


Comment créer un encodeur variationnel avec TensorFlow
Découvrez les éléments clés d'un autoencodeur, comment un autoencodeur variationnel l'améliore et comment créer et entraîner un autoencodeur variationnel à l'aide de TensorFlow.
Au fil des ans, nous avons vu de nombreux domaines et industries tirer parti de la puissance de l'intelligence artificielle (IA) pour repousser les limites de la recherche. La compression et la reconstruction des données ne font pas exception, où l'application de l'intelligence artificielle peut être utilisée pour créer des systèmes plus robustes.
Dans cet article, nous allons examiner un cas d'utilisation très populaire de l'IA pour compresser des données et reconstruire les données compressées avec un encodeur automatique.
Applications d'encodeur automatique
Les auto-encodeurs ont attiré l'attention de nombreuses personnes dans le domaine de l'apprentissage automatique, un fait mis en évidence par l'amélioration des auto-encodeurs et l'invention de plusieurs variantes. Ils ont donné des résultats prometteurs (sinon de pointe) dans plusieurs domaines tels que la traduction automatique neuronale, la découverte de médicaments, le débruitage d'images et plusieurs autres.
Pièces de l'encodeur automatique
Les auto-encodeurs, comme la plupart des réseaux de neurones, apprennent en propageant des gradients vers l'arrière pour optimiser un ensemble de poids, mais la différence la plus frappante entre l'architecture des auto-encodeurs et celle de la plupart des réseaux de neurones est un goulot d'étranglement. Ce goulot d'étranglement est un moyen de compresser nos données dans une représentation de dimensions inférieures. Deux autres parties importantes d'un auto-encodeur sont l'encodeur et le décodeur.
La fusion de ces trois composants ensemble forme un auto-encodeur "vanille", bien que les plus sophistiqués puissent avoir des composants supplémentaires.
Examinons ces composants indépendamment.
Encodeur
Il s'agit de la première étape de la compression et de la reconstruction des données et elle prend en charge l'étape de compression des données. L'encodeur est un réseau de neurones à anticipation qui prend en charge les caractéristiques des données (telles que les pixels dans le cas de la compression d'image) et génère un vecteur latent d'une taille inférieure à la taille des caractéristiques des données.
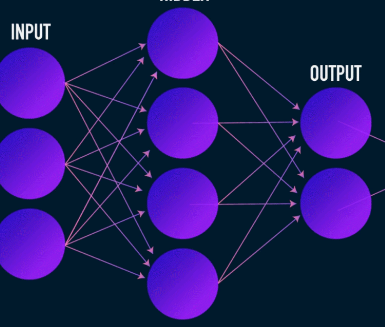
Image utilisée avec l'aimable autorisation de James Loy
Pour rendre la reconstruction des données robuste, l'encodeur optimise ses poids pendant l'apprentissage pour compresser les caractéristiques les plus importantes de la représentation des données d'entrée dans le vecteur latent de petite taille. Cela garantit que le décodeur dispose de suffisamment d'informations sur les données d'entrée pour reconstruire les données avec une perte minimale.
Vecteur latent (goulot d'étranglement)
Le goulot d'étranglement ou la composante vectorielle latente de l'autoencodeur est la partie la plus cruciale, et il devient encore plus crucial lorsque nous devons sélectionner sa taille.
La sortie de l'encodeur est ce qui nous donne le vecteur latent et est censé contenir les représentations de caractéristiques les plus importantes de nos données d'entrée. Il sert également d'entrée à la partie décodeur et propage la représentation utile au décodeur pour la reconstruction.
Choisir une taille plus petite pour le vecteur latent signifie que nous obtenons une représentation des caractéristiques des données d'entrée avec moins d'informations sur les données d'entrée. Le choix d'une taille de vecteur latent beaucoup plus grande minimise en quelque sorte l'idée de compression avec des encodeurs automatiques et augmente également le coût de calcul.
Décodeur
Cette étape conclut notre processus de compression et de reconstruction des données. Tout comme l'encodeur, ce composant est également un réseau de neurones à anticipation, mais sa structure est légèrement différente de l'encodeur. Cette différence vient du fait que le décodeur prend en entrée un vecteur latent de plus petite taille que celui de la sortie du décodeur.
La fonction du décodeur est de générer une sortie à partir du vecteur latent qui est très proche de l'entrée.
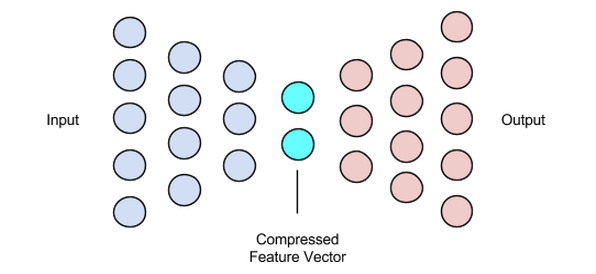
Image utilisée avec l'aimable autorisation de Chiman Kwan
Entraînement d'encodeurs automatiques
Habituellement, lors de la formation d'encodeurs automatiques, nous construisons ces composants ensemble au lieu de les construire indépendamment. Nous les formons de bout en bout avec un algorithme d'optimisation tel que la descente de gradient ou l'optimiseur ADAM.
Fonctions de perte
Une partie de la procédure d'apprentissage de l'autoencodeur qui mérite d'être discutée est la fonction de perte. La reconstruction des données est une tâche de génération et, contrairement à d'autres tâches d'apprentissage automatique où notre objectif est de maximiser la probabilité de prédire la classe correcte, nous conduisons notre réseau à produire une sortie proche de l'entrée.
Nous pouvons atteindre cet objectif avec plusieurs fonctions de perte telles que l1, l2, l'erreur quadratique moyenne et quelques autres. Ce que ces fonctions de perte ont en commun, c'est qu'elles mesurent la différence (c'est-à-dire dans quelle mesure ou identique) entre l'entrée et la sortie, ce qui en fait un choix approprié.
Réseaux d'autoencodeur
Pendant tout ce temps, nous avons utilisé un perceptron multicouche pour concevoir à la fois notre encodeur et notre décodeur, mais il s'avère que nous pouvons utiliser des cadres plus spécialisés tels que les réseaux de neurones convolutifs (CNN) pour capturer plus d'informations spatiales sur nos données d'entrée dans le cas de la compression de données d'image.
Étonnamment, la recherche a montré que les réseaux récurrents utilisés comme auto-encodeurs pour les données textuelles fonctionnent très bien, mais nous n'allons pas en parler dans le cadre de cet article. Le concept d'un vecteur-décodeur encodeur latent utilisé dans le perceptron multicouche est toujours valable pour les autoencodeurs convolutifs. La seule différence est que nous concevons le décodeur et l'encodeur avec des couches convolutives.
Tous ces réseaux d'encodeur automatique fonctionneraient plutôt bien pour la tâche de compression, mais il y a un problème.
Les réseaux dont nous avons parlé n'ont aucune créativité. Ce que j'entends par zéro créativité, c'est qu'ils ne peuvent générer que des résultats qu'ils ont vus ou avec lesquels ils ont été formés.
Nous pouvons induire un certain niveau de créativité en peaufinant un peu la conception de notre architecture. Le résultat est connu sous le nom d'encodeur variationnel.
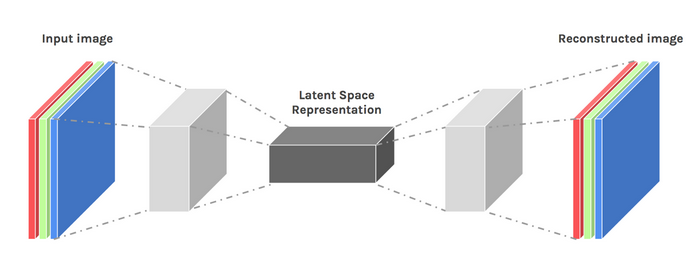
Image utilisée avec l'aimable autorisation de Dawid Kopczyk
Autoencodeur variationnel
L'autoencodeur variationnel introduit deux changements de conception majeurs :
- Au lieu de traduire l'entrée en un codage latent, nous sortons deux vecteurs de paramètres :la moyenne et la variance.
- Un terme de perte supplémentaire appelé perte de divergence KL est ajouté à la fonction de perte initiale.
L'idée derrière l'autoencodeur variationnel est que nous voulons que notre décodeur reconstruise nos données en utilisant des vecteurs latents échantillonnés à partir de distributions paramétrées par un vecteur moyen et un vecteur de variance générés par l'encodeur.
Les fonctions d'échantillonnage d'une distribution accordent au décodeur un espace contrôlé à partir duquel générer. Après avoir entraîné un autoencodeur variationnel, chaque fois que nous effectuons une passe avant avec des données d'entrée, l'encodeur génère un vecteur de moyenne et de variance chargé de déterminer la distribution à partir de laquelle échantillonner le vecteur latent.
Le vecteur moyen détermine l'endroit où l'encodage d'une donnée d'entrée doit être centré et la variance détermine l'espace radial ou le cercle à partir duquel nous voulons sélectionner l'encodage afin de générer une sortie réaliste. Cela signifie qu'à chaque passage avant avec les mêmes données d'entrée, notre auto-encodeur variationnel peut générer différentes variantes de la sortie centrées autour du vecteur moyen et dans l'espace de variance.
À titre de comparaison, lorsque nous regardons un auto-encodeur standard, lorsque nous essayons de générer une sortie sur laquelle le réseau n'a pas été formé, il génère des sorties irréalistes en raison de la discontinuité dans l'espace vectoriel latent produit par l'encodeur.
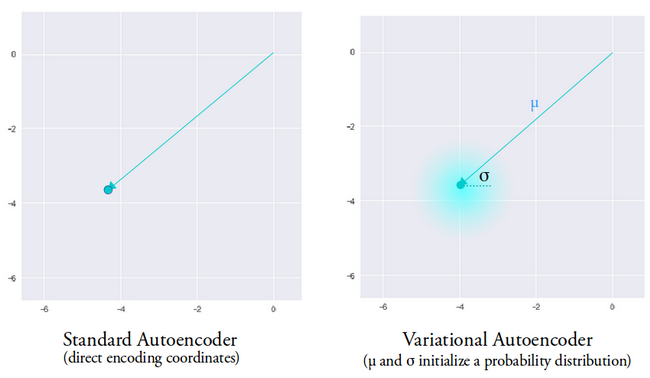
Image utilisée avec l'aimable autorisation d'Irhum Shafkat
Maintenant que nous avons une compréhension intuitive d'un auto-encodeur variationnel, voyons comment en créer un dans TensorFlow.
Code TensorFlow pour un autoencodeur variationnel
Nous allons commencer notre exemple en préparant notre ensemble de données. Par souci de simplicité, nous utiliserons l'ensemble de données MNIST.
(train_images, _), (test_images, _) =tf.keras.datasets.mnist.load_data()
train_images =train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
test_images =test_images.reshape(test_images.shape[0], 28, 28, 1).astype('float32')
# Normalisation des images à la plage de [0., 1.]
train_images /=255.
test_images /=255.
# Binarisation
train_images[train_images>=.5] =1.
train_images[train_images <.5] =0.
test_images[test_images>=.5] =1.
test_images[test_images <.5] =0.
TRAIN_BUF =60000
BATCH_SIZE =100
TEST_BUF =10000
train_dataset =tf.data.Dataset.from_tensor_slices(train_images).shuffle(TRAIN_BUF).batch(BATCH_SIZE)
test_dataset =tf.data.Dataset.from_tensor_slices(test_images).shuffle(TEST_BUF).batch(BATCH_SIZE)
Obtenez l'ensemble de données et préparez-le pour la tâche.
classe CVAE(tf.keras.Model) :
def __init__(self, latent_dim):
super(CVAE, self).__init__()
self.latent_dim =latent_dim
self.inference_net =tf.keras.Sequential(
[
tf.keras.layers.InputLayer(input_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(
filtres=32, kernel_size=3, strides=(2, 2), activation='relu'),
tf.keras.layers.Conv2D(
filtres=64, kernel_size=3, strides=(2, 2), activation='relu'),
tf.keras.layers.Flatten(),
# Pas d'activation
tf.keras.layers.Dense(latent_dim + latent_dim),
]
)
self.generative_net =tf.keras.Sequential(
[
tf.keras.layers.InputLayer(input_shape=(latent_dim,)),
tf.keras.layers.Dense(units=7*7*32, activation=tf.nn.relu),
tf.keras.layers.Reshape(target_shape=(7, 7, 32)),
tf.keras.layers.Conv2DTranspose(
filtres=64,
kernel_size=3,
foulées=(2, 2),
padding="SAME",
activation='relu'),
tf.keras.layers.Conv2DTranspose(
filtres=32,
kernel_size=3,
foulées=(2, 2),
padding="SAME",
activation='relu'),
# Pas d'activation
tf.keras.layers.Conv2DTranspose(
filtres=1, kernel_size=3, strides=(1, 1), padding="SAME"),
]
)
@tf.function
def sample(self, eps=None) :
si eps est Aucun :
eps =tf.random.normal(shape=(100, self.latent_dim))
return self.decode(eps, apply_sigmoid=True)
def encode(self, x):
signifie, logvar =tf.split(self.inference_net(x), num_or_size_splits=2, axis=1)
renvoie la moyenne, logvar
def reparameterize(self, Mean, logvar) :
eps =tf.random.normal(shape=mean.shape)
renvoie eps * tf.exp(logvar * .5) + moyenne
def decode(self, z, apply_sigmoid=False) :
logits =self.generative_net(z)
si apply_sigmoid :
probs =tf.sigmoid(logits)
problèmes de retour
retourner les logits
Les deux extraits de code préparent notre ensemble de données et construisent notre modèle d'autoencodeur variationnel. Dans l'extrait de code du modèle, il existe quelques fonctions d'assistance pour effectuer l'encodage, l'échantillonnage et le décodage.
Reparamétrage pour le calcul des gradients
Il existe une fonction de reparamétrage dont nous n'avons pas discuté mais qui résout un problème très crucial dans notre réseau d'autoencodeur variationnel. Rappelons que lors de l'étape de décodage, on échantillonne le vecteur d'encodage latent à partir d'une distribution contrôlée par le vecteur de moyenne et de variance généré par l'encodeur. Cela ne génère aucun problème lors de la propagation des données via notre réseau, mais pose un gros problème lors de la rétro-propagation des gradients du décodeur vers l'encodeur, car l'opération d'échantillonnage n'est pas différentiable.
En termes simples, nous ne pouvons pas calculer les gradients à partir d'une opération d'échantillonnage.
Une bonne solution de contournement pour ce problème est d'appliquer l'astuce de reparamétrage. Cela fonctionne en générant d'abord une distribution gaussienne standard de la moyenne 0 et de la variance 1, puis en effectuant une opération d'addition et de multiplication différentiable sur cette distribution avec la moyenne et la variance générées par l'encodeur.
Notez que nous transformons la variance en espace logarithmique dans le code. Il s'agit d'assurer la stabilité numérique. Le terme de perte supplémentaire, la perte de divergence de Kullback-Leibler, est introduit pour garantir que les distributions que nous générons sont aussi proches que possible d'une distribution gaussienne standard avec une moyenne 0 et une variance 1.
Ramener les moyennes des distributions à zéro garantit que les distributions que nous générons sont très proches les unes des autres pour éviter les discontinuités entre les distributions. Une variance proche de 1 signifie que nous avons un espace plus modéré (c'est-à-dire ni très grand ni très petit) pour générer des encodages.
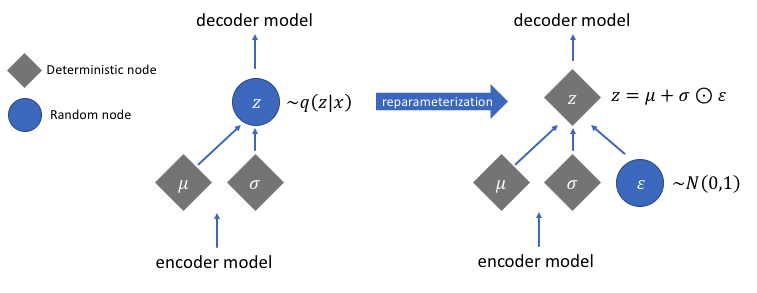
Image utilisée avec l'aimable autorisation de Jeremy Jordan
Après avoir effectué l'astuce de reparamétrage, la distribution obtenue en multipliant le vecteur de variance avec une distribution gaussienne standard et en ajoutant le résultat au vecteur moyen est très similaire à la distribution immédiatement contrôlée par les vecteurs de moyenne et de variance.
Étapes simples pour créer un encodeur variationnel
Terminons ce didacticiel en résumant les étapes de création d'un auto-encodeur variationnel :
- Créez les réseaux d'encodeurs et de décodeurs.
- Appliquer une astuce de reparamétrage entre l'encodeur et le décodeur pour permettre la rétro-propagation.
- Formez les deux réseaux de bout en bout.
Le code complet utilisé ci-dessus est disponible sur le site Web officiel de TensorFlow.
Image en vedette modifiée de Chiman Kwan
Robot industriel
- Comment les imprimantes 3D construisent des objets métalliques
- Comment réduire les déchets avec des robots autonomes
- Comment sécuriser la technologie cloud ?
- Que dois-je faire avec les données ? !
- Comment l'IoT peut aider avec le Big Data HVAC :Partie 2
- Comment rendre l'IOT réel avec Tech Data et IBM Part 2
- Comment rendre l'IoT réel avec Tech Data et IBM Part 1
- Comment les entreprises de la chaîne d'approvisionnement peuvent établir des feuilles de route avec l'IA
- Exploration de données, IA :comment les marques industrielles peuvent suivre le rythme du commerce électronique