


Meilleures pratiques pour le débogage des applications IoT basées sur Zephyr
Le projet Open Source Linux Foundation Zephyr est devenu l'épine dorsale de nombreux projets IoT. Zephyr propose un petit système d'exploitation en temps réel (RTOS) évolutif et optimisé pour les appareils aux ressources limitées, sur plusieurs architectures. Le projet compte actuellement 1 000 contributeurs et 50 000 engagements pour créer une prise en charge avancée de plusieurs architectures, notamment ARC, Arm, Intel, Nios, RISC-V, SPARC et Tensilica, et plus de 250 cartes.
Lorsque vous travaillez avec Zephyr, il y a quelques considérations essentielles pour garder les choses connectées et fonctionner de manière fiable. Les développeurs ne peuvent pas résoudre toutes les catégories de problèmes à leur bureau et certains ne deviennent évidents que lorsque le parc d'appareils s'agrandit. À mesure que les réseaux et les piles de réseaux évoluent, vous devez vous assurer que les mises à niveau n'introduisent pas de problèmes inutiles.
Par exemple, considérons une situation à laquelle nous avons été confrontés avec des traceurs GPS déployés pour suivre les animaux de la ferme. L'appareil était un collier à faible encombrement basé sur un capteur. Un jour donné, l'animal errait de réseau mobile en réseau mobile; d'un pays à l'autre ; d'un endroit à l'autre. Un tel mouvement a rapidement exposé des erreurs de configuration et un comportement inattendu qui pourraient entraîner une perte de puissance entraînant une perte économique importante. Nous n'avions pas seulement besoin de connaître un problème, nous devions savoir pourquoi cela s'était produit et comment le résoudre. Lorsque vous travaillez avec des appareils connectés, la surveillance et le débogage à distance sont essentiels pour obtenir un aperçu instantané de ce qui s'est mal passé, des prochaines étapes à suivre pour remédier à la situation et, finalement, de la manière d'établir et de maintenir un fonctionnement normal.
Nous utilisons une combinaison de Zephyr et de la plate-forme d'observabilité des appareils basée sur le cloud Memfault pour prendre en charge la surveillance et la mise à jour des appareils. D'après notre expérience, vous pouvez tirer parti des deux pour établir les meilleures pratiques de surveillance à distance à l'aide de redémarrages, de chiens de garde, d'erreurs/d'assertions et de métriques de connectivité.
Mise en place d'une plateforme d'observabilité
Memfault permet aux développeurs de surveiller, de déboguer et de mettre à jour le micrologiciel à distance, ce qui nous permet de :
- éviter les gels de production en faveur d'un produit viable minimum et des mises à jour Day-0
- surveiller en permanence l'état général de l'appareil
- envoyer les mises à jour et les correctifs avant que la plupart des utilisateurs finaux, le cas échéant, ne remarquent des problèmes
Le SDK de Memfault s'intègre facilement pour collecter des paquets de données pour l'analyse du cloud et la déduplication des problèmes. Cela fonctionne comme un module Zephyr typique où vous l'ajoutez à votre fichier manifeste.
# ouest.yml [ ... ] - nom :memfault-firmware-sdk URL :https://github.com/memfault/memfault-firmware-sdk chemin :modules/memfault-firmware-sdk révision :maître # prj.conf CONFIG_MEMFAULT=y CONFIG_MEMFAULT_HTTP_ENABLE=y
Premier domaine d'intérêt :les redémarrages
Supposons que vous voyiez une augmentation considérable des réinitialisations sur votre appareil. C'est souvent un indicateur précoce que quelque chose dans la topologie a changé ou que les périphériques commencent à rencontrer des problèmes en raison de défauts matériels. Il s'agit de la plus petite information que vous puissiez collecter pour commencer à avoir une idée de la santé de l'appareil, et cela aide à y réfléchir en deux parties :les réinitialisations matérielles et les réinitialisations logicielles.
Les réinitialisations matérielles sont souvent dues à des chiens de garde matériels et à des baisses de tension. Les réinitialisations logicielles peuvent être causées par des mises à jour du micrologiciel, des assertions ou être initiées par l'utilisateur.
Après avoir identifié les types de réinitialisations en cours, nous pouvons comprendre s'il y a des problèmes qui affectent l'ensemble de la flotte, ou s'ils sont limités à un petit pourcentage d'appareils.
Enregistrer la raison du redémarrage
vide fw_update_finish(void) { // ... memfault_reboot_tracking_mark_reset_imminent(kMfltRebootReason_FirmwareUpdate, ...); sys_reboot(0) ; } Zephyr dispose d'un mécanisme d'enregistrement des régions qui seront préservées lors d'une réinitialisation à laquelle Memfault se connecte. Si vous êtes sur le point de redémarrer la plate-forme, nous vous recommandons d'enregistrer juste avant de commencer. Lorsque vous redémarrez la plate-forme, enregistrez la raison de votre redémarrage - dans ce cas, une mise à jour du firmware - puis appelez-le Zephyr sys_reboot.
Capture des réinitialisations de l'appareil sur Zephyr
Enregistrez le gestionnaire d'initialisation pour lire les informations de démarrage
statique int record_reboot_reason() { // 1. Lire le registre des motifs de réinitialisation matérielle. (Vérifiez la fiche technique du MCU pour le nom du registre) // 2. Capturez la raison de la réinitialisation du logiciel à partir de la RAM noinit // 3. Envoi des données au serveur pour agrégation } SYS_INIT(record_reboot_reason, APPLICATION, CONFIG_KERNEL_INIT_PRIORITY_DEFAULT ); Vous pouvez configurer une macro qui capture les informations système avant les réinitialisations via le registre des motifs de réinitialisation du MCU. Lorsque l'appareil redémarre, Zephyr enregistre les gestionnaires à l'aide de la macro system_int. Les registres de raison de réinitialisation du MCU ont tous des noms légèrement différents et sont tous utiles car vous pouvez voir s'il y a des problèmes ou des défauts matériels.
Exemple :Problème d'alimentation
Regardons un exemple de la façon dont la surveillance à distance peut donner un aperçu vital de la santé de la flotte en examinant les redémarrages et l'alimentation électrique. Ici, nous pouvons voir qu'un petit nombre d'appareils représentent plus de 12 000 redémarrages (Figure 1).
cliquez pour l'image en taille réelle

Figure 1 :Exemple de problème d'alimentation, graphique des redémarrages sur 15 jours. (Source :Auteurs)
- 12 000 redémarrages de l'appareil par jour – beaucoup trop
- 99 % des redémarrages effectués par 10 appareils
- Mauvaise pièce mécanique contribuant aux redémarrages constants de l'appareil
Dans ce cas, certains appareils redémarrent 1 000 fois par jour, probablement en raison d'un problème mécanique (pièce défectueuse, mauvais contact de la batterie ou divers problèmes de fréquence chroniques).
Une fois que les appareils sont en production, vous pouvez gérer un certain nombre de ces problèmes grâce aux mises à jour du micrologiciel. Le déploiement d'une mise à jour vous permet de contourner les défauts matériels et de contourner le besoin d'essayer de récupérer et de remplacer les appareils.
Deuxième domaine d'intérêt :chiens de garde
Lorsque vous travaillez avec des piles connectées, un chien de garde est la dernière ligne de défense pour remettre un système dans un état propre sans réinitialiser manuellement l'appareil. Les blocages peuvent se produire pour de nombreuses raisons telles que
- Blocs de pile de connectivité sur send()
- Boucles de réessais infinies
- Interblocages entre les tâches
- Corruption
Les chiens de garde matériels sont un périphérique dédié dans le MCU qui doit être « alimenté » périodiquement pour les empêcher de réinitialiser le périphérique. Les chiens de garde logiciels sont implémentés dans le micrologiciel et se déclenchent avant le chien de garde matériel pour permettre la capture de l'état du système menant au chien de garde matériel.
Zephyr dispose d'une API de surveillance matérielle où tous les MCU peuvent passer par l'API générique pour installer et configurer le chien de garde dans la plate-forme. (Voir l'API Zephyr pour plus de détails :zephyr/include/drivers/watchdog.h)
// ... vide start_watchdog(void) { // consulter l'arborescence des périphériques pour le chien de garde matériel disponible s_wdt =device_get_binding(DT_LABEL(DT_INST(0, nordic_nrf_watchdog))); struct wdt_timeout_cfg wdt_config ={ /* Réinitialise le SoC à l'expiration de la minuterie du chien de garde. */ .flags =WDT_FLAG_RESET_SOC, /* Expire le chien de garde après la fenêtre max */ .window.min =0U, .window.max =WDT_MAX_WINDOW, } ; s_wdt_channel_id =wdt_install_timeout(s_wdt, &wdt_config); options const uint8_t =WDT_OPT_PAUSE_HALTED_BY_DBG ; wdt_setup(s_wdt, options); // A FAIRE :Lancer un chien de garde logiciel } vide feed_watchdog(void) { wdt_feed(s_wdt, s_wdt_channel_id); // A FAIRE :chien de garde du logiciel de flux } Examinons quelques étapes en utilisant cet exemple du Nordic nRF9160.
- Accédez à l'arborescence des appareils et configurez le dossier de durée de visionnage Nordic nRF.
- Définissez les options de configuration du chien de garde via l'API exposée.
- Installez le chien de garde.
- Nourrir périodiquement le chien de garde lorsque les comportements s'exécutent comme prévu. Parfois, cela se fait à partir des tâches les moins prioritaires. Si le système est bloqué, il déclenchera un redémarrage.
En utilisant Memfault sur Zephyr, vous pouvez utiliser des minuteries de noyau, alimentées par un périphérique de minuterie. Vous pouvez définir le délai d'attente du chien de garde logiciel pour qu'il soit en avance sur votre chien de garde matériel (par exemple, définissez votre chien de garde matériel à 60 secondes et votre chien de garde logiciel à 50 secondes). Si le rappel est invoqué, une assertion sera déclenchée, qui vous guidera dans le gestionnaire d'erreurs Zephyr et obtiendra des informations sur ce qui se passait à ce moment-là où le système était bloqué.
Exemple :Pilote SPI bloqué
Tournons-nous à nouveau vers un exemple de problème qui n'est pas pris dans le développement mais qui se pose sur le terrain. Dans la figure 2, vous pouvez voir le timing, les faits et la dégradation des puces du pilote SPI.
cliquez pour l'image en taille réelle
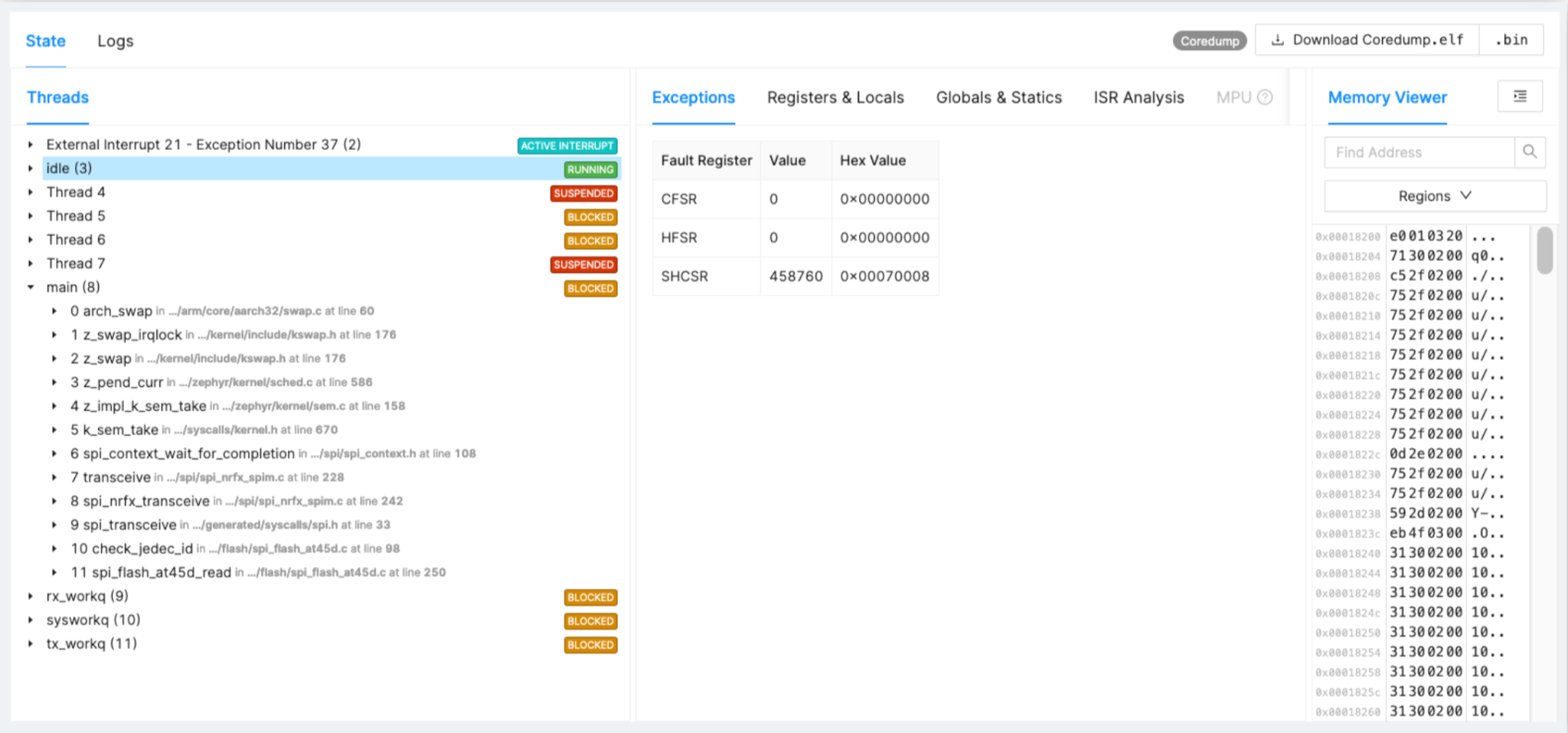
Figure 2 :Exemple de pilote SPI bloqué. (Source :Auteurs)
- Flash SPI se dégradant au fil du temps, synchronisation incorrecte de la communication
- Tracé sur 1 % des appareils après 16 mois de déploiement sur le terrain
- Correction et déploiement du pilote avec la prochaine version
Pour Flash, après un an sur le terrain, vous pouvez voir qu'il y a un début soudain d'erreurs dues au blocage des transactions SPI ou de divers morceaux de code. Avoir la trace complète vous aide à trouver la cause première et à développer une solution.
Le chien de garde ci-dessous (Figure 3) lance le gestionnaire de pannes Zephyr.
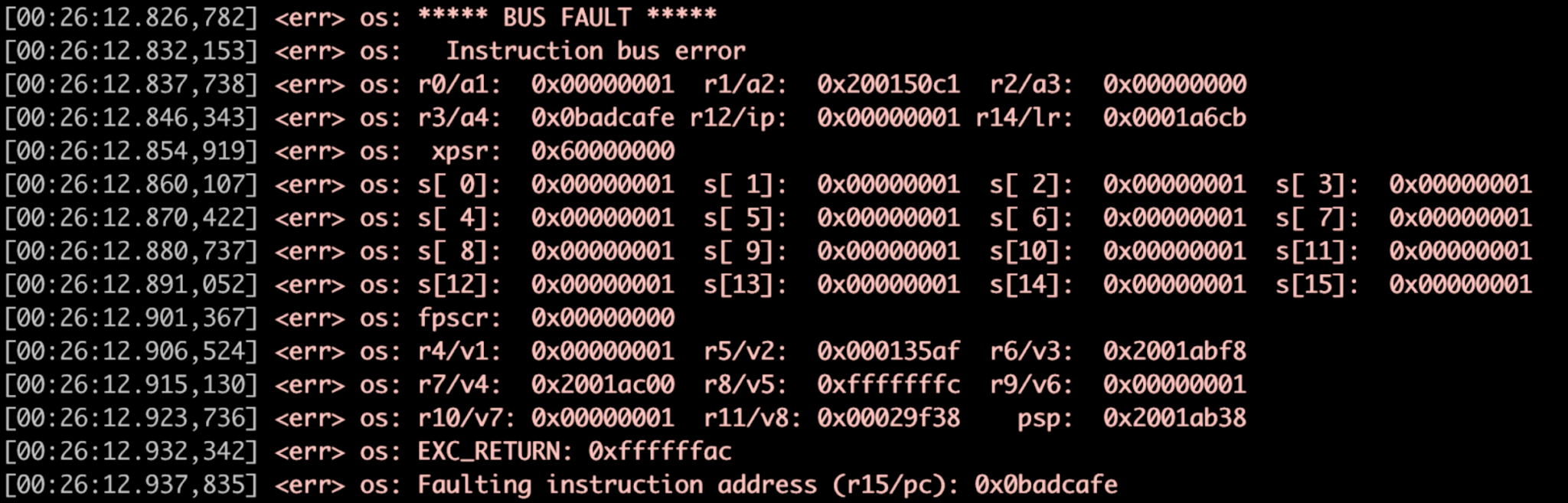
Figure 3 :Exemple de gestionnaire de pannes, vidage de registre. (Source :Auteurs)
Troisième domaine d'intérêt :Défauts/Assertions :
Le troisième composant à suivre est celui des défauts et des assertions. Si vous avez déjà effectué un débogage local ou créé vos propres fonctionnalités, vous avez probablement vu un écran similaire sur l'état du registre lorsqu'une erreur s'est produite sur la plate-forme. Ceux-ci peuvent être dus à :
- affirmations, ou
- accès à une mauvaise mémoire
- diviser par zéro
- utiliser un périphérique dans le mauvais sens
Voici un exemple de flux de gestion des pannes utilisé sur des microcontrôleurs Cortex M sur Zephyr.
vide network_send(void) { const size_t packet_size =1500 ; void *buffer =z_malloc(packet_size); // vérification NULL manquante ! memcpy(buffer, 0x0, packet_size); // ... } ↓vide network_send(void) { const size_t packet_size =1500 ; void *buffer =z_malloc(packet_size); // vérification NULL manquante ! memcpy(buffer, 0x0, packet_size); // ... } ↓bool memfault_coredump_save(const sMemfaultCoredumpSaveInfo *save_info) { // Enregistrer l'état du registre // Enregistrer les contextes de _kernel et de tâche // Enregistrer les régions .bss et .data sélectionnées } ↓vide sys_arch_reboot(type int) { // ... } Lorsqu'une assertion ou une erreur démarre, une interruption se déclenche et un gestionnaire d'erreurs est invoqué dans Zephyr qui fournit l'état du registre au moment du crash.
Le SDK Memfault s'intègre automatiquement au flux de gestion des pannes, enregistrant les informations critiques dans le cloud, notamment l'état du registre, l'état du noyau et une partie de toutes les tâches en cours d'exécution sur le système au moment du crash.
Il y a trois choses à rechercher lorsque vous déboguez localement ou à distance :
- Le registre d'état des défauts du Cortex M vous indique pourquoi la plate-forme a été déclarée ou défaillante.
- Memfault récupère la ligne de code exacte que le système exécutait avant le plantage, ainsi que l'état de toutes les autres tâches.
- Récupérez le _kernel structure dans le Zephyr RTOS pour voir le planificateur, et s'il s'agit d'une application connectée, l'état des paramètres Bluetooth ou LTE.
Quatrième domaine d'intérêt :suivi des métriques pour l'observabilité des appareils
Le suivi des métriques vous permet de commencer à créer un modèle de ce qui se passe sur votre système et vous permet de faire des comparaisons entre vos appareils et votre flotte pour comprendre quels changements ont un impact.
Voici quelques mesures utiles à suivre :
- Utilisation du processeur
- paramètres de connectivité
- consommation de chaleur
Avec le SDK Memfault, vous pouvez ajouter et commencer à définir des métriques sur Zephyr avec deux lignes de code :
- Définir la métrique
MEMFAULT_METRICS_KEY_DEFINE( LteDisconnect, kMemfaultMetricType_Unsigned)
- Mettre à jour la métrique dans le code
vide lte_disconnect(void) { memfault_metrics_heartbeat_add( MEMFAULT_METRICS_KEY(LteDisconnect), 1 ); //... } SDK Memfault + Cloud
- Sérialise et compresse les métriques pour le transport
- Indique les métriques par appareil et version du micrologiciel
- Expose l'interface Web pour parcourir les métriques par appareil et sur l'ensemble de la flotte
Des dizaines de métriques peuvent être collectées et indexées par appareil et version de firmware. Quelques exemples :
- Connectivité de base NB-IoT/LTE-M : Découvrez l'impact d'un modem sur la durée de vie de la batterie, qu'il soit connecté ou connecté.
- Suivi des stations de base et du PSM dans NB-IoT/LTE-M : La qualité du signal mobile peut être pénible et peut épuiser la durée de vie de la batterie si elle n'est pas gérée. Créez des métriques pour l'état du réseau, les événements, les informations sur les tours de téléphonie cellulaire, les paramètres, les minuteries et plus encore. Surveillez les changements et utilisez les alertes.
- Test de grandes flottes : Des données volumineuses inattendues peuvent augmenter les coûts de connectivité des appareils et aider à identifier les valeurs aberrantes.
Exemple :taille des données NB-IoT/LTE-M
cliquez pour l'image en taille réelle
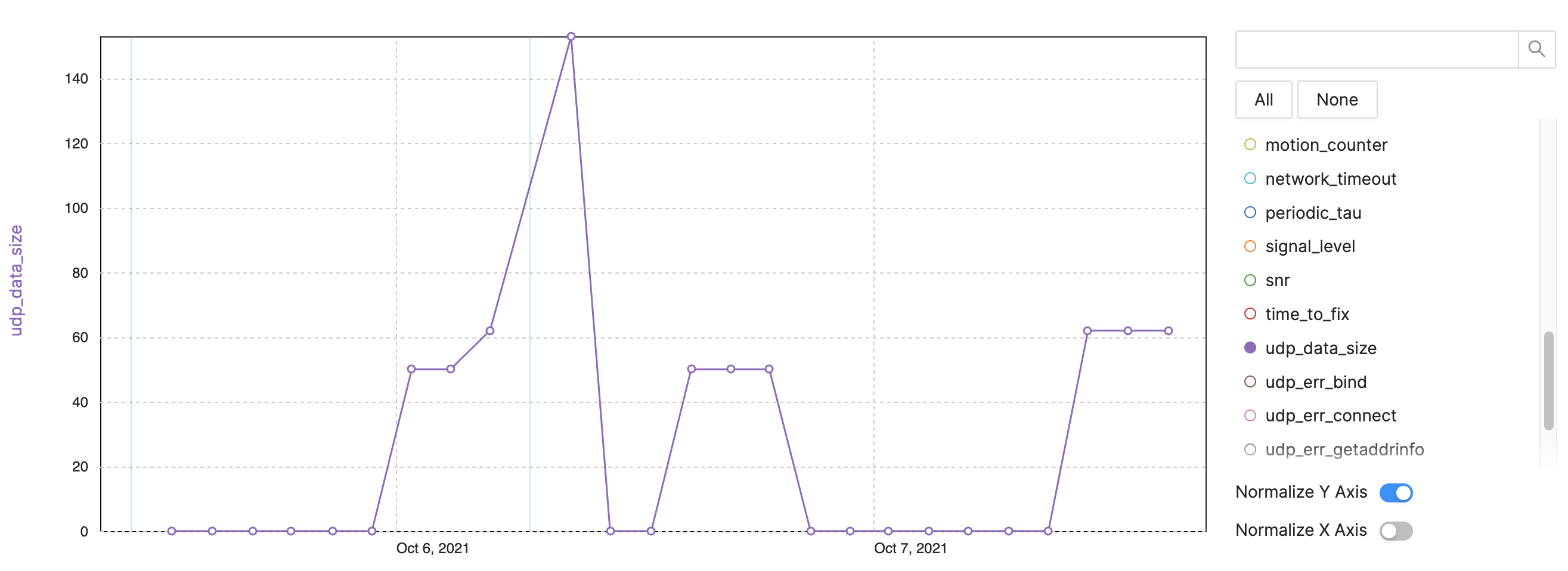
Figure 4 : mesures de suivi pour l'observabilité des appareils – Exemple NB-IoT, taille des données LTE-M. (Source :Auteurs)
- Taille des données UDP :suivi des octets par intervalle d'envoi (Figure 4)
- Après le redémarrage, davantage de données sont envoyées
- Certains paquets sont plus gros en raison de plus d'informations ou de traces
- Suivre le problème de la consommation de données
Conclusion
En s'appuyant sur Zephyr et Memfault, les développeurs peuvent mettre en œuvre une surveillance à distance pour obtenir une meilleure observabilité des fonctionnalités des appareils connectés. En se concentrant sur les redémarrages, les chiens de garde, les erreurs/affirmations et les mesures de connectivité, les développeurs peuvent optimiser le coût et les performances des systèmes IoT.
Apprenez-en plus en regardant une présentation enregistrée du Sommet des développeurs Zephyr 2021.
Technologie de l'Internet des objets
- Meilleures pratiques pour la surveillance synthétique
- Émetteurs-récepteurs bidirectionnels 1G pour les fournisseurs de services et les applications IoT
- L'ETSI s'apprête à établir des normes pour les applications IoT dans les communications d'urgence
- IIC et TIoTA vont collaborer sur les meilleures pratiques IoT/Blockchain
- Le NIST publie un projet de recommandations de sécurité pour les fabricants d'IoT
- Le partenariat vise une autonomie sans fin de la batterie des appareils IoT
- 3 meilleures raisons d'utiliser la technologie IoT pour la gestion des actifs
- Pourquoi considérer l'IoT comme la meilleure plateforme de surveillance environnementale ?
- Meilleures applications pour les systèmes à air comprimé