


Plongée en profondeur dans le cycle de vie de la science des données
Depuis l'arrivée des mégadonnées, l'informatique moderne a atteint de nouvelles capacités et de nouvelles références de puissance de traitement. De nos jours, il n'est pas rare de trouver des applications qui produisent des ensembles de données de 100 téraoctets ou plus, ce qui est considéré comme du Big Data.
Avec de tels volumes d'informations à portée de main, il est facile de se désorganiser et de perdre du temps avec du contenu inutile. Ce sont deux raisons pour lesquelles il est très important de suivre une méthodologie qui augmente l'efficacité et l'efficience d'un projet Big Data.

Figure 1. La science des données moderne fonctionne avec de très grands ensembles de données, également appelés big data.
Le cycle de vie de la science des données fournit un cadre qui aide à définir, collecter, organiser, évaluer et déployer des projets de Big Data. Il s'agit d'un processus itératif consistant en une série d'étapes disposées dans une séquence logique, facilitant le retour d'informations et le pivotement.
A quoi ressemble la séquence du cycle de vie ? La réponse est qu'il n'y a pas un seul modèle universel que tout le monde suive. De nombreuses entreprises qui entreprennent des projets de Big Data adaptent le cycle de vie de la science des données à leurs processus métier, comprenant généralement plus d'étapes. Malgré cela, tous les nombreux modèles et flux de processus ont des dénominateurs communs. Cet article utilisera le modèle de processus CRISP-DM, qui est l'un des premiers et des plus populaires modèles de cycle de vie de la science des données.
Le modèle CRISP-DM
CRISP-DM signifie Cross Industry Standard Process for Data Mining. Il a été publié pour la première fois en 1999 par ESPRIT, un programme européen visant à stimuler la recherche en technologies de l'information (TI). Le modèle CRISP-DM se compose de six étapes ou phases qui guident le projet Big Data. Il encourage les parties prenantes à réfléchir à l'entreprise en posant et en répondant à des questions importantes sur le problème.
Revoyons en détail les six phases du modèle CRISP-DM.
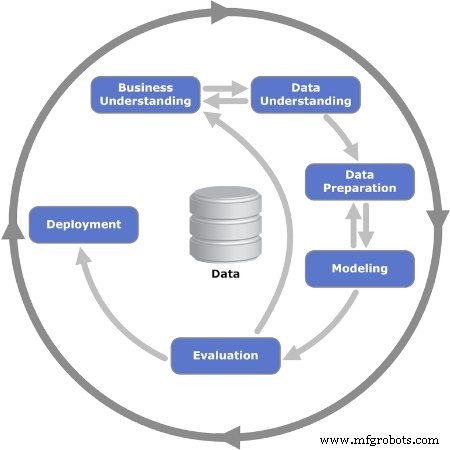
Figure 2. Les six phases itératives du modèle CRISP-DM sont présentées. Image utilisée avec l'aimable autorisation de Kenneth Jensen
Phase 1 :Compréhension commerciale
La première phase consiste en plusieurs tâches qui définissent le problème et établissent des objectifs. C'est à ce moment que les objectifs du projet sont fixés en se concentrant sur l'entreprise ou, en d'autres termes, le client. Normalement, l'équipe réunie pour travailler sur un projet Big Data doit fournir une solution au client, qui peut être un autre domaine ou département au sein de l'entreprise.
Une fois le besoin ou le problème de l'entreprise établi, l'étape suivante consiste à définir les critères de réussite. Il peut s'agir d'indicateurs de performance clés (KPI) ou d'accords de niveau de service (SLA), qui fournissent des moyens objectifs d'évaluer les progrès et l'achèvement.
Ensuite, la situation de l'entreprise doit être analysée pour identifier les risques, les plans de restauration, les mesures d'urgence et, plus important encore, la disponibilité des ressources. Un plan de projet est présenté, y compris les ressources des jalons.
Phase 2 :Compréhension des données
Une fois les fondamentaux posés lors de la phase précédente, il est temps de se concentrer sur les données. Cette phase commence par une définition initiale des données jugées nécessaires, puis documente certains détails à ce sujet :où les trouver, type de données, format, relations entre les différents champs de données, etc.
Une fois la première documentation prête, l'étape suivante consiste à exécuter le premier cycle de collecte de données. Cela donne un aperçu utile de la formation de la structure. La qualité de cet instantané d'informations est ensuite évaluée.
Phase 3 : Préparation des données
La troisième phase renforce la phase précédente et prépare l'ensemble de données pour la modélisation. Les champs de données de la première collection sont ensuite organisés et toute information jugée inutile est supprimée de l'ensemble :c'est ce qu'on appelle le nettoyage des données.
En outre, une information spécifique peut devoir être dérivée d'autres informations disponibles; d'autres fois, il doit être combiné. En d'autres termes, les données doivent être traitées pour produire un format final.
Phase 4 : Modélisation
La tâche la plus importante de cette phase est de sélectionner un algorithme pour traiter les données collectées. Dans ce contexte, un algorithme est un ensemble d'étapes de séquence et de règles programmées dans un logiciel informatique conçu pour les projets de mégadonnées.
De nombreux algorithmes peuvent être utilisés :les régressions linéaires, les arbres de décision et les machines à vecteurs de support en sont quelques exemples. Choisir le bon algorithme pour résoudre le problème nécessite des compétences dont disposent des data scientists expérimentés.
Figure 3. La régression linéaire est un type d'algorithme utilisé dans la modélisation des mégadonnées.
L'étape suivante consiste à coder l'algorithme dans l'application logicielle. C'est également à ce moment-là que la phase de test est planifiée, qui consiste à allouer des ensembles de données spécifiques pour les tests et la validation.
Phase 5 : Évaluation
Parfois, il est difficile de choisir un algorithme dès le départ. Lorsque cela se produit, les scientifiques exécutent plusieurs algorithmes et analysent les résultats pour prendre une décision finale. Une fois la phase de test terminée, les résultats sont examinés pour vérifier leur exhaustivité et leur exactitude.
Plus important encore, c'est l'occasion d'évaluer si les résultats mènent à une solution. Dans le modèle itératif, il s'agit d'une intersection cruciale où des séquences d'itération majeures peuvent être lancées, ou une décision de passer à la phase finale peut être prise.
Phase 6 :Déploiement
C'est à ce moment que le projet passe d'un environnement de test à un environnement de production en direct. La planification du calendrier et de la stratégie de déploiement est très importante pour réduire les risques et les temps d'arrêt potentiels du système.
Bien que le schéma du modèle suggère que c'est la fin du projet, il reste encore de nombreuses étapes à suivre par la suite :surveillance et maintenance. La surveillance est une période d'observation rapprochée, également connue sous le nom d'hyper care, immédiatement après la mise en service. La maintenance est un processus semi-permanent de maintenance et de mise à niveau de la solution mise en œuvre.
Les mégadonnées sont appelées ainsi pour une raison :il y a une énorme quantité de données à analyser. La mise en œuvre de l'un des modèles de cycle de vie de la science des données aide à décider quelles informations sont dignes de conserver et d'utiliser pour des processus tels que la maintenance prédictive.
Technologie de l'Internet des objets
- Au-delà du smartphone :transformer les données en son
- IA externalisée et apprentissage en profondeur dans le secteur de la santé :la confidentialité des données est-elle menacée ?
- Maintenance dans le monde numérique
- Rationalisation du cycle de vie SIM
- Démocratiser l'IoT
- Maximiser la valeur des données IoT
- Mettre la science des données entre les mains d'experts du domaine pour fournir des informations plus précieuses
- Pourquoi la connexion directe est la prochaine phase de l'IoT industriel
- La valeur de la mesure analogique