


Combiner l'OCR avec l'IA et la RPA pour une analyse avancée des données
Cet article a été co-écrit par Cosmin Nicolae. Nicolae est chef de produit chez UiPath.
Les données non structurées sont partout, se cachant dans des endroits comme des documents, des fichiers audio, des vidéos, des e-mails, des images et des fichiers journaux - la liste est longue. En fait, les données non structurées représentent désormais environ 80 à 90 % de toutes les données. Pourtant, malgré leur abondance et leur valeur, les données non structurées restent l'une des ressources d'entreprise les plus gaspillées, car les entreprises ne disposent pas des outils nécessaires pour les extraire et les analyser.
Cela est en train de changer, car la demande augmente pour l'analyse de données volumineuses et l'automatisation des flux de travail, qui nécessitent toutes deux des données structurées. Un nombre croissant d'entreprises tirent parti d'une technologie appelée reconnaissance optique de caractères (OCR), qui permet de convertir du texte imprimé ou manuscrit en texte codé par machine. En tant que technologie autonome, l'OCR est quelque peu limité (plus de détails ci-dessous). Pourtant, grâce au trifecta de l'OCR, de l'automatisation des processus robotiques (RPA) et de l'intelligence artificielle (IA), les entreprises peuvent permettre des niveaux très avancés de traitement et d'automatisation des données.
L'OCR est l'un des composants clés de deux solutions UiPath :
-
UiPath Document Understanding permettant le traitement automatisé d'un large éventail de documents
-
UiPath AI Computer Vision qui permet aux développeurs d'automatiser sur des bureaux virtuels et dans des interfaces dynamiques
Ce blog fournira un aperçu de l'OCR tout en explorant comment UiPath utilise la technologie pour permettre le traitement et l'analyse des données de nouvelle génération.
Tout d'abord, voici une introduction rapide à l'OCR.
OCR :un aperçu
En termes simples, l'OCR est un processus qui convertit le texte des images en documents modifiables.
L'OCR peut réduire et même éliminer le travail manuel pour certaines tâches. En conséquence, il peut accélérer les flux de travail backend tout en libérant les employés pour qu'ils assument des responsabilités plus importantes.
Voici quelques façons courantes dont les entreprises utilisent l'OCR.
1. Automatisation de la saisie des données
La saisie manuelle des données prend du temps et est sujette aux erreurs. En utilisant l'OCR, les entreprises peuvent numériser les documents tout en minimisant le besoin d'intervention humaine et en augmentant l'intégrité de leurs données.
2. Modification de documents (scannés ou PDF)
Les employés reçoivent souvent des documents numérisés et des notifications par fax qui ne sont pas dans un format modifiable. C'est un cas courant dans des départements tels que les finances, la gestion des approvisionnements, les ressources humaines, le juridique et la conformité. Les scanners traditionnels ne peuvent exporter des documents que sous forme d'images ou de PDF. Par exemple, vous ne pouvez pas numériser un contrat ou un bon de commande, puis le modifier dans Microsoft Word ou Google Docs. Cependant, en utilisant un moteur OCR, il est possible de reconnaître le texte et de l'exporter dans un format lisible par machine pour une édition et un traitement ultérieurs.
3. Aider les employés ayant une déficience visuelle
Les employés malvoyants ont souvent besoin de convertir des documents papier en formats numériques. L'OCR peut vous aider en convertissant le texte écrit en synthèse vocale, ce qui simplifie le processus.
4. Organisation des documents
L'OCR peut trier automatiquement des piles variées de documents et les organiser selon des règles spécifiques. Un exemple classique serait d'organiser les factures en fonction du type ou du fournisseur. Ou dans des processus critiques tels que l'utilisation de l'OCR multiligne (MLOCR) dans une machine de tri du courrier qui analyse les adresses et détermine comment acheminer le courrier via le système postal.
5. Comprendre le texte sur les interfaces
L'OCR permet de traiter les données via des interfaces distantes, ce qui permet aux équipes distantes de collaborer plus rapidement et plus facilement.
Les limites de l'OCR
Bien que l'OCR soit très puissant, il présente plusieurs limites lorsqu'il est utilisé en tant que technologie autonome.
Voici quelques-unes des principales limitations de l'OCR.
1. L'OCR ne peut pas comprendre les données par lui-même
Avant tout, l'OCR ne peut que numériser le texte des documents et le rendre lisible par machine. L'OCR ne peut pas comprendre ou interpréter les données sans un mécanisme complémentaire. En tant que tel, l'OCR est souvent utilisé en tant que composant d'une solution plus vaste et plus intelligente. Pour permettre une véritable automatisation des processus à grande échelle, l'OCR et la RPA sont associés à l'IA.
2. L'OCR manque de contexte
Les systèmes OCR manquent également de contexte. Par exemple, un système OCR peut transcrire un mot sous forme de caution alors que le mot réel est balle. Un moteur OCR en lui-même n'aura pas la capacité cognitive nécessaire pour analyser le reste de la phrase pour voir quel mot doit être utilisé. Pour cette raison, l'OCR en tant que technologie autonome est très sujette aux erreurs. Il nécessite un composant humain dans la boucle pour vérifier l'exactitude des entrées. Par conséquent, l'OCR en soi n'a pas une valeur optimale en tant qu'outil d'automatisation.
3. L'OCR ne peut pas gérer la variabilité
De plus, l'OCR ne peut pas gérer la variabilité du texte ou de la mise en page d'un document, ce qui est un gros problème lors du traitement de documents dont la structure varie.
4. L'OCR ne peut pas séparer les documents
D'autres problèmes peuvent survenir si les fichiers doivent être séparés en documents avant d'être inclus dans un processus d'automatisation ou s'il y a des répétitions dans les champs d'index ou les valeurs clés d'un flux de travail.
5. L'OCR n'est ni précis ni évolutif
En fin de compte, l'OCR pur n'est pas suffisamment précis ou évolutif pour les processus complexes et cognitifs. Les entreprises ont besoin de solutions matures et flexibles, par opposition à des composants limités et sujets aux erreurs.
Comme vous pouvez le voir, l'OCR en tant que technologie autonome n'est pas assez sophistiquée pour prendre en charge les flux de travail d'entreprise avancés d'aujourd'hui. Pourtant, lorsqu'il est combiné avec le logiciel RPA et l'IA, l'OCR peut être un outil extrêmement utile. La section suivante explorera comment UiPath utilise l'OCR pour permettre une automatisation très précise.
Cas d'utilisation :OCR dans UiPath Document Understanding
UiPath Document Understanding utilise la RPA et l'IA pour numériser les données des documents afin qu'elles puissent être traitées et analysées. Document Understanding peut gérer à la fois des données structurées et non structurées, et il fonctionne avec une variété d'objets, comme l'écriture manuscrite, les tableaux, les cases à cocher et les signatures.
La compréhension des documents offre de nombreux avantages, tels qu'un traitement précis et flexible des documents, une efficacité opérationnelle accrue, un risque réduit d'erreur humaine, ainsi que l'automatisation de bout en bout des processus complexes.
Il convient de noter que la technologie de compréhension de documents n'est pas l'OCR. Le fait que les deux ne font qu'un est une idée fausse courante. Au contraire, la compréhension des documents est une technologie avancée qui utilise l'OCR pour numériser le texte des documents non numériques.
Une distinction notable est que UiPath dissocie l'OCR de l'extraction de données. De nombreuses entreprises de cet espace incluent l'OCR avec extraction. En dissociant les deux, UiPath offre plus de choix, de flexibilité et de précision car il devient possible de sélectionner un moteur OCR différent si nécessaire sans perturber ce qui se passe du côté de l'extraction. Il est également possible d'utiliser les contrats publics UiPath OCR pour déployer votre propre moteur OCR si vous le souhaitez.
Comment Document Understanding utilise l'OCR
L'OCR entre en jeu au début du processus de compréhension du document :immédiatement après le chargement de la taxonomie dans le flux de travail et la définition de tous les fichiers et données pour l'extraction.
Document Understanding utilise des moteurs OCR pour détecter et numériser du texte, le rendant lisible par un robot. À partir de là, les documents sont classés à partir de listes spécifiées, les données sont extraites et, si nécessaire, un humain peut confirmer les données extraites avant qu'elles ne soient exportées vers le référentiel approprié.
UiPath Document Understanding peut utiliser UiPath Document OCR propriétaire, ainsi que des moteurs OCR tiers pour numériser le texte. Les clients peuvent choisir le moteur qui fonctionne le mieux pour leur cas d'utilisation.
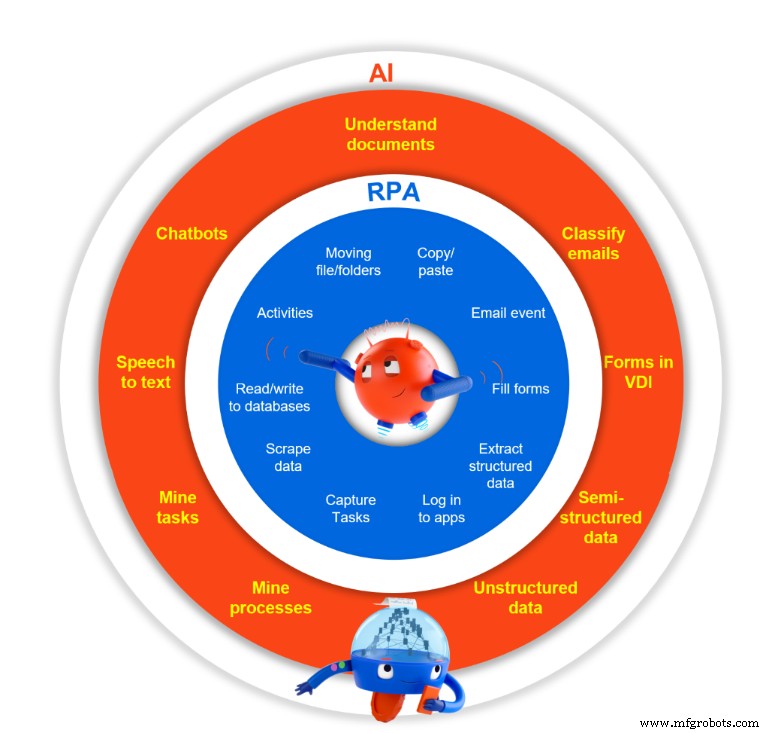
Comme le montre cette figure, l'OCR fait partie du cadre UiPath Document Understanding. Son seul but est de rendre le texte lisible par machine.
Cas d'utilisation :OCR dans UiPath AI Computer Vision
UiPath AI Computer Vision résout l'un des principaux défis de la RPA, qui consiste à automatiser l'infrastructure de bureau virtuel (VDI) comme Citrix, VMware et Microsoft Windows Remote Desktop.
AI Computer Vision permet aux robots logiciels de voir et de comprendre tous les éléments sur un écran d'ordinateur, au lieu de s'appuyer sur des propriétés cachées pour prendre des décisions. Grâce à AI Computer Vision, les entreprises et les développeurs RPA peuvent activer l'automatisation des VDI, quel que soit le framework ou le système d'exploitation.
AI Computer Vision permet une automatisation qui inclut des éléments d'interface utilisateur (UI) dynamiques tels que des menus déroulants et des cases à cocher ; prenant en charge une large gamme de types d'interfaces. Cette solution peut réduire le temps de mise en œuvre lors de l'automatisation des machines virtuelles tout en augmentant la résilience et la fiabilité des automatisations.
Bien que AI Computer Vision utilise l'OCR, il n'est pas utilisé pour numériser des documents. Il s'agit d'une idée fausse subtile mais courante.
Comment UiPath AI Computer Vision utilise l'OCR
Il est impossible d'automatiser dans des environnements virtuels à l'aide d'OCR et de RPA standard, car un poste de travail distant n'est finalement qu'un flux vidéo. Des solutions avancées sont nécessaires pour interpréter le texte et, plus important encore, pour comprendre leur type et leur objectif au sein d'une interface.
AI Computer Vision utilise un réseau neuronal avancé avec un écran OCR personnalisé développé chez UiPath au cours des dernières années pour analyser une interface utilisateur sur un flux de bureau virtuel et la comprendre, comme le ferait un humain. Cette solution peut facilement naviguer dans n'importe quelle interface disponible, en cliquant sur des boutons, mais aussi en effectuant des interactions complexes comme l'extraction de tableaux entiers et l'interaction avec des menus déroulants.
Pour l'identification des éléments, AI Computer Vision utilise une technique d'interprétation de texte appelée correspondance floue. Cette technique permet aux robots UiPath d'identifier l'élément correct à chaque fois, même en cas d'incohérences dans les résultats d'OCR, améliorant ainsi la fiabilité des automatisations résultantes et raccourcissant le temps de développement.
Faites passer l'OCR au niveau supérieur avec UiPath
Comme vous pouvez le constater, l'utilisation d'une solution basée sur l'IA qui intègre l'OCR présente un intérêt considérable. Les outils UiPath Document Understanding et UiPath Computer Vision vont bien au-delà de l'OCR de base, permettant une automatisation rapide et fiable avec une évolutivité d'entreprise, ce qui vous permet de libérer toute la valeur de vos données, y compris ce qui est non structuré ou verrouillé derrière un VDI.
Voici un tableau pour vous aider à décider si Document Understanding ou Computer Vision est adapté à vos besoins :
Prêt à commencer à mettre vos données documentaires et vos systèmes VDI au travail ?
Pour commencer, inscrivez-vous à UiPath Automation Cloud où vous pourrez commencer à utiliser UiPath Document Understanding et UiPath AI Computer Vision dès aujourd'hui.
Démarrez votre essai gratuit d'UiPath Automation Cloud pour découvrir à quel point il est facile d'exploiter vos données non structurées pour apporter plus de structure et d'efficacité à vos processus métier.
Système de contrôle d'automatisation
- Stocker et gérer les données sensibles avec Secret Manager
- Comment les entreprises peuvent tirer parti de l'IoT pour la collecte et l'analyse de données à grande échelle
- Arch Systems s'associe à Flex pour la transformation des données de fabrication
- AIoT industriel :combiner l'intelligence artificielle et l'IoT pour l'industrie 4.0
- Développer de nouvelles voies de croissance des revenus avec l'IIoT pour les équipementiers de l'aérospatiale et de la défense
- Perspective future :IA et analyse de données dans le contrôle des grues
- Litmus et Oden fusionnent les solutions IIoT pour la fabrication intelligente
- 5 minutes avec PwC sur l'IA et le Big Data dans le secteur manufacturier
- Relever le défi de la fabrication grâce aux données et à l'IA