


Qu'est-ce qui se cache derrière le passage aux agents vocaux personnalisés ?
L'automatisation est la voie de l'avenir. Nous vivons à l'ère d'aujourd'hui, voulant que tout soit répondu, réalisé et reçu à une vitesse rapide. Malgré ce changement fondamental, de nombreuses personnes n'embrassent pas la technologie. Pour certains, c'est lié au mode de vie :les grandes entreprises peuvent être trop maladroites pour transformer leur système, et les individus peuvent être bloqués dans leurs habitudes et ne pas vouloir apprendre à naviguer sur un écran tactile. Pour la plupart, cependant, il s'agit de données :à qui appartiennent ces données et comment les protéger.
La solution? C'est aussi simple que la voix. La technologie d'activation vocale peut libérer le besoin d'automatisation tout en gardant les données à proximité, et c'est quelque chose que nous utilisons tous les jours, quel que soit l'endroit ou la plate-forme. Alors que la transformation numérique continue d'avoir un impact sur de plus en plus d'applications, les agents vocaux sont la réponse. De plus en plus d'entreprises explorent la création de plates-formes vocales personnalisées, intégrées à la technologie, à l'exception des noms populaires d'agents vocaux comme Alexa et Google Voice. Des plates-formes vocales uniques seront la voie à suivre pour les entreprises qui souhaitent conserver et contrôler leurs propres données.
Derrière la perturbation se cache l'automatisation
Alors que l'Internet des objets (IoT) s'appuie sur l'intelligence artificielle (IA), nous commençons à voir le besoin d'automatisation se développer. Lorsque l'IoT collabore avec l'IA, cela améliore le contrôle des utilisateurs sur les vastes et vastes collections d'appareils Internet. Nous commençons à voir l'activation de la voix s'étendre à la maison et au-delà, s'interfaçant via des plates-formes telles que Google Voice, Amazon Alexa, Microsoft Cortana ou des plates-formes créées de manière unique. Chez Harman Embedded Audio, nous avons travaillé avec tous les moteurs vocaux de la planète et comprenons directement l'étendue du marché. Nous voyons de plus en plus d'entreprises chercher à créer leurs produits à commande vocale sur leurs propres plates-formes d'assistants vocaux personnalisés, afin qu'elles aient le contrôle des données.
La demande de commande vocale augmente
C'est l'une des tendances les plus en vogue dans l'audio. La prochaine grande nouveauté dans l'interface utilisateur, maintenant que des fonctionnalités telles que les écrans tactiles sont presque omniprésentes, est de pouvoir parler à un appareil. Voice est à la tête de la prochaine génération de collaboration humaine. Pensez au traitement du langage naturel sur un ordinateur :la voix est traitée d'une manière qui correspond à ce que la machine préfère entendre, mais si vous lisiez ce même fichier traité, ce serait mécanique et contre nature. Il en va de même pour parler au téléphone :cela ne donne pas la même impression d'être dans une pièce avec quelqu'un. C'est là que la voix doit aller, et où suivront les plates-formes vocales uniques mentionnées ci-dessus.
À quoi ressemblent les agents vocaux personnalisés et ce qui est impliqué dans la construction
Bien que chaque solution vocale soit différente, il est important que toutes les solutions soient suffisamment flexibles pour s'adapter aux exigences nécessaires de leur cas d'utilisation tout en collectant et en protégeant les données des utilisateurs. Pour y parvenir, trois éléments principaux sont impliqués dans la construction et l'intégration de tout agent vocal.
Le premier concerne les algorithmes de champ lointain. Utilisez un algorithme de premier plan qui capturera la voix en champ lointain. Dans mon entreprise, nous utilisons quatre algorithmes logiciels clés d'algorithmes Sonique :la suppression du bruit, la suppression du bruit acoustique, la séparation du son et la formation de faisceaux, ainsi que la détection de l'activité vocale. Ces algorithmes sont spécifiquement développés pour être utilisés en combinaison les uns avec les autres pour prendre en charge les applications à commande vocale.
Comment travaillent-ils? Pensez à comparer un haut-parleur intelligent avec un humain. Le DSP/SOC agit comme le « cerveau » du haut-parleur, les microphones sont les oreilles et les haut-parleurs sont la bouche. Pour nous, lorsque quelqu'un appelle notre nom, notre cerveau annule tous les bruits qui nous entourent et met toute son énergie vers ce mot-clé. C'est ce que nous avons accompli dans un haut-parleur intelligent :lorsque le mot-clé est détecté, le microphone utilise différentes techniques de suppression du bruit et met toute sa puissance vers la source. Ce faisant, il annule la plupart des bruits qui l'entourent. Dans les environnements acoustiques, il existe de nombreuses sources de bruit telles que le bruit ambiant, les haut-parleurs locaux, le CVC et plus encore, qui font écho au retour du haut-parleur vers le microphone. Chacune de ces sources de bruit a besoin de sa propre solution individuelle. Les algorithmes Sonique suppriment les bruits et capturent la meilleure commande vocale claire possible.
En outre, la création d'un moteur de recherche de mots clés (KWS) est cruciale. KWS détecte des mots-clés tels que « Alexa » ou « OK Google » pour démarrer une conversation. J'ai travaillé avec presque tous les fournisseurs de moteurs KWS, et chacun est alimenté par des réseaux de neurones profonds - hautement personnalisables, toujours à l'écoute, légers et intégrés. Pour une excellente expérience client dans une application vocale en champ lointain, le composant crucial est un taux de fausses acceptations et de faux rejets. Dans des conditions réelles, il est vraiment difficile de maintenir un faible taux de faux rejets car il existe de nombreux bruits externes tels que les téléviseurs, les appareils électroménagers, les douches, etc., qui provoquent une annulation imparfaite de la lecture audio. Les développeurs expérimentés règlent le moteur KWS pour maintenir le taux de fausses acceptations bas.
Enfin, le moteur de reconnaissance vocale automatique (ASR) convertit la voix en texte. L'ASR se compose de l'outil principal de synthèse vocale (STT) et de la compréhension du langage naturel (NLU), qui convertit le texte brut en données. Le moteur nécessite également des compétences, ou, en d'autres termes, une base de connaissances à partir de laquelle des réponses peuvent être fournies, ainsi que l'outil de conversion de texte en parole. Nous avons développé un moteur ASR appelé E-NOVA, par exemple, qui offre des intégrations multi-plateformes, sur site, prend en charge plusieurs langues (actuellement sept langues et en croissance) et inclut des modèles pouvant être entraînés, une prise en charge d'intégration tierce et l'identification de l'orateur.
L'ASR est la première étape qui permet aux technologies vocales comme Amazon Alexa, OK Google, Cortana ou le client de répondre lorsqu'on lui demande :« quel temps fait-il à Los Angeles ? » C'est l'élément clé qui détecte le son parlé, le reconnaît comme des mots, les associe au son d'une langue donnée et identifie finalement les mots que nous prononçons. Grâce au moteur ASR, la conversation semble naturelle. Et, avec les technologies modernes, la plupart des moteurs ASR tirent parti du cloud computing. Avec des technologies supplémentaires telles que NLU, les conversations entre les humains et les ordinateurs deviennent plus intelligentes et plus complexes.
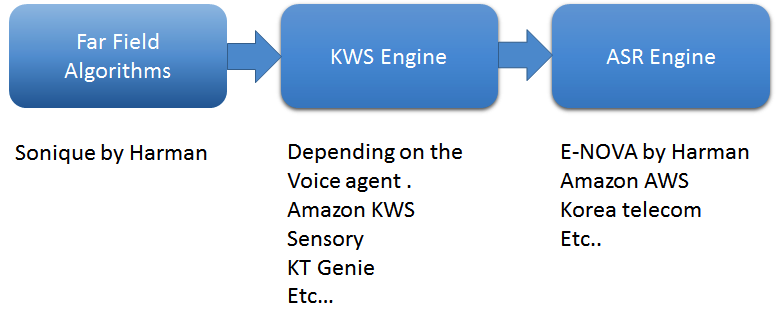
Figure 1 : Pipeline de traitement de base dans les agents vocaux. (Source :Harman Embedded Audio)
Cependant, la création d'agents vocaux personnalisés présente une multitude de défis uniques. Comprendre l'environnement du produit est l'un des principaux défis du processus, et chaque application variera en fonction du cas d'utilisation spécifique. Par exemple, imaginez cuisiner chez vous, les mains occupées et pleines, lorsqu'il est temps de faire bouillir de l'eau, il suffit d'une requête rapide à l'agent vocal connecté à votre espace plomberie :« Faire bouillir l'eau à x degrés. Le défi ici est de savoir si l'appareil est capable d'entendre ce que vous avez dit, et combien de bruit l'appareil annulera pour obtenir le signal clair et vous entendre correctement. Pour ce faire, les algorithmes vocaux doivent être adaptés aux environnements hostiles, les emplacements des microphones doivent être ajustés afin qu'ils puissent capter le son et des haut-parleurs à faible THD doivent être utilisés pour aider à un SNR élevé pour les microphones. Grâce à cela, vous obtiendrez le son le plus clair possible pour le moteur ASR, ce qui se traduira par la bonne réponse à vos questions.
De plus, imaginez être sur un bateau de croisière :les bruits autour de vous sont complètement différents de ce que vous entendez dans un salon ou une cuisine. Le plus grand défi consiste à entraîner des algorithmes pour supprimer ces bruits et transmettre un signal audio clair au système pour une réponse précise. Correctement mis en œuvre, un système d'assistant de croisière personnel virtuel tel que celui que nous avons développé pour MSC Croisières peut effectuer de manière fiable les étapes illustrées à la figure 2.
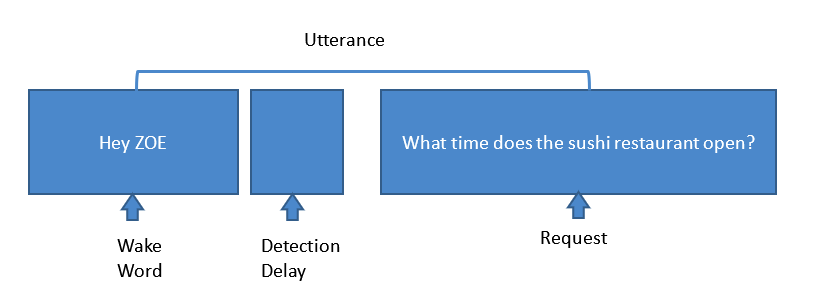
Figure 2 : étapes impliquées dans une demande typique d'assistant vocal. (Source :Harman Embedded Audio)
Ici, une unité d'assistant vocal dans la chambre des passagers détecte le mot de réveil «Hey Zoe». Ensuite, lorsque KWS détecte le mot clé, l'ensemble du microphone, basé sur des algorithmes de suppression de bruit, détourne son énergie vers la source et annule les bruits environnants, tels que les bruits AC, TV, bruits non corrélés, bruits d'hélice et de moteur, bruits de vent, AEC , etc. Les algorithmes Sonique sont réglés pour annuler tous ces bruits et obtenir le signal le plus propre possible au système. Ensuite, lorsque les systèmes reçoivent la demande, le moteur ASR convertit cette voix en texte. Les moteurs NLU convertissent ensuite ce texte en données brutes pour obtenir la réponse. Mais nous n'avons pas encore fini. Pour obtenir la réponse que vous recherchez, la compétence de connaissances fournit la réponse à la demande et le moteur ASR convertit ce texte de données en parole et le transmet via le haut-parleur.
Un autre défi concerne le rejet de faux taux (FRR). Le processus d'obtention de Wake Word FRR, qui est l'un des points de contrôle utilisés pour mesurer les performances des haut-parleurs intelligents, est à la fois long et coûteux. Le système est utilisé pour vérifier si le produit peut se réveiller correctement chaque fois qu'un mot de réveil est détecté. Pour atteindre le FRR, des mots-clés entraînés sont essentiels. D'après notre expérience, combiner le modèle entraîné avec un algorithme de premier plan permet aux équipes de développement de relever le défi et d'atteindre le meilleur FRR possible. La réponse du mot d'activation est ensuite testée dans diverses conditions en laboratoire pour garantir que le système respecte les normes de l'industrie.
Les avantages d'employer des agents vocaux uniques
Les agents vocaux offrent une grande valeur à l'expérience utilisateur. La musique est le cas d'utilisation le plus important et le plus simple, mais la valeur des agents vocaux va bien au-delà de l'ouverture de votre compte Spotify à distance. La voix peut allumer des choses, interagir avec des appareils électroménagers, faire bouillir de l'eau, ouvrir un robinet et plus encore ! La voix est puissante et les agents en savent beaucoup sur leurs utilisateurs, c'est pourquoi les entreprises cherchent à mettre la main sur leurs propres données :les posséder, les stocker et les sécuriser.
Les solutions vocales ont de larges applications, mais la clé est de tirer parti d'une technologie qui fonctionne sur toutes les plateformes - une qui est pertinente pour les haut-parleurs intelligents, les ordinateurs portables et les smartphones, sur Apple, Windows ou Android - et d'exploiter les données collectées pour créer un agent qui comprend, apprend et se souvient constamment des besoins des utilisateurs. La création d'un agent vocal unique permet cette flexibilité d'utilisation et conserve les données internes en même temps.
Embarqué
- Quelle est la différence entre la production de masse et la production personnalisée ?
- Qu'est-ce que la re-plateforme dans le cloud ?
- Que dois-je faire avec les données ? !
- Qu'est-ce que l'économie circulaire ?
- Moteur à courant continu ou à courant alternatif :quelle est la différence ?
- En quoi consiste le processus de fabrication ?
- Qu'est-ce que l'industrie de l'imprimerie ?
- Qu'est-ce que l'industrie de la peinture ?
- Qu'est-ce que l'industrie de l'emballage ?