


Qu'est-ce que Hadoop ? Traitement de Big Data Hadoop
L'évolution des mégadonnées a créé de nouveaux défis qui ont nécessité de nouvelles solutions. Comme jamais auparavant dans l'histoire, les serveurs doivent traiter, trier et stocker de grandes quantités de données en temps réel.
Ce défi a conduit à l'émergence de nouvelles plates-formes, telles qu'Apache Hadoop, qui peuvent gérer facilement de grands ensembles de données.
Dans cet article, vous apprendrez ce qu'est Hadoop, quels sont ses principaux composants et comment Apache Hadoop aide au traitement du Big Data.
Qu'est-ce qu'Hadoop ?
La bibliothèque logicielle Apache Hadoop est un cadre open source qui vous permet de gérer et de traiter efficacement le Big Data dans un environnement informatique distribué.
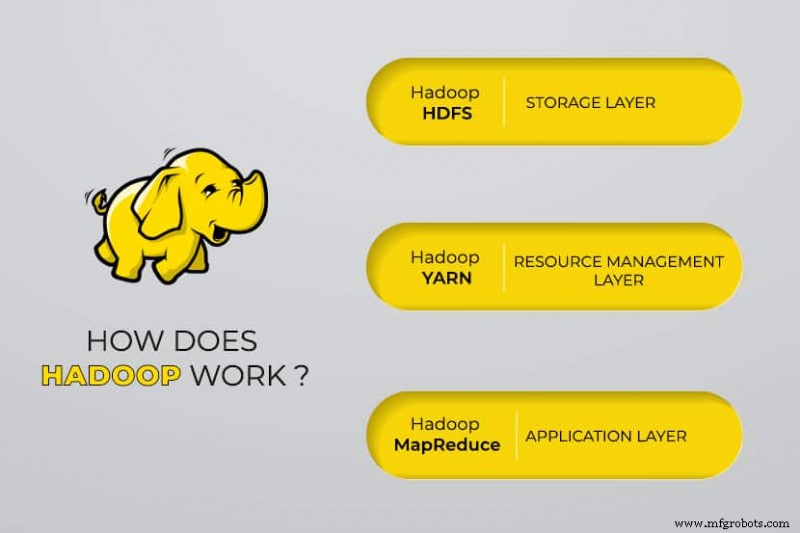
Apache Hadoop se compose de quatre modules principaux :
Système de fichiers distribué Hadoop (HDFS)
Les données résident dans le système de fichiers distribué de Hadoop, qui est similaire à celui d'un système de fichiers local sur un ordinateur typique. HDFS offre un meilleur débit de données par rapport aux systèmes de fichiers traditionnels.
De plus, HDFS offre une excellente évolutivité. Vous pouvez passer d'une seule machine à des milliers avec facilité et sur du matériel de base.
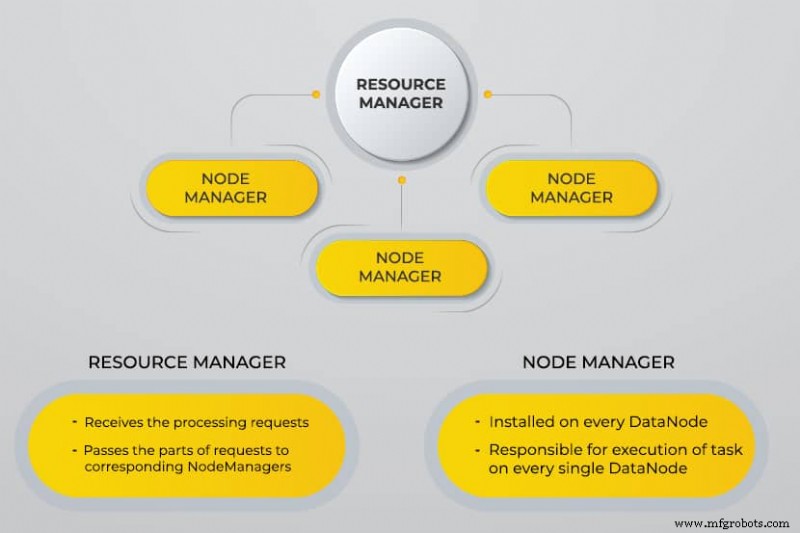
Encore un autre négociateur de ressources (YARN)
YARN facilite les tâches planifiées, la gestion complète et la surveillance des nœuds de cluster et d'autres ressources.
MapReduce
Le module Hadoop MapReduce aide les programmes à effectuer des calculs de données parallèles. La tâche Map de MapReduce convertit les données d'entrée en paires clé-valeur. Réduire les tâches consomment l'entrée, l'agrège et produit le résultat.
Hadoop commun
Hadoop Common utilise des bibliothèques Java standard dans chaque module.
Pourquoi Hadoop a-t-il été développé ?
Le World Wide Web a connu une croissance exponentielle au cours de la dernière décennie et se compose désormais de milliards de pages. La recherche d'informations en ligne est devenue difficile en raison de sa quantité importante. Ces données sont devenues des mégadonnées, et elles se composent de deux problèmes principaux :
- Difficulté à stocker toutes ces données de manière efficace et facile à récupérer
- Difficulté à traiter les données stockées
Les développeurs ont travaillé sur de nombreux projets open source pour renvoyer les résultats de recherche Web plus rapidement et plus efficacement en résolvant les problèmes ci-dessus. Leur solution consistait à répartir les données et les calculs sur un cluster de serveurs pour obtenir un traitement simultané.
Finalement, Hadoop est devenu une solution à ces problèmes et a apporté de nombreux autres avantages, notamment la réduction des coûts de déploiement des serveurs.
Comment fonctionne le traitement du Big Data Hadoop ?
Avec Hadoop, nous utilisons la capacité de stockage et de traitement des clusters et mettons en œuvre un traitement distribué pour le Big Data. Hadoop fournit essentiellement une base sur laquelle vous créez d'autres applications pour traiter le Big Data.
Les applications qui collectent des données dans différents formats les stockent dans le cluster Hadoop via l'API Hadoop, qui se connecte au NameNode. Le NameNode capture la structure du répertoire de fichiers et le placement des "morceaux" pour chaque fichier créé. Hadoop réplique ces morceaux sur les DataNodes pour un traitement parallèle.
MapReduce effectue des requêtes de données. Il cartographie tous les DataNodes et réduit les tâches liées aux données dans HDFS. Le nom, "MapReduce" lui-même décrit ce qu'il fait. Les tâches de carte s'exécutent sur chaque nœud pour les fichiers d'entrée fournis, tandis que les réducteurs s'exécutent pour lier les données et organiser la sortie finale.
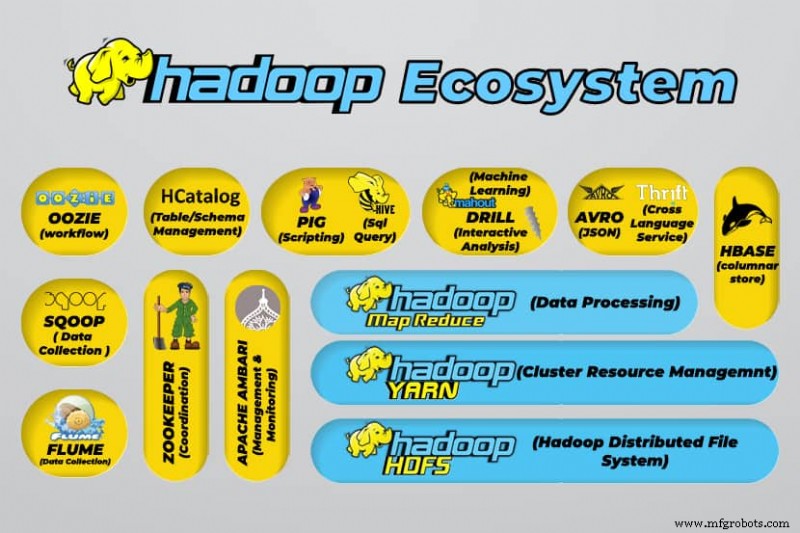
Outils Hadoop Big Data
L'écosystème d'Hadoop prend en charge une variété d'outils de Big Data open source. Ces outils complètent les composants de base de Hadoop et améliorent sa capacité à traiter le Big Data.
Les outils de traitement de données volumineuses les plus utiles incluent :
- Apache Hive
Apache Hive est un entrepôt de données permettant de traiter de grands ensembles de données stockés dans le système de fichiers Hadoop.
- Apache Zookeeper
Apache Zookeeper automatise les basculements et réduit l'impact d'un NameNode défaillant.
- Apache HBase
Apache HBase est une base de données non relationnelle open source pour Hadoop.
- Apache Flume
Apache Flume est un service distribué pour le streaming de grandes quantités de données de journaux.
- Apache Sqoop
Apache Sqoop est un outil de ligne de commande permettant de migrer des données entre Hadoop et des bases de données relationnelles.
- Cochon Apache
Apache Pig est la plate-forme de développement d'Apache pour le développement de travaux qui s'exécutent sur Hadoop. Le langage du logiciel utilisé est Pig Latin.
- Apache Oozie
Apache Oozie est un système de planification qui facilite la gestion des tâches Hadoop.
- Apache HCatalog
Apache HCatalog est un outil de stockage et de gestion de table permettant de trier les données de différents outils de traitement de données.
Avantages de Hadoop
Hadoop est une solution robuste pour le traitement du Big Data et un outil essentiel pour les entreprises qui traitent du Big Data.
Les principales fonctionnalités et avantages de Hadoop sont détaillés ci-dessous :
- Stockage et traitement plus rapides de grandes quantités de données
La quantité de données à stocker a considérablement augmenté avec l'arrivée des médias sociaux et de l'Internet des objets (IoT). Le stockage et le traitement de ces ensembles de données sont essentiels pour les entreprises qui en sont propriétaires. - Flexibilité
La flexibilité d'Hadoop vous permet d'enregistrer des types de données non structurés tels que du texte, des symboles, des images et des vidéos. Dans les bases de données relationnelles traditionnelles comme le SGBDR, vous devrez traiter les données avant de les stocker. Cependant, avec Hadoop, le prétraitement des données n'est pas nécessaire car vous pouvez stocker les données telles quelles et décider comment les traiter ultérieurement. En d'autres termes, il se comporte comme une base de données NoSQL. - Puissance de traitement
Hadoop traite le Big Data via un modèle informatique distribué. Son utilisation efficace de la puissance de traitement le rend à la fois rapide et efficace. - Coût réduit
De nombreuses équipes ont abandonné leurs projets avant l'arrivée de frameworks comme Hadoop, en raison des coûts élevés qu'ils encouraient. Hadoop est un framework open source, il est gratuit et utilise du matériel bon marché pour stocker les données. - Évolutivité
Hadoop vous permet de faire évoluer rapidement votre système sans trop d'administration, en modifiant simplement le nombre de nœuds dans un cluster. - Tolérance aux pannes
L'un des nombreux avantages de l'utilisation d'un modèle de données distribué est sa capacité à tolérer les pannes. Hadoop ne dépend pas du matériel pour maintenir la disponibilité. Si un appareil tombe en panne, le système redirige automatiquement la tâche vers un autre appareil. La tolérance aux pannes est possible car les données redondantes sont conservées en enregistrant plusieurs copies de données dans le cluster. En d'autres termes, la haute disponibilité est maintenue au niveau de la couche logicielle.
Les trois principaux cas d'utilisation
Traitement de mégadonnées
Nous recommandons Hadoop pour de grandes quantités de données, généralement de l'ordre de pétaoctets ou plus. Il est mieux adapté aux quantités massives de données qui nécessitent une énorme puissance de traitement. Hadoop n'est peut-être pas la meilleure option pour une organisation qui traite de petites quantités de données de l'ordre de plusieurs centaines de gigaoctets.
Stocker un ensemble diversifié de données
L'un des nombreux avantages de l'utilisation de Hadoop est qu'il est flexible et prend en charge différents types de données. Que les données se composent de texte, d'images ou de données vidéo, Hadoop peut les stocker efficacement. Les organisations peuvent choisir la manière dont elles traitent les données en fonction de leurs besoins. Hadoop a les caractéristiques d'un lac de données car il offre une flexibilité sur les données stockées.
Traitement parallèle des données
L'algorithme MapReduce utilisé dans Hadoop orchestre le traitement parallèle des données stockées, ce qui signifie que vous pouvez exécuter plusieurs tâches simultanément. Cependant, les opérations conjointes ne sont pas autorisées car elles brouillent la méthodologie standard dans Hadoop. Il intègre le parallélisme tant que les données sont indépendantes les unes des autres.
À quoi sert Hadoop dans le monde réel
Des entreprises du monde entier utilisent les systèmes de traitement de Big Data Hadoop. Quelques-unes des nombreuses utilisations pratiques de Hadoop sont répertoriées ci-dessous :
- Comprendre les exigences des clients
De nos jours, Hadoop s'est avéré très utile pour comprendre les besoins des clients. Les grandes entreprises du secteur financier et des médias sociaux utilisent cette technologie pour comprendre les besoins des clients en analysant les mégadonnées concernant leur activité.
Les entreprises utilisent ces données pour proposer des offres personnalisées aux clients. Vous en avez peut-être fait l'expérience par le biais de publicités diffusées sur des sites de médias sociaux et de commerce électronique en fonction de nos centres d'intérêt et de notre activité sur Internet. - Optimisation des processus métier
Hadoop aide à optimiser les performances des entreprises en analysant mieux leurs transactions et leurs données clients. L'analyse des tendances et l'analyse prédictive peuvent aider les entreprises à personnaliser leurs produits et leurs stocks pour augmenter leurs ventes. Une telle analyse facilitera une meilleure prise de décision et conduira à des profits plus élevés.
De plus, les entreprises utilisent Hadoop pour améliorer leur environnement de travail en surveillant le comportement des employés en collectant des données concernant leurs interactions les uns avec les autres. - Améliorer les services de santé
Les institutions de l'industrie médicale peuvent utiliser Hadoop pour surveiller la grande quantité de données concernant les problèmes de santé et les résultats des traitements médicaux. Les chercheurs peuvent analyser ces données pour identifier les problèmes de santé, prédire les médicaments et décider des plans de traitement. De telles améliorations permettront aux pays d'améliorer rapidement leurs services de santé. - Négoce financier
Hadoop possède un algorithme sophistiqué pour analyser les données du marché avec des paramètres prédéfinis pour identifier les opportunités commerciales et les tendances saisonnières. Les sociétés financières peuvent automatiser la plupart de ces opérations grâce aux puissantes fonctionnalités de Hadoop. - Utiliser Hadoop pour l'IdO
Les appareils IoT dépendent de la disponibilité des données pour fonctionner efficacement. Les fabricants et les inventeurs utilisent Hadoop comme entrepôt de données pour des milliards de transactions. Comme l'IoT est un concept de streaming de données, Hadoop est une solution appropriée et pratique pour gérer les grandes quantités de données qu'il englobe.
Hadoop est mis à jour en permanence, ce qui nous permet d'améliorer les instructions utilisées avec les plates-formes IoT.
D'autres utilisations pratiques de Hadoop incluent l'amélioration des performances de l'appareil, l'amélioration de la quantification personnelle et de l'optimisation des performances, l'amélioration de la recherche sportive et scientifique.
Quels sont les défis liés à l'utilisation de Hadoop ?
Chaque application comporte à la fois des avantages et des défis. Hadoop introduit également plusieurs défis :
- L'algorithme MapReduce n'est pas toujours la solution
L'algorithme MapReduce ne prend pas en charge tous les scénarios. Il convient aux demandes d'informations simples et aux problèmes qui sont regroupés en unités indépendantes, mais pas aux tâches itératives.
MapReduce est inefficace pour le calcul analytique avancé car les algorithmes itératifs nécessitent une intercommunication intensive et il crée plusieurs fichiers dans la phase MapReduce. - Gestion des données entièrement développée
Hadoop ne fournit pas d'outils complets pour la gestion des données, les métadonnées et la gouvernance des données. De plus, il ne dispose pas des outils nécessaires à la normalisation des données et à la détermination de la qualité. - Écart de talents
En raison de la courbe d'apprentissage abrupte de Hadoop, il peut être difficile de trouver des programmeurs débutants avec des compétences Java suffisantes pour être productifs avec MapReduce. Cette intensité est la principale raison pour laquelle les fournisseurs sont intéressés à mettre la technologie de base de données relationnelle (SQL) au-dessus de Hadoop, car il est beaucoup plus facile de trouver des programmeurs ayant de solides connaissances en SQL plutôt que des compétences MapReduce.
L'administration Hadoop est à la fois un art et une science, nécessitant une connaissance de base des systèmes d'exploitation, du matériel et des paramètres du noyau Hadoop. - Sécurité des données
Le protocole d'authentification Kerberos est une étape importante vers la sécurisation des environnements Hadoop. La sécurité des données est essentielle pour protéger les systèmes de Big Data contre les problèmes de sécurité des données fragmentées.
Conclusion
Hadoop est très efficace pour traiter le traitement du Big Data lorsqu'il est mis en œuvre efficacement avec les étapes nécessaires pour surmonter ses défis. C'est un outil polyvalent pour les entreprises qui traitent de grandes quantités de données.
L'un de ses principaux avantages est qu'il peut fonctionner sur n'importe quel matériel et qu'un cluster Hadoop peut être réparti sur des milliers de serveurs. Cette flexibilité est particulièrement importante dans les environnements d'infrastructure en tant que code.
Cloud computing
- Big Data et Cloud Computing :une combinaison parfaite
- Qu'est-ce que la sécurité cloud et pourquoi est-elle obligatoire ?
- Quelle est la relation entre le Big Data et le cloud computing ?
- Utilisation du Big Data et du cloud computing en entreprise
- À quoi s'attendre des plateformes IoT en 2018
- Maintenance prédictive – Ce que vous devez savoir
- Qu'est-ce que la RAM DDR5 exactement ? Fonctionnalités et disponibilité
- Qu'est-ce que l'IIoT ?
- Big Data vs Intelligence Artificielle