch ont d'abord été utilisés dans leurs sociétés respectives. Depuis qu'il est devenu open source, il existe également de nombreux cas d'utilisation en dehors de Google et de Facebook.
TensorFlow
Les chercheurs de Google de Google Brain Team ont d'abord utilisé TensorFlow pour des projets de recherche Google. Google utilise TensorFlow pour :
- Résultats de recherche et saisie semi-automatique.
- Technologie de synthèse vocale et vocale
- Reconnaissance et classification d'images.
- Systèmes de traduction automatique.
- Détection de spam pour Gmail.
Il existe également de nombreux cas d'utilisation en dehors de Google. Par exemple :
- Sinovation Ventures – Classification et segmentation des maladies à l'aide d'images de rétines.
- PayPal – Détection des fraudes avec apprentissage par transfert approfondi et modélisation générative.
- Chine Mobile – Systèmes d'apprentissage en profondeur pour la détection des problèmes dans les réseaux, la prédiction automatisée des fenêtres de temps de basculement et la vérification des journaux d'opérations.
PyTorch
PyTorch a été utilisé pour la première fois sur Facebook par le Facebook AI Researchers Lab (FAIR). Facebook utilise PyTorch pour :
- Reconnaissance faciale et détection d'objets
- Filtrage des spams et détection des fausses nouvelles
- Automatisation du fil d'actualité et système de suggestion d'amis
- Reconnaissance vocale.
- Systèmes de traduction automatique.
PyTorch est open source. Il existe maintenant de nombreux cas d'utilisation en dehors de Facebook, tels que :
- CheXNet – Score de probabilité de pneumonie et carte thermique des rayons X du thorax à l'aide de réseaux de neurones convolutifs.
- Pilote automatique Tesla – Multitâche de vision par ordinateur en temps réel pour les véhicules autonomes.
- Uber AI Labs PYRO – Langage de programmation probabiliste pour la modélisation probabiliste profonde. Prévision et optimisation de la mise en correspondance des clients avec les chauffeurs, des itinéraires optimaux et des véhicules intelligents de nouvelle génération.
Devez-vous utiliser PyTorch ou TensorFlow ?
PyTorch est l'option préférée des programmeurs et des chercheurs scientifiques. La communauté scientifique préfère PyTorch pour le nombre de citations. Avec les récentes fonctionnalités de déploiement et de production, PyTorch est une excellente option pour passer de la recherche à la production.
Les organisations et les startups utilisent généralement TensorFlow. Les fonctionnalités de déploiement et de production confèrent à TensorFlow une bonne réputation dans les cas d'utilisation en entreprise. La visualisation avec Tensorboard montre également une présentation élégante aux clients.
PyTorch et TensorFlow sont de puissantes bibliothèques d'apprentissage en profondeur qui se développent intensivement. Aujourd'hui, il y a plus de similitudes que de différences entre les deux et le passage de l'un à l'autre est un processus transparent.
Cloud computing
- AWS et Azure :présentation et comparaison des services
- IoT dans la fabrication :un aperçu détaillé
- GPS vs. RFID :une comparaison des technologies de localisation des actifs
- Comparaison du tour à bois CNC avec le tour à bois traditionnel
- Diviseur de tension capacitif :un guide détaillé
- Comparaison des technologies 3D :SLA et FDM
- Un regard approfondi sur la pompe à eau centrifuge
- Comparaison du rodage et du rodage
- Comparaison des bandes transporteuses minières