


Tirer parti des FPGA pour l'apprentissage en profondeur
J'ai récemment participé au Xilinx Development Forum (XDF) 2018 dans la Silicon Valley. Lors de ce forum, j'ai été présenté à une société appelée Mipsology, une startup dans le domaine de l'intelligence artificielle (IA) qui prétend avoir résolu les problèmes liés à l'IA associés aux réseaux de portes programmables sur le terrain (FPGA). Mipsology a été fondée avec une vision grandiose pour accélérer le calcul de n'importe quel réseau de neurones (NN) avec les performances les plus élevées possibles sur les FPGA sans les contraintes inhérentes à leur déploiement.
Mipsology a démontré sa capacité à exécuter plus de 20 000 images par seconde, en s'exécutant sur les nouvelles cartes Alveo de Xilinx, et en traitant une collection de NN, notamment ResNet50, InceptionV3, VGG19, entre autres.
Présentation des réseaux de neurones et de l'apprentissage en profondeur
Largement modelé sur le réseau de neurones du cerveau humain, un réseau de neurones est à la base de l'apprentissage en profondeur (DL), un système mathématique complexe qui peut apprendre des tâches par lui-même. En regardant de nombreux exemples ou associations, un NN peut apprendre des connexions et des relations plus rapidement qu'un programme de reconnaissance traditionnel. Le processus de configuration d'un NN pour effectuer une tâche spécifique basée sur l' apprentissage des millions d'échantillons du même type est appelé formation .
Par exemple, un NN peut écouter de nombreux échantillons vocaux et utiliser DL pour apprendre à « reconnaître » les sons de mots spécifiques. Ce NN pourrait alors passer au crible une liste de nouveaux échantillons vocaux et identifier correctement les échantillons contenant des mots qu'il a appris, en utilisant une technique appelée inférence .
Malgré sa complexité, DL est basé sur l'exécution d'opérations simples - principalement des additions et des multiplications - dans les milliards ou les trillions. La demande de calcul pour effectuer de telles opérations est intimidante. Plus précisément, les besoins informatiques pour exécuter les inférences DL sont supérieurs à ceux de la formation DL. Alors que la formation DL ne doit être effectuée qu'une seule fois, un NN, une fois formé, doit effectuer une inférence encore et encore pour chaque nouvel échantillon qu'il reçoit.
Quatre choix pour accélérer l'inférence d'apprentissage en profondeur
Au fil du temps, la communauté des ingénieurs a eu recours à quatre appareils informatiques différents pour traiter les NN. Par ordre croissant de puissance de traitement et de consommation d'énergie, et par ordre décroissant de flexibilité/d'adaptabilité, ces dispositifs comprennent :des unités centrales de traitement (CPU), des unités de traitement graphique (GPU), des FPGA et des circuits intégrés spécifiques à l'application (ASIC). Le tableau ci-dessous résume les principales différences entre les quatre appareils informatiques.
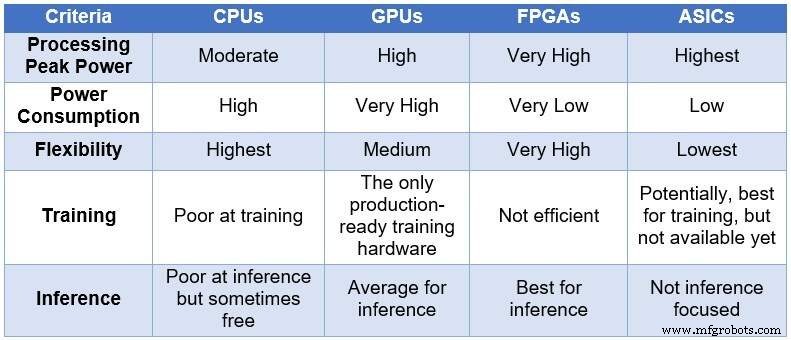
Comparaison des CPU, GPU, FPGA et ASIC pour le calcul DL (Source :Lauro Rizzatti)
Les processeurs sont basés sur l'architecture Von Neuman. Bien que flexibles (la raison de leur existence), les processeurs sont affectés par une longue latence en raison des accès mémoire consommant plusieurs cycles d'horloge pour exécuter une tâche simple. Lorsqu'elles sont appliquées aux tâches qui bénéficient des latences les plus faibles telles que le calcul NN et, en particulier, la formation et l'inférence DL, elles constituent le choix le plus médiocre.
Les GPU offrent un débit de calcul élevé au prix d'une flexibilité réduite. De plus, les GPU consomment une puissance importante qui nécessite un refroidissement, ce qui les rend moins qu'idéal pour le déploiement dans les centres de données.
Bien que les ASIC personnalisés puissent sembler être une solution idéale, ils ont leur propre ensemble de problèmes. Développer un ASIC prend des années. DL et NN évoluent rapidement avec des percées en cours, rendant la technologie de l'année dernière hors de propos. De plus, pour rivaliser avec un CPU ou un GPU, un ASIC devrait utiliser une grande surface de silicium en utilisant la technologie de nœud de processus la plus fine. Cela rend l'investissement initial coûteux, sans aucune garantie de pertinence à long terme. Tout bien considéré, les ASIC sont efficaces pour des tâches spécifiques.
Les dispositifs FPGA sont apparus comme le meilleur choix possible pour l'inférence. Ils sont rapides, flexibles, économes en énergie et offrent une bonne solution pour le traitement des données dans les centres de données, en particulier dans le monde en évolution rapide du DL, à la périphérie du réseau et sous le bureau des scientifiques de l'IA.
Les plus grands FPGA disponibles aujourd'hui incluent des millions d'opérateurs booléens simples, des milliers de mémoires et de DSP, et plusieurs cœurs ARM de CPU. Toutes ces ressources fonctionnent en parallèle - chaque impulsion d'horloge déclenche jusqu'à des millions d'opérations simultanées - ce qui entraîne des milliards d'opérations effectuées à chaque seconde. Le traitement requis par DL correspond assez bien aux ressources FPGA.
Les FPGA présentent d'autres avantages par rapport aux CPU et GPU utilisés pour la DL, notamment :
Ils ne sont pas limités à certains types de données. Ils peuvent gérer une faible précision non standard plus appropriée pour fournir un débit plus élevé pour DL.
Ils consomment moins d'énergie que les CPU ou les GPU — généralement cinq à 10 fois moins de puissance moyenne pour le même calcul NN. Leur coût récurrent dans les centres de données est inférieur.
Ils peuvent être reprogrammés pour s'adapter à n'importe quelle tâche mais être suffisamment génériques pour s'adapter à diverses entreprises. Le DL évolue rapidement et le même FPGA s'adaptera aux nouvelles exigences sans avoir besoin du silicium de nouvelle génération (ce qui est typique des ASIC), réduisant ainsi le coût de possession.
Ils vont des grands aux petits appareils. Ils peuvent être utilisés dans des centres de données ou dans un nœud Internet des objets (IoT). La seule différence est le nombre de blocs qu'ils contiennent.
Tout ce qui brille n'est pas or
La puissance de calcul élevée, la faible consommation d'énergie et la flexibilité d'un FPGA ont un prix :la difficulté à programmer.
Technologie de l'Internet des objets
- CEVA :processeur IA de deuxième génération pour les charges de travail des réseaux de neurones profonds
- Présentation des arguments en faveur des puces neuromorphiques pour l'IA informatique
- ICP :carte accélératrice basée sur FPGA pour l'inférence d'apprentissage en profondeur
- IA externalisée et apprentissage en profondeur dans le secteur de la santé :la confidentialité des données est-elle menacée ?
- Comment le secteur des hautes technologies tire-t-il parti de l'IA pour une croissance exponentielle de l'entreprise
- Intelligence artificielle vs apprentissage automatique vs apprentissage en profondeur | La différence
- Équipe Apple et IBM Watson pour le machine learning mobile d'entreprise
- Le Deep Learning et ses nombreuses applications
- Solution de stabilité d'outil pour le perçage de trous profonds