


2017 est-elle l'année de l'interface vocale ?
Au cours des dernières années, des avancées significatives dans la reconnaissance automatique de la parole (ASR) ont conduit à une abondance d'appareils et d'applications qui utilisent la parole comme interface principale. Le Spectre IEEE le magazine a déclaré 2017 l'année de la reconnaissance vocale; ZDNet a rapporté du CES 2017 que la voix est la prochaine interface informatique; et bien d'autres partagent des points de vue similaires. Alors, où en sommes-nous en ce qui concerne l'avancement des interfaces vocales ? Cet article examinera l'état actuel des interfaces vocales et de leurs technologies habilitantes.
Combien de vos appareils communiquent avec vous ?
L'activation vocale est partout autour de nous. Presque tous les smartphones ont une interface vocale, avec des produits phares comme l'Apple iPhone 7 et le Samsung Galaxy S7, y compris des fonctionnalités d'écoute permanente. La plupart des montres connectées offrent une activation vocale, ainsi que d'autres appareils portables, et en particulier des appareils auditifs, comme les AirPods d'Apple et le Gear IconX de Samsung. Dans la plupart de ces appareils, il n'existe aucun moyen pratique d'intégrer une autre interface, faisant de la voix une solution idéale et nécessaire. Les nouvelles caméras, comme la GoPro Hero 5, peuvent être utilisées à l'aide de commandes vocales, ce qui est idéal pour les selfies. Les systèmes d'infodivertissement de voiture activés par la voix sont devenus une marchandise, ce qui rend le changement de station beaucoup plus sûr pendant la conduite.
L'Amazon Echo a déclenché la tendance de l'assistant conversationnel, qui est en feu avec Google Home essayant de lutter et une variété de clones similaires présentés au CES 2017. Le service vocal de l'Echo, nommé Alexa, est livré avec plusieurs compétences intégrées. Par exemple, vous pouvez dire "Alexa, raconte-moi une blague" (livraison très ironique), « Alexa, les Warriors ont-ils gagné ? » (bien sûr qu'ils l'ont fait), ou "Alexa, qui a joué dans le film 2001 :A Space Odyssey ?" (personne d'autre ne semble le savoir). Il y a aussi un tas d'œufs de Pâques amusants, comme la réponse lorsque vous dites « Alexa, lancez une séquence d'autodestruction ». (voir aussi cette vidéo montrant certains des œufs de Pâques d'Alexa).
En plus des fonctions intégrées, de nouvelles fonctionnalités peuvent être ajoutées à Alexa par des tiers à l'aide du kit de compétences Alexa (ASK). Cette ASK permet aux développeurs d'enseigner de nouvelles compétences à Alexa afin qu'elle (ou elle ?) puisse contrôler et interagir avec plus de produits et services. Comme vous pouvez le voir dans cette vidéo, par exemple, une personne a piraté son iRobot Roomba et a ajouté une compétence pour contrôler le robot aspirateur.
Les autres compétences d'Alexa incluent des choses utiles, comme commander de la nourriture dans une variété de restaurants ou héler un Uber, et des divertissements aléatoires, comme poser des questions magiques à 8 boules, des anecdotes sur Seinfeld et apprendre de nouveaux faits sur les fruits. Les collaborations entre Amazon et des entreprises comme Whirlpool et GE renforceront également les aptitudes d'Alexa dans la maison intelligente, en ajoutant des capacités pour contrôler les appareils ménagers comme les machines à laver, les réfrigérateurs, les lampes, etc.
Actuellement, Amazon semble être en tête sur ce marché, mais d'autres font d'énormes efforts (et investissements) pour rattraper leur retard. Mark Zuckerberg a recruté Morgan Freeman pour être la voix de son assistant vocal d'intelligence artificielle (IA). Selon une note décrivant comment il l'a construit, Zuckerberg a passé un an à développer l'application en tant que simple IA pour l'aider à gérer sa maison "comme Jarvis dans Iron Man" (il l'a aussi appelé Jarvis). Jarvis identifie soi-disant qui parle par sa voix, et reconnaît également les visages, de sorte qu'il peut laisser les personnes autorisées entrer à la porte tout en faisant rapport à Zuckerberg.
Un autre concurrent intéressant est un appareil japonais de type Amazon-Echo appelé Gatebox, qui présente un personnage holographique nommé Azuma Hikari.

La réponse du Japon à l'Amazon Echo (Source :Gatebox)
En plus d'un simple haut-parleur, l'appareil utilise un écran et un projecteur pour donner vie à l'assistant virtuel de manière visuelle et audible. En plus des microphones, il dispose également de caméras et de capteurs de mouvement et de température qui lui permettent d'interagir avec l'utilisateur de manière plus globale.
Comment fonctionne cette prise de voix en champ lointain ?
Comment un appareil écoute-t-il et comprend-il vos commandes vocales tout en jouant de la musique de l'autre côté de la pièce ? De nombreux composants sont impliqués dans la réalisation de cet exploit, mais certains d'entre eux sont primordiaux. Le premier est le moteur de reconnaissance vocale automatique (ASR), qui permet aux machines de convertir les sons que nous produisons en instructions exécutables. Pour que le moteur ASR fonctionne correctement, il doit recevoir un échantillon de voix propre. Cela nécessite une réduction du bruit et une annulation d'écho, pour filtrer les interférences. Voici quelques-unes des technologies les plus importantes permettant de capter la voix en champ lointain :
Apprentissage approfondi a un rôle énorme dans cela. La capacité de comprendre le langage naturel a été établie il y a quelques années, mais des améliorations récentes l'ont rapprochée de la capacité humaine. En utilisant des techniques basées sur l'apprentissage telles que les réseaux de neurones profonds (DNN), le traitement du langage et la reconnaissance visuelle d'objets ont égalé ou dépassé les performances humaines dans de nombreux cas de test. Les DNN sont générés à l'aide d'ensembles de données massifs pendant la phase d'apprentissage. Une fois la formation effectuée hors ligne, les DNN sont utilisés pour exécuter leur fonction en temps réel.
Formation de faisceau adaptative est la clé d'une interface utilisateur robuste à commande vocale. Il active des fonctionnalités telles que la réduction du bruit, le suivi des haut-parleurs au cas où l'utilisateur se déplace pendant qu'il parle et la séparation des haut-parleurs lorsque plusieurs utilisateurs parlent simultanément.
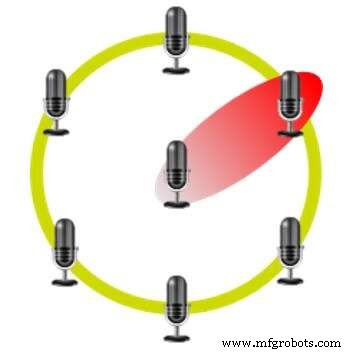
Beamforming à l'aide d'un réseau de microphones hexagonaux (Source :CEVA)
Cette méthode utilise plusieurs microphones dans des positions fixes les uns par rapport aux autres. Par exemple, l'Amazon Echo utilise sept microphones dans une disposition hexagonale avec un microphone à chaque sommet et un au centre. Le délai entre la réception du signal dans les différents microphones permet à l'appareil d'identifier d'où vient la voix et d'annuler les sons provenant d'autres directions.
Annulation d'écho acoustique est nécessaire car de nombreux produits effectuant la reconnaissance automatique de la parole produisent également des sons eux-mêmes ; par exemple, jouer de la musique ou fournir des informations. Même lors de l'exécution de ces actions, les appareils doivent être capables d'entendre afin que l'utilisateur puisse interrompre (intervention) et arrêter la musique ou demander une action différente. Pour continuer à écouter, la machine doit être capable d'annuler le son qu'elle génère elle-même. C'est ce qu'on appelle l'annulation d'écho acoustique (AEC).
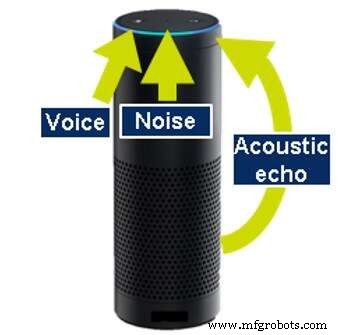
Annulation d'écho acoustique (Source :CEVA)
Pour effectuer l'AEC, l'appareil doit être conscient du son qu'il produit, soit en analysant les données de sortie, soit en écoutant les sons générés avec un microphone dédié supplémentaire. Une technologie similaire est également appliquée pour supprimer les échos qui rebondissent sur les murs et autres objets autour de l'appareil.

Une plate-forme de développement multi-microphones pour la modélisation d'algorithmes de DNN, de formation de faisceau et d'annulation d'écho (Source :CEVA)
Un autre type d'écho est généré par les commandes de l'utilisateur elles-mêmes lorsqu'elles rebondissent sur des objets ou sur les murs. L'annulation de ces échos imprévisibles nécessite encore un autre algorithme appelé déréverbération. Le son est ensuite filtré et la machine peut écouter les commandes de l'utilisateur.
Les interfaces vocales d'aujourd'hui sont loin d'être parfaites
D'une part, 2017 s'annonce comme une année marquante pour les interfaces vocales compte tenu de leur généralisation. D'un autre côté, même avec toutes les avancées impressionnantes de ces dernières années, il reste encore un long chemin à parcourir.
Il reste de nombreux problèmes avec les implémentations actuelles des interfaces vocales dans les appareils produits en série, mais ce sera le sujet d'une future chronique. Dans mon prochain article, je prévois d'examiner certains des défauts et fonctionnalités manquantes qui affligent les interfaces vocales d'aujourd'hui. Assurez-vous de vous connecter.
Eran Belaish est responsable marketing produit de la gamme de produits audio et vocaux de CEVA, concoctant des solutions exquises allant du déclenchement vocal et de la voix mobile à l'audio sans fil et à l'audio domestique haute définition. Bien qu'il ne soit pas occupé par le monde fascinant du son immersif, Eran aime plonger dans le silence envoûtant du monde sous-marin.
Embarqué
- Le PDG de Monroe Engineering est finaliste du prix Entrepreneur de l'année par EY
- L'interface de ligne de commande
- MajorTom :Alexa Voice Controlled ARDrone 2.0
- Motion nommé fournisseur de l'année
- Mobius remporte le prix du produit de l'année
- 2020 sera l'année de l'intelligence continue
- Tendances GMAO 2019 :l'année du client
- Monroe a remporté l'entreprise de l'année 2019 !
- La grande cuisine du chili du Wisconsin