


De combien de couches et de nœuds cachés un réseau de neurones a-t-il besoin ?
Cet article fournit des directives pour configurer la partie cachée d'un Perceptron multicouche.
Jusqu'à présent, dans cette série sur les réseaux de neurones, nous avons discuté des NN Perceptron, des NN multicouches et de la façon de développer de tels NN à l'aide de Python. Avant de discuter du nombre de couches et de nœuds cachés que vous pouvez choisir d'utiliser, envisagez de rattraper votre retard sur la série ci-dessous.
- Comment effectuer une classification à l'aide d'un réseau de neurones :qu'est-ce que le perceptron ?
- Comment utiliser un exemple simple de réseau neuronal Perceptron pour classer des données
- Comment former un réseau de neurones Perceptron de base
- Comprendre la formation simple sur les réseaux neuronaux
- Une introduction à la théorie de la formation pour les réseaux de neurones
- Comprendre le taux d'apprentissage dans les réseaux de neurones
- Apprentissage automatique avancé avec le Perceptron multicouche
- La fonction d'activation sigmoïde :activation dans les réseaux de neurones Perceptron multicouches
- Comment former un réseau de neurones Perceptron multicouches
- Comprendre les formules d'entraînement et la rétropropagation pour les perceptrons multicouches
- Architecture de réseau neuronal pour une implémentation Python
- Comment créer un réseau de neurones Perceptron multicouche en Python
- Traitement du signal à l'aide de réseaux de neurones :validation dans la conception de réseaux de neurones
- Entraînement d'ensembles de données pour les réseaux de neurones :comment entraîner et valider un réseau de neurones Python
- De combien de couches et de nœuds cachés un réseau de neurones a-t-il besoin ?
Récapitulatif des couches cachées
Tout d'abord, passons en revue quelques points importants concernant les nœuds cachés dans les réseaux de neurones.
- Les perceptrons constitués uniquement de nœuds d'entrée et de nœuds de sortie (appelés perceptrons à couche unique) ne sont pas très utiles car ils ne peuvent pas approximer les relations entrées-sorties complexes qui caractérisent de nombreux types de phénomènes de la vie réelle. Plus précisément, les Perceptrons monocouches sont limités à linéairement séparables problèmes; comme nous l'avons vu dans la partie 7, même quelque chose d'aussi basique que la fonction booléenne XOR n'est pas linéairement séparable.
- Ajout d'un calque caché entre les couches d'entrée et de sortie transforme le Perceptron en un approximateur universel , ce qui signifie essentiellement qu'il est capable de capturer et de reproduire des relations entrées-sorties extrêmement complexes.
- La présence d'une couche cachée rend la formation un peu plus compliquée car l'input-to-hidden les poids ont un effet indirect sur l'erreur finale (c'est le terme que j'utilise pour désigner la différence entre la valeur de sortie du réseau et la valeur cible fournies par les données d'entraînement).
- La technique que nous utilisons pour entraîner un Perceptron multicouche s'appelle la rétropropagation :nous propageons l'erreur finale vers le côté entrée du réseau d'une manière qui nous permet de modifier efficacement les poids qui ne sont pas directement connectés au nœud de sortie. La procédure de rétropropagation est extensible, c'est-à-dire que la même procédure nous permet d'entraîner des poids associés à un nombre arbitraire de couches cachées.
Le schéma suivant résume la structure d'un Perceptron multicouche de base.
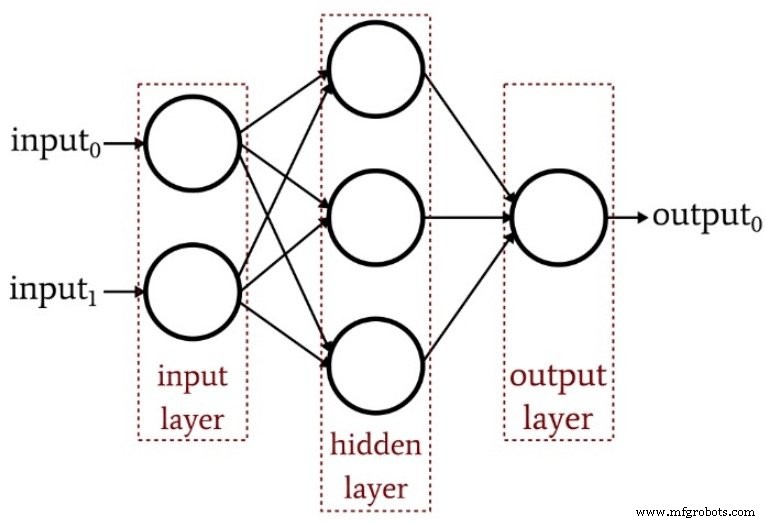
Combien de couches cachées ?
Comme vous vous en doutez, il n'y a pas de réponse simple à cette question. Cependant, la chose la plus importante à comprendre est qu'un Perceptron avec une couche cachée est un système de calcul extrêmement puissant. Si vous n'obtenez pas de résultats adéquats avec une couche cachée, essayez d'abord d'autres améliorations. Vous devrez peut-être optimiser votre taux d'apprentissage, augmenter le nombre d'époques d'entraînement ou améliorer votre ensemble de données d'entraînement. L'ajout d'une deuxième couche cachée augmente la complexité du code et le temps de traitement.
Une autre chose à garder à l'esprit est qu'un réseau de neurones surpuissant n'est pas seulement un gaspillage d'efforts de codage et de ressources de processeur, il peut en fait causer des dommages positifs en rendant le réseau plus susceptible au surentraînement.
Nous avons parlé de surentraînement dans la partie 4, qui comprenait le diagramme suivant comme moyen de visualiser le fonctionnement d'un réseau de neurones dont la solution n'est pas suffisamment généralisée.
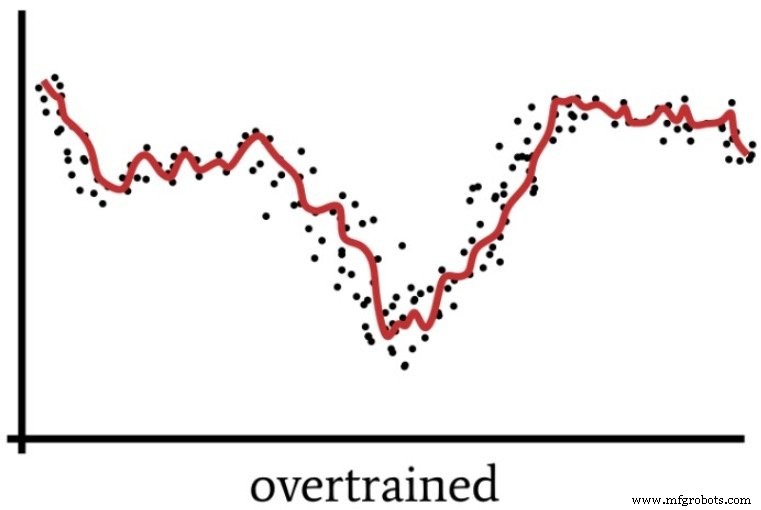
Un Perceptron surpuissant peut traiter les données d'entraînement d'une manière vaguement analogue à la façon dont les gens « trop réfléchissent » parfois à une situation.
Lorsque nous nous concentrons trop sur les détails et appliquons un effort intellectuel excessif à un problème qui est en réalité assez simple, nous passons à côté de la « grande image » et nous nous retrouvons avec une solution qui s'avérera sous-optimale. De même, un Perceptron avec une puissance de calcul excessive et des données d'apprentissage insuffisantes peut s'installer sur une solution trop spécifique au lieu de trouver une solution généralisée (comme le montre la figure suivante) qui classera plus efficacement les nouveaux échantillons d'entrée.
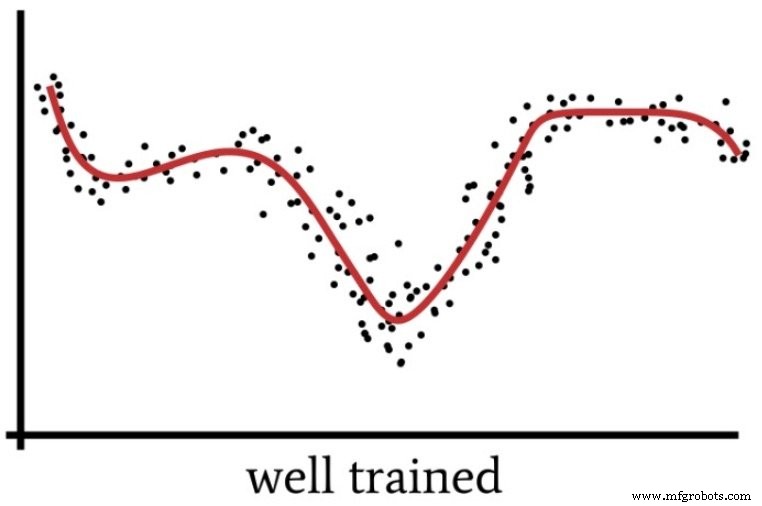
Alors, quand avons-nous réellement besoin de plusieurs couches cachées ? Je ne peux pas vous donner de lignes directrices à partir de mon expérience personnelle. Le mieux que je puisse faire est de transmettre l'expertise du Dr Jeff Heaton (voir page 158 du texte lié), qui déclare qu'une couche cachée permet à un réseau de neurones d'approcher n'importe quelle fonction impliquant « une cartographie continue d'un espace fini à un autre ."
Avec deux couches cachées, le réseau est capable de « représenter une limite de décision arbitraire avec une précision arbitraire ».
Combien de nœuds cachés ?
Trouver la dimensionnalité optimale pour une couche cachée nécessitera des essais et des erreurs. Comme discuté ci-dessus, avoir trop de nœuds n'est pas souhaitable, mais vous devez avoir suffisamment de nœuds pour rendre le réseau capable de capturer les complexités de la relation entrée-sortie.
Les essais et les erreurs, c'est bien beau, mais vous aurez besoin d'une sorte de point de départ raisonnable. Dans le même livre lié ci-dessus (à la page 159), le Dr Heaton mentionne trois règles empiriques pour choisir la dimensionnalité d'une couche cachée. Je vais m'appuyer sur ceux-ci en proposant des recommandations basées sur ma vague intuition de traitement du signal.
- Si le réseau n'a qu'un seul nœud de sortie et que vous pensez que la relation entrée-sortie requise est assez simple, commencez par une dimensionnalité de couche cachée qui est égale aux deux tiers de la dimensionnalité d'entrée.
- Si vous avez plusieurs nœuds de sortie ou si vous pensez que la relation entrée-sortie requise est complexe, faites en sorte que la dimensionnalité de la couche cachée soit égale à la dimensionnalité d'entrée plus la dimensionnalité de sortie (mais gardez-la inférieure au double de la dimensionnalité d'entrée).
- Si vous pensez que la relation entrée-sortie requise est extrêmement complexe, définissez la dimensionnalité cachée sur une dimension inférieure au double de la dimensionnalité d'entrée.
Conclusion
J'espère que cet article vous a aidé à comprendre le processus de configuration et d'affinement de la configuration de la couche cachée d'un Perceptron multicouche.
Dans le prochain article, nous explorerons les effets de la dimensionnalité de la couche cachée en utilisant mon implémentation Python et quelques exemples de problèmes.
Robot industriel
- Qu'est-ce qu'une presse à bascule et comment ça marche ?
- Comment fonctionne une presse à crémaillère et pignon ?
- Qu'est-ce que le moulage par transfert et comment fonctionne-t-il ?
- Qu'est-ce qu'une transmission et comment fonctionne-t-elle ?
- Incorporation de nœuds de polarisation dans votre réseau neuronal
- Comment augmenter la précision d'un réseau de neurones à couche cachée
- Entraînement d'ensembles de données pour les réseaux de neurones :comment entraîner et valider un réseau de neurones Python
- Qu'est-ce qu'un embrayage industriel et comment ça marche ?
- De combien de CV une pompe hydraulique a-t-elle besoin ?