


Si les données sont le nouveau pétrole, qui est votre raffineur ?
Pour les équipes d'entreprise, les données semblent être partout, attendant d'être déverrouillées pour faire avancer vos objectifs commerciaux. Nous nous sommes récemment entretenus avec deux des principales autorités IoT de Nokia - Marc Jadoul, directeur du développement du marché IoT, Denny Lee, responsable de la stratégie analytique - pour discuter de la façon dont les données de votre entreprise pourraient être le pétrole qui la fait avancer.
LireÉcrire : Donc, cette expression - "Les données sont le nouveau pétrole" - est quelque chose que j'ai entendu parler lors de conférences et soulevé à quelques reprises. Mais le truc c'est que le pétrole peut être un carburant, et ça peut aussi être un lubrifiant, dans votre esprit, avec vos clients, qu'est-ce que ça veut dire ?
Marc Jadoul : La façon dont je le regarde, c'est du point de vue de la valeur. Si vous comparez le prix d'un baril de pétrole brut avec le prix d'un baril de carburéacteur, il y a une grande différence. Les données, comme le pétrole, peuvent et doivent passer par un processus de raffinement similaire.
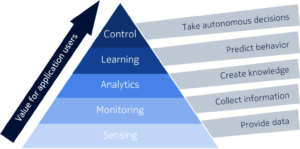
Plus il est raffiné, plus il peut apporter de valeur car, comme le carburant, il prendra en charge des applications plus sophistiquées. Une autre façon de penser à cela est comme une pyramide - si vous commencez au bas de la pyramide, vous collectez essentiellement des données brutes au niveau du capteur. À l'étape suivante, vous commencez à surveiller ces données et commencez à découvrir ce qu'elles contiennent. Vous allez probablement découvrir des anomalies ou des tendances et, sur la base de votre analyse, vous pourrez découvrir des informations critiques qui vous aideront à créer de la valeur pour l'entreprise en favorisant une meilleure prise de décision, ce que l'on appelle la prise de décision basée sur les données (DDDM).
Ensuite, si vous prenez cette décision dans une sorte de phase d'apprentissage basée sur l'analyse cognitive, vous allez non seulement aider à prendre des décisions, mais aussi prédire le comportement. Une fois que vous pouvez prédire le comportement, vous êtes arrivé au point des données les plus raffinées, où les données sont suffisamment pures pour être transformées en connaissances afin d'aider vos machines et applications à prendre des décisions autonomes.
Ce que j'ai décrit est une chaîne de valeur où les données fournissent des informations et des connaissances pour aider les entreprises à prendre de meilleures décisions et, en fin de compte, à automatiser certains processus et prises de décision. Je fais le parallèle avec l'industrie pétrolière, pas comme une métaphore de la fonction lubrifiant (rires ), mais par rapport au processus de raffinement. Plus vous l'affinez, plus il devient utile et plus vous récupérez de valeur.
Denny Lee : Lorsque les gens utilisent la nouvelle expression pétrolière, je repense toujours aux années 1970 :lorsque vous contrôlez le pétrole, vous contrôlez l'économie. Je pense que lorsque l'on dit « les données sont le nouveau pétrole », cela s'enracine dans cette similitude. Les données sont le nouveau pétrole signifie également que si vous êtes en mesure de prendre ce contrôle, vous pouvez mieux contrôler cette économie et votre secteur.
Lorsque j'entends ce terme, cela renvoie également à l'idée que « les données sont la monnaie ». Les données sont assez brutes dans leur forme et les gens utilisent souvent ce terme de manière assez vague. Certains pourraient penser que les données, la perspicacité et l'intelligence font toutes référence à la même chose. Mais en fait, nous faisons une assez grande distinction entre ceux-ci. En fin de compte, nous soutenons que les données sont l'ingrédient brut et nous voulons traiter les données qui conduisent à des idées. Les informations et l'intelligence sont ce dont l'entreprise a besoin. Je suis sûr que nous parlerons plus tard de la façon d'utiliser ces renseignements à des fins commerciales exploitables.
RW : Ainsi, lorsque vous vous asseyez avec un client pour discuter de la façon de l'amener à envisager une innovation basée sur les données au sein de son organisation, quelle est la première chose qu'il doit savoir, la première chose qu'il doit demander ?
MJ : Je pense que la première chose qu'ils doivent faire est de comprendre leur propre entreprise et quels sont les défis et les problèmes qu'ils veulent résoudre. Au lieu du contraire, essayer de trouver un problème pour leur solution. Citant Simon Sinek, il faut commencer par le « pourquoi ? à la place avec le "comment?" ou le « quoi ? » question.
DL : Le résultat commercial est certainement une chose, mais avant cela, vous devez poser la question à qui vous parlez dans l'organisation. Chacun aura une limite organisationnelle ou un domaine de responsabilité différent qui entraînera un ensemble différent de questions.
Par exemple, si vous parlez à un PDG, son bac à sable est énorme. D'un autre côté, vous pourriez parler à une partie cloisonnée de l'organisation où son propre univers est très défini. Ensuite, vous devez comprendre leur contexte commercial et le résultat commercial souhaité. et vous essayez de connecter le problème à une solution. De toute évidence, lorsque nous parlons de contexte analytique, il s'agit de traiter les données au point où elles peuvent générer des résultats commerciaux.
Ensuite, nous devrions éventuellement parler de franchir les frontières de l'organisation. C'est un point très important que nous ne devons pas manquer. Parfois, les pépites d'intelligence ne viennent qu'en brisant les barrières entre les organisations.
RW : Vous avez dit en termes de PDG que vous avez un plus grand bac à sable dans lequel travailler, mais quand je parle à d'autres personnes qui essaient de mettre en œuvre une solution basée sur les données d'une sorte autour de l'IoT, l'idée de qui est le champion au sein de une organisation est souvent au cœur de qui sait vraiment que les défis sont au sein de l'organisation, pouvez-vous dire à quoi ressemblerait un champion organisationnel typique et comment orienter ces objectifs à travers l'organisation ?
DL : Eh bien, dans le contexte de l'IoT, l'organisation peut souvent être divisée en deux domaines. Le côté de la technologie des opérations (OT) et le côté de la technologie de l'information (TI). Côté OT, votre solution peut être ciblée sur la personne qui contrôle l'infrastructure de son entreprise. Selon la personne à qui vous parlez au sein de ce groupe, elle aura des besoins différents.
Prenons l'exemple du client qui se concentre sur la maintenance prédictive. Dans ce cas, il ou elle peut ne disposer que d'un budget pour se concentrer sur la maintenance et utiliser le Big Data et l'apprentissage automatique pour prendre en charge le cycle de maintenance et minimiser les pannes de machine. Il s'agit d'un cas d'utilisation très restreint avec un objectif spécifique. Mais si vous parlez à leur responsable, la portée et le contexte du problème qu'ils essaient de résoudre sont beaucoup plus larges et peuvent dépasser les frontières de l'organisation
MJ : J'aimerais vraiment compléter ce point de vue avec un regard sur une autre partie de l'organisation. Outre les dirigeants qui ont besoin de l'analytique pour prendre de bonnes décisions, je vois l'importance du rôle d'analyste de données émerger dans un certain nombre d'organisations. Ces experts savent comment traiter les données – ou selon la métaphore que nous avons utilisée auparavant :contrôler le processus de raffinement. Nous parlons ici d'un ensemble de compétences différent de celui des informaticiens traditionnels. Ma formation est en informatique et il y a 20 ans, la base de l'enseignement de l'informatique était les mathématiques. Lorsque j'ai examiné le programme 5 à 10 ans plus tard, l'accent s'était déplacé vers les algorithmes et les langages de programmation. Aujourd'hui, mon fils fait son doctorat en IA et, croyez-moi, ces étudiants doivent à nouveau avoir une très solide compréhension des mathématiques et des statistiques. Et n'oublions pas que, étant donné que les data scientists doivent soutenir les décisions commerciales des entreprises, ils doivent également avoir un bon niveau de connaissance du domaine et un sens aigu des affaires.
RW : La boucle est bouclée ?
MJ : Avec les problèmes les plus complexes où vous ne pouvez pas simplement utiliser des données informatiques brutes et des calculs numériques pour faire quelque chose avec les données. Vous avez vraiment besoin de la connaissance du domaine pour savoir ce qui est significatif et ce qui ne l'est pas. Et ce sont les personnes qui font en sorte que cela se produise dans les organisations, car elles jouent un rôle de soutien auprès des décideurs internes, comme l'a décrit Denny.
RW : Nous voyons beaucoup de solutions IoT articulées autour de la quantité massive de données que vous avez ou que vous pourriez analyser. Donc, jusqu'à un certain point, si vous avez cette connaissance des données en interne, c'est très bien, mais si ce n'est pas le cas, y a-t-il un risque de submerger un client et d'offrir trop d'options de données, ont-ils vraiment besoin de ce talent en interne ?
MJ : Cela dépend du type de solutions que vous souhaitez construire, bien sûr. Et là où tu peux filtrer et fixer des seuils sur certaines données, par exemple si tu as une sonde de température sur une installation frigorifique, les seules données que tu souhaites réellement avoir sont les exceptions ou anomalies car si tout y est normal n'est pas nécessaire de se laisser submerger par d'énormes volumes de données normales. Ce qui est donc important, c'est que vous procédiez à une collecte de données intelligente et que vous essayiez de filtrer, de pré-analyser et d'analyser les chiffres le plus tôt possible. Pour démarrer le processus de raffinement aussi près que possible de l'appareil où les données sont générées.
DL : Permettez-moi de partager avec vous un aperçu de notre réflexion. Cela s'applique également à l'IoT. En bref, la façon dont nous regardons l'intelligence des données est similaire à un cerveau humain. Nous conduisons en fait une notion de pile d'intelligence. Si vous pensez cela en termes de votre propre cerveau, il y a des choses qui ont un temps de réponse plus rapide et qui sont plus autonomes. À cette couche, vous traitez les données d'environnement mais avec une portée étroite. Faisons maintenant la similitude avec l'IoT. Les choses se passent d'elles-mêmes et lorsqu'elles nécessitent quelques ajustements de retour d'information, elles prennent une décision autonome et locale.
Dans la couche suivante, il peut y avoir une action de temps de réponse modéré et elle est quelque peu autonome. Et puis il y a la couche supérieure que nous appelons l'intelligence augmentée. Il sert à aider l'humain; parce qu'au plus haut niveau, c'est toujours l'administrateur humain - l'exécutif humain effectuant des changements de politique à plus long terme. Et cette couche augmentée est la couche supérieure du logiciel où elle découvre des informations cachées permettant à l'humain de faire des ajustements meilleurs, différents et à plus long terme.
Donc si vous pensez à ces différentes couches comme faisant partie d'une pile, même si vous y pensez dans un contexte IoT, disons au niveau d'une usine :plus vous êtes proche du bas on parle en termes de robotique où les choses sont automatiques . Et en montant, c'est plus humain; et les logiciels jouent un rôle plus important en termes de découverte d'informations afin que l'humain puisse faire de meilleurs jugements.
MJ : Ce qui est intéressant, c'est que cela se reflète également au niveau des infrastructures. Vous avez probablement entendu parler du cloud de périphérie ou de l'informatique de périphérie multi-accès ou MEC, où vous allez en fait effectuer une partie du traitement des données aussi près que possible de la source. Et c'est pour deux raisons :d'abord, vous voulez réduire la latence dans le réseau et réduire le temps de réponse pour la prise de décision. Deuxièmement, vous ne voulez pas trombone toutes ces énormes quantités de données à travers le cœur de votre cloud. Vous voulez seulement que vos utilisateurs et décideurs s'occupent des vraies choses utiles. Lorsque je dois expliquer l'edge computing, je le décris parfois comme un CDN inversé (réseau de diffusion de contenu).
Jetez un œil à ce que nous avons fait il y a des années lorsque la vidéo à la demande et le streaming en direct sont devenus populaires. Nous avons été soudainement confrontés au problème de ne pas avoir assez de bande passante pour servir chaque utilisateur avec un flux individuel, et avec une possible latence. Ainsi, nous avons rapproché les serveurs de mise en cache de l'utilisateur final sur lesquels nous mettrions le contenu le plus populaire et pourrions effectuer une navigation et un traitement de contenu local, tels que l'avance et le retour rapides, et l'adaptation du contenu. Il s'agissait donc d'une optimisation des ressources de stockage et de calcul en aval. Et aujourd'hui, nous avons un certain nombre d'acteurs sur Internet, par exemple Akamai, qui gagnent beaucoup d'argent avec de tels services de mise en cache et d'optimisation.
Maintenant, si vous regardez l'Internet des objets, le problème n'est pas en termes de quantité de données en aval comme dans la vidéo mais le défi réside dans le nombre de sources de données et dans le volume de données en amont. Parce que vous disposez d'un grand nombre d'appareils IoT générant un nombre considérable d'enregistrements de données et que vous allez réellement mettre en place une sorte de service de mise en cache en amont proche de la source pour collecter les données, effectuez des analyses de bas niveau et assurez-vous que vous n'envoyez que des informations qui ont du sens plus loin dans le cloud pour un traitement et un raffinement ultérieurs, pour utiliser à nouveau la métaphore de l'industrie pétrolière. Et c'est pourquoi j'appelle souvent l'edge computing une sorte de « CDN inversé » car il fournit le même type de fonctions mais utilise une architecture différente et fonctionne sur des flux dans une direction différente.
RW : D'accord, nous avons donc quelqu'un qui veut investir dans un projet de quelque nature que ce soit, généralement quelqu'un a une économie de coûts ou une nouvelle source de revenus, je suppose, mais je pense que le plus souvent, cela semble une décision de ne pas y aller. est le plus souvent motivée par la réduction des coûts ou l'efficacité, ce qui est toujours attrayant dans la plupart des organisations. Pouvez-vous tous les deux donner un exemple d'un processus axé sur les données qui peut débloquer non seulement les économies de coûts, mais peut-être aussi le chemin de décision, comme un exemple chacun ?
MJ : Je pourrais commencer par ce que nous faisons avec notre solution d'analyse vidéo. Il s'agit d'un exemple d'application qui utilise des volumes massifs de données diffusées par ex. caméras de vidéosurveillance en circuit fermé.
Dans les villes, vous avez des centaines ou des milliers de ces caméras qui créent un grand nombre de flux vidéo en direct. Généralement, il n'y a pas assez de personnel pour regarder tous les écrans simultanément, car il serait extrêmement coûteux et inefficace de faire regarder tous ces flux vidéo 24h/24 et 7j/7. Ainsi, la solution de Nokia analyse ces vidéos et recherche des anomalies. Il existe de nombreux exemples de cas d'utilisation, comme une voiture roulant dans la mauvaise direction, des troubles dans un aéroport, des personnes ou des objets faisant des mouvements inhabituels. En fait, nous collectons ces données vidéo et les soumettons à la chaîne de raffinement, traitées par un certain nombre d'algorithmes qui reconnaissent des situations spécifiques et détectent les anomalies. En y ajoutant des capacités d'IA, le système devient autodidacte et peut identifier, alerter et prédire toute sorte de « se produire » qui sort de l'ordinaire. Cela aide à la prise de décision, mais en même temps, c'est aussi une énorme économie car les villes et les entreprises de sécurité n'ont besoin que d'une fraction de la population. Les technologies d'analyse rendent actuellement ce type de solutions de vidéosurveillance possibles et abordables.
RW : D'accord, les yeux humains ne sont pas très évolutifs.
MJ : D'accord, les yeux humains ne sont pas très évolutifs et probablement 99,99% de ce contenu vidéo CCTV n'a pas besoin d'attention. Vous devez donc apprendre à filtrer les données au plus près de la source et ne continuer à travailler qu'avec ce qui est pertinent.
DL : Alors Trevor, je vais aussi vous donner quelques séries d'exemples. Le premier groupe serait celui destiné à accélérer la résolution :comme la maintenance prédictive, la « Next Best Action », dans le domaine des soins prédictifs pour recommander des actions de flux de travail à l'agent de soins et l'analyse automatisée des causes premières. Ces exemples de cas d'utilisation étaient auparavant effectués manuellement. Vous attendez que des défauts se produisent et ensuite vous vous penchez dessus. Avec automatisation et prédiction ; au lieu de cela, certaines solutions d'apprentissage automatique peuvent prédire à l'avance l'apparition potentielle de pannes et vous pouvez minimiser les opérations de maintenance coûteuses pour résoudre le problème après coup.
Un autre ensemble d'exemples se trouve dans la catégorie de l'orientation client avec l'utilisation de l'intelligence artificielle. De nombreux clients sont intéressés par ce sujet car, en fin de compte, ils reconnaissent que leurs concurrents essaient également d'apaiser leurs clients finaux du mieux qu'ils peuvent. Et celui qui peut le faire le mieux gagne la journée. Ainsi, apprécier et comprendre l'expérience client et être capable de prédire cela et de répondre à leurs besoins serait un aspect important de la solution d'analyse de Big Data. Par exemple, dans le contexte des fournisseurs de solutions de mise en réseau et des opérateurs, il serait important de savoir à l'avance qu'une congestion va se produire et d'y réagir. Peut-être qu'avoir des performances bien gérées, mais dégradées, vaut mieux que de ne pas avoir de services du tout dans certaines circonstances. Ainsi, anticiper le problème de l'orientation client est également une forme d'application de l'IA :comprendre leur expérience et agir en conséquence. Le troisième, je dirais, concerne les cas d'utilisation de la réalité augmentée qui séduisent les cadres supérieurs et les responsables des politiques des opérateurs de l'entreprise IoT.
Une autre catégorie de problèmes entrerait dans la catégorie « optimisation ». Si vous regardez un ensemble de résultats commerciaux, vous pouvez définir le problème comme un problème d'optimisation :ce sont mes bacs à sable, voici mes données brutes et mes KPI et c'est ce que je veux optimiser comme objectifs. Le système peut alors être configuré pour l'optimiser. Ceci est lié au point où l'on a la possibilité de briser les silos organisationnels et d'optimiser certains résultats qui étaient auparavant impossibles à découvrir lorsque les organisations sont cloisonnées. Ce type de renseignement attire davantage les responsables exécutifs et politiques des organisations.
Cet article a été produit en partenariat avec Nokia. Il fait partie d'une série d'articles dans lesquels l'équipe de Nokia fournira des conseils d'experts et approfondira l'analyse des données, la sécurité et les plateformes IoT.
Technologie de l'Internet des objets
- Soyez l'expert du cloud dont votre entreprise a besoin
- Comment tirer le meilleur parti de vos données
- Idée fausse n°3 :le cloud est un moyen irresponsable de gérer votre entreprise
- Que dois-je faire avec les données ? !
- Le streaming de données ouvre de nouvelles possibilités à l'ère de l'IoT
- Démocratiser l'IoT
- Utiliser les données IoT pour votre entreprise
- Il est temps de changer :une nouvelle ère à la limite
- Amazon veut les données de votre entreprise par camion… littéralement