


Début des kits de développement de calcul neuromorphique
BrainChip, le fournisseur d'IP de calcul neuromorphique, a lancé deux kits de développement pour son processeur neuromorphique Akida lors de la récente Linley Fall Processor Conference. Les deux kits comprennent le SoC neuromorphique Akida de la société :un kit de développement PC Shuttle x86 et un kit Raspberry Pi basé sur Arm. BrainChip offre les outils aux développeurs travaillant avec son processeur de réseau neuronal à pics dans l'espoir d'obtenir une licence pour son IP. Le silicium Akida est également disponible.
Les technologies neuromorphiques de BrainChip permettent une IA ultra basse consommation pour analyser les données dans les systèmes de périphérie où un traitement en temps réel extrêmement basse consommation des données des capteurs est recherché. La société a développé une unité de traitement neuronal (NPU) conçue pour traiter les réseaux neuronaux à pics (SNN), un réseau neuronal inspiré du cerveau qui diffère des approches traditionnelles d'apprentissage en profondeur. Comme le cerveau, un SNN repose sur des « pointes » qui transmettent des informations spatialement et temporellement. C'est-à-dire que le cerveau reconnaît à la fois les séquences et le moment des pics. Appelés « domaine des événements », les pics résultent généralement de modifications des données du capteur (par exemple, des modifications des couleurs des pixels dans une caméra basée sur les événements).
En plus des SNN, les NPU de BrainChip peuvent également traiter des réseaux de neurones convolutifs (CNN) comme ceux généralement utilisés dans les algorithmes de vision par ordinateur et de repérage de mots clés à une puissance inférieure à celle des autres implémentations de périphérie. Cela se fait en convertissant les CNN en SNN et en exécutant l'inférence dans le domaine de l'événement. L'approche permet également un apprentissage sur puce à la périphérie, une qualité de SNN qui serait étendue aux CNN convertis.

Les cartes de développement BrainChip sont disponibles pour les Shuttle PC x86 ou Raspberry Pi. (Source :BrainChip)
Akida "est prêt pour la technologie neuromorphique de demain, mais il résout le problème d'aujourd'hui consistant à rendre possible l'inférence de réseau neuronal sur les appareils périphériques et IoT", a déclaré Anil Mankar, co-fondateur et directeur du développement de BrainChip, à EE Times .
La conversion de CNN vers le domaine de l'événement est effectuée par le flux d'outils logiciels de BrainChip, MetaTF. Les données peuvent être converties en pics, et les modèles entraînés peuvent être convertis pour s'exécuter sur le NPU de BrainChip.
"Notre logiciel d'exécution élimine la peur de" Qu'est-ce qu'un SNN ? « Nous faisons tout pour cacher cela.
« Les personnes qui connaissent l'API TensorFlow ou Keras… peuvent utiliser l'application qu'elles exécutent sur [autre matériel], même réseau, même ensemble de données, avec notre formation à la quantification, et l'exécuter sur notre matériel et mesurer la puissance elles-mêmes et voir quelle sera la précision. »
Les CNN sont particulièrement efficaces pour extraire des caractéristiques de grands ensembles de données, a expliqué Mankar, et la conversion vers le domaine des événements préserve cet avantage. L'opération de convolution est réalisée dans le domaine des événements pour la plupart des couches, mais la couche finale est remplacée. Le remplacer par une couche qui reconnaît les pics entrants donne au CNN par ailleurs ordinaire la possibilité d'apprendre via la plasticité dépendante du timing des pics à la périphérie, éliminant ainsi le recyclage dans le cloud.
Alors que les SNN natifs (ceux écrits à partir de zéro pour le domaine de l'événement) peuvent utiliser une précision d'un bit, les CNN convertis nécessitent des pointes de 1, 2 ou 4 bits. L'outil de quantification de BrainChip aide les concepteurs à décider de l'agressivité de la quantification couche par couche. Brainchip a quantifié MobileNet V1 pour une classification de 10 objets avec une précision de prédiction de 93,1 % après quantification sur 4 bits.
Un sous-produit de la conversion vers le domaine des événements est une économie d'énergie importante due à la rareté. Les valeurs de carte d'activation non nulles sont représentées comme des événements de 1 à 4 bits, et la NPU n'effectue le calcul que sur les événements plutôt que sur la carte d'activation entière.
Les développeurs "peuvent regarder les poids et voir les poids non nuls, et essayer d'éviter de multiplier par des poids nuls", a déclaré Mankar. « Mais cela signifie que vous devez savoir où se trouvent les zéros et des calculs sont nécessaires » pour ces opérations.
Pour un CNN typique, la carte d'activation changerait à chaque image vidéo puisque les fonctions ReLU sont centrées autour de zéro - généralement la moitié des activations seront zéro. En ne faisant pas de pics à partir de ces zéros, le calcul dans le domaine des événements est limité à des activations non nulles. La conversion des CNN pour qu'ils s'exécutent dans le domaine des événements peut tirer parti de la rareté, réduisant rapidement le nombre d'opérations MAC requises pour l'inférence et, par conséquent, la consommation d'énergie.
Parmi les fonctions pouvant être converties dans le domaine des événements, citons la convolution, la convolution point par point, la convolution par profondeur, le regroupement maximal et le regroupement moyen global.
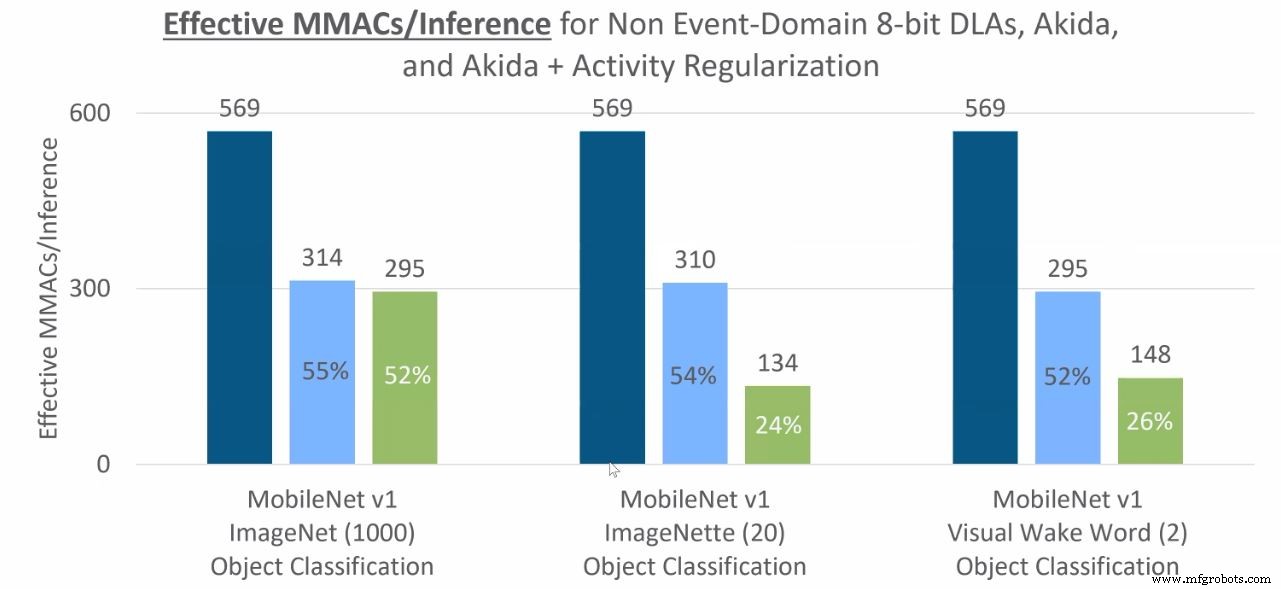
Opérations MAC requises pour l'inférence de classification d'objets (le bleu foncé correspond au CNN dans le domaine non événementiel, le bleu clair correspond au domaine événementiel/Akida, le vert correspond au domaine événementiel avec une régularisation d'activité supplémentaire). (Source :BrainChip)
Dans un exemple, un modèle de détection de mots-clés exécuté sur la carte de développement Akida après une quantification à 4 bits n'a consommé que 37 µJ par inférence (ou 27 336 inférences par seconde et par Watt). La précision des prédictions était de 91,3 % et la puce a été ralentie à 5 MHz pour atteindre les performances observées. (voir graphique ci-dessous).
Agnostique du capteur
L'IP NPU de BrainChip et la puce Akida sont indépendants du type de réseau et peuvent être utilisés avec la plupart des capteurs. Le même matériel peut traiter les données image et audio en utilisant la conversion CNN, ou les SNN de BrainChip pour la détection olfactive, gustative et vibratoire/tactile.
Les NPU sont regroupés en nœuds de quatre, qui communiquent via un réseau maillé. Chaque NPU comprend le traitement et 100 Ko de SRAM locale pour les paramètres, les activations et les tampons d'événements internes. Les couches réseau CNN ou SNN sont affectées à une combinaison de plusieurs NPU, transmettant des événements entre les couches sans prise en charge du processeur. (Alors que les réseaux autres que les CNN peuvent être convertis dans le domaine de l'événement, Mankar a déclaré qu'ils nécessitent un processeur pour fonctionner sur Akida.)
L'IP NPU de BrainChip peut être configurée pour jusqu'à 20 nœuds, et des réseaux plus importants peuvent être exécutés en plusieurs passes sur des conceptions avec moins de nœuds.
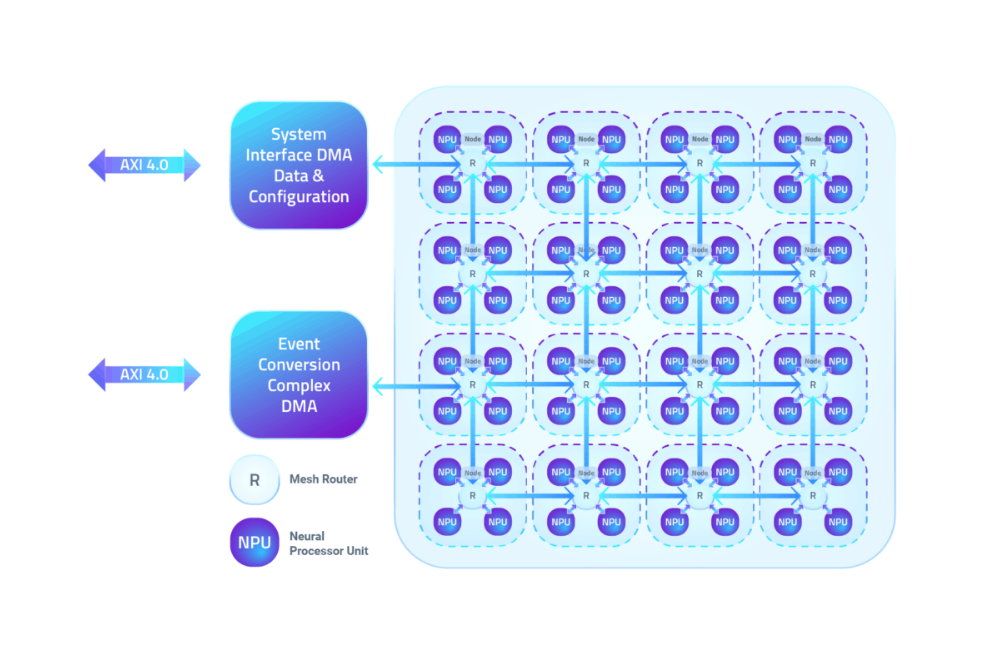
Les nœuds de quatre NPU BrainChip sont connectés par un réseau maillé. (Source :BrainChip)
Une vidéo BrainChip a montré une puce Akida déployée dans un système embarqué dans un véhicule, avec une puce utilisée pour détecter un conducteur, reconnaître le visage du conducteur et identifier sa voix simultanément. Le repérage des mots clés nécessitait 600 µW, la reconnaissance faciale 22 mW et l'inférence visuelle des mots de réveil utilisée pour détecter le conducteur était de 6 à 8 mW.
La faible consommation d'énergie de ces plates-formes automobiles offre une flexibilité aux constructeurs automobiles dans d'autres domaines, a déclaré Rob Telson, vice-président des ventes mondiales de BrainChips, ajoutant que la puce Akida est basée sur la technologie de traitement 28 nm de Taiwan Semiconductor Manufacturing Co. Les clients IP peuvent accéder à des nœuds de processus plus fins pour économiser plus d'énergie, a ajouté Telson.
Pendant ce temps, les systèmes de reconnaissance faciale peuvent apprendre de nouveaux visages sur puce, sans passer au cloud. Une sonnette intelligente pourrait, par exemple, identifier le visage d'une personne localement à partir d'un apprentissage ponctuel. À condition que la dernière couche des réseaux se voit attribuer un nombre suffisant de neurones, le nombre total de visages reconnus pourrait être augmenté de 10 à plus de 50, a noté Mankar.
Clients à accès anticipé
BrainChip compte 55 employés répartis dans son siège social d'Aliso Viejo, en Californie, et dans ses bureaux de conception à Toulouse, en France, à Hyderabad, en Inde, et à Perth, en Australie. La société possède 14 brevets et est cotée à la bourse australienne et à la bourse de gré à gré américaine.
Environ 15 clients à accès anticipé, dont la NASA, a déclaré Telson. D'autres incluent des sociétés automobiles, militaires, aérospatiales, médicales (détection olfactive de Covid-19) et d'électronique grand public. BrainChip cible les applications grand public telles que la santé intelligente, la ville intelligente, la maison intelligente et le transport intelligent.
Un autre client de la première heure est le spécialiste des microcontrôleurs Renesas, qui a obtenu une licence IP Akida NPU à 2 nœuds à intégrer à un futur MCU destiné à l'analyse des données de capteurs dans les déploiements IoT, selon Telson.
Akida IP et le silicium sont disponibles dès maintenant.
>> Cet article a été initialement publié sur notre site frère, EE Times.
Contenus associés :
- La startup emballe 1 000 cœurs RISC-V dans une puce d'accélérateur d'IA
- La puce IA cible les appareils de périphérie à faible consommation
- Les SoC compatibles avec l'IA gèrent plusieurs flux vidéo
- Intégrer la sécurité dans un SoC AI à l'aide de fonctionnalités de processeur avec des extensions
- Les architectures de microcontrôleurs évoluent pour l'IA
Pour plus d'informations sur Embedded, abonnez-vous à la newsletter hebdomadaire d'Embedded.
Embarqué
- Guide du cloud computing sous Linux
- 10 avantages du cloud computing en 2020
- Cloud computing vs sur site
- Groupes d'indicateurs d'événement :introduction et services de base
- Présentation des arguments en faveur des puces neuromorphiques pour l'IA informatique
- Kontron :nouveau standard de calcul embarqué COM HPC
- Les kits de développement à faible coût accélèrent le développement LoRaWAN
- Le kit de développement simplifie le réseau maillé BLE
- Les kits de développement utilisent un capteur d'image 1 x 1 mm