


Extraire la valeur des données pour l'IA
Les données sont tout — à bien des égards, c'est la seule chose — pour les vendeurs de véhicules autonomes (AV) qui dépendent de l'apprentissage en profondeur comme clé de la conduite autonome.
Les données sont la raison pour laquelle les entreprises audiovisuelles accumulent des kilomètres et des kilomètres d'expérience de test sur les routes publiques, enregistrant et stockant des pétaoctets de connaissances routières. Waymo, par exemple, a revendiqué en juillet plus de 10 millions de miles dans le monde réel et 10 milliards de miles en simulation.
Mais voici une autre question que l'industrie n'aime pas poser :
Supposons que les sociétés AV aient déjà collecté des pétaoctets ou même des exaoctets de données sur de vraies routes. Quelle partie de cet ensemble de données a été étiquetée ? Peut-être plus important, quelle est la précision des données qui ont été annotées ?
Dans une récente interview avec EE Times, Phil Koopman, co-fondateur et directeur technique d'Edge Case Research, a affirmé que « personne ne peut se permettre de tout étiqueter ».
Étiquetage des données :long et coûteux
L'annotation nécessite généralement des yeux humains experts pour regarder un court clip vidéo, puis dessiner et étiqueter des cases autour de chaque voiture, piéton, panneau de signalisation, feu de circulation ou tout autre élément potentiellement pertinent pour un algorithme de conduite autonome. Le processus est non seulement long, mais très coûteux.
Un article récent sur Medium intitulé « Data Annotation : The Billion Dollar Business Behind AI Breakthroughs » illustre l'émergence rapide de « services d'étiquetage de données gérées » conçus pour fournir des données étiquetées spécifiques à un domaine en mettant l'accent sur le contrôle de la qualité. L'histoire notait :
En plus de leurs équipes internes d'étiquetage de données, les entreprises technologiques et les startups autonomes s'appuient également fortement sur ces services d'étiquetage gérés… certaines entreprises autonomes paient entreprises d'étiquetage de données représentant plus de millions de dollars par mois.
Dans une autre histoire d'IEEE Spectrum il y a quelques années, Carol Reiley, cofondatrice et présidente de Drive.ai a été citée en disant :
Des milliers de personnes étiquettent des cases autour des choses. Pour chaque heure de conduite, il faut environ 800 heures humaines pour étiqueter. Ces équipes vont toutes lutter. Nous sommes déjà des magnitudes plus rapides et nous optimisons constamment.
Certaines entreprises, telles que Drive, utilisent l'apprentissage en profondeur pour améliorer l'automatisation de l'annotation des données, afin d'accélérer le processus fastidieux d'étiquetage des données.
Utilisons des données sans libellé
Koopman, cependant, pense qu'il existe un autre moyen de « tirer la valeur des données accumulées ». Que diriez-vous d'accomplir cela « sans étiqueter la plupart des pétaoctets de données enregistrées ? »
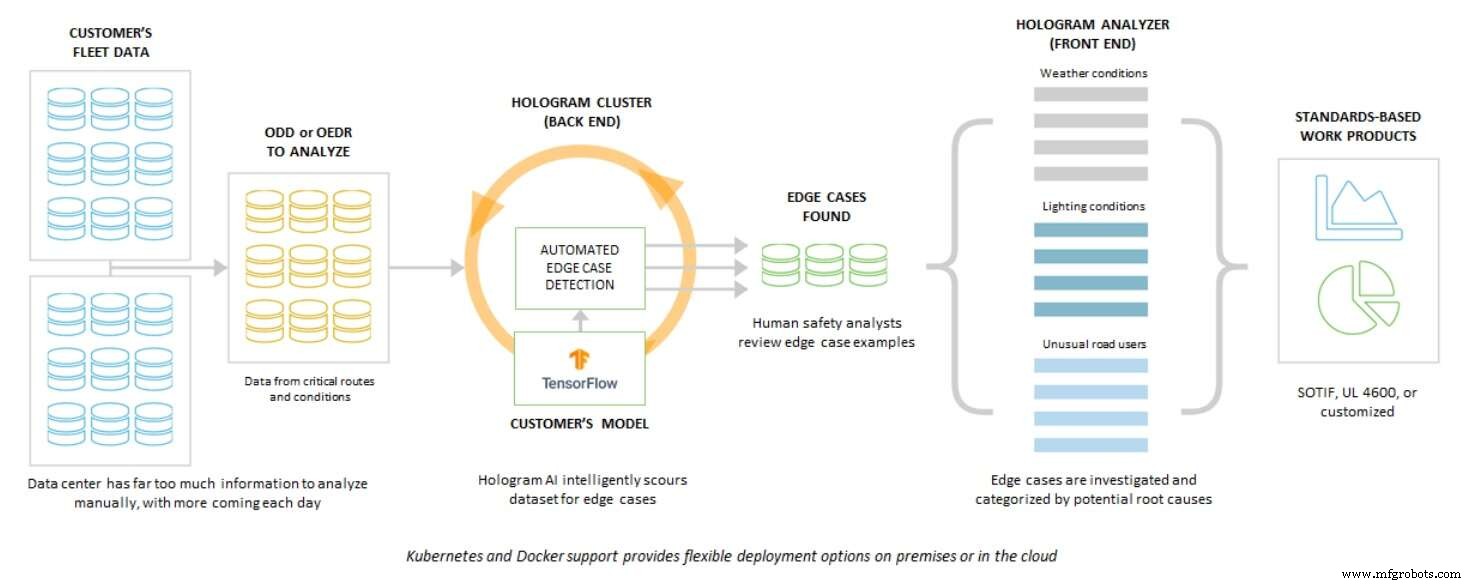
Il a expliqué qu'Edge Case Research "est tombé sur" cela, lors de la conception d'un moyen de permettre à l'industrie audiovisuelle d'accélérer le développement d'un logiciel de perception plus sûr. Edge Case Research l'appelle « Hologramme », qui est essentiellement un « système de test de stress et d'analyse des risques de perception de l'IA » conçu pour les AV.
Plus précisément, comme l'a expliqué Koopman, « Hologram utilise des données sans étiquette » et le système exécute deux fois les mêmes données sans étiquette.
Premièrement, il exécute des données de base non étiquetées sur un moteur de perception normal prêt à l'emploi. Ensuite, avec les mêmes données non étiquetées, Hologram est appliqué, ajoutant une très légère perturbation - le bruit. En mettant l'accent sur le système, Hologram, en fin de compte, peut révéler une faiblesse potentielle de la perception dans les algorithmes d'IA.
Si un petit grain est ajouté à un clip vidéo, par exemple, un humain pourrait percevoir qu'« il y a quelque chose là-bas, mais je ne sais pas ce que c'est. »
Mais un système de perception piloté par l'IA, soumis à un stress, peut soit rater totalement un objet inconnu, soit lui faire franchir le seuil et le placer dans un bac de classification différent.
Lorsque l'IA est encore en train d'apprendre, il est utile de connaître son niveau de confiance (car il détermine ce qu'il voit). Mais lorsque l'IA est appliquée dans le monde, le niveau de confiance ne nous dit pas grand-chose. L'IA est souvent « deviner » ou simplement « assumer ».
En d'autres termes, l'IA fait semblant.
L'hologramme, par conception, peut « pousser » le logiciel de perception piloté par l'IA. Il expose où un système d'IA a échoué. Par exemple, un système stressé résout sa confusion en faisant mystérieusement disparaître un objet de la scène.
Peut-être, plus intéressant encore, Hologram peut également identifier, sous le bruit, où l'IA « a presque échoué » mais a deviné juste. L'hologramme révèle des zones dans un clip vidéo où le système basé sur l'IA « aurait pu autrement être malchanceux », a déclaré Koopman.
Sans étiqueter des pétaoctets de données mais en l'exécutant deux fois, Hologram peut fournir une indication là où les choses ont l'air « de louche » et des domaines où « vous feriez mieux de revenir en arrière et de regarder à nouveau » en collectant plus de données ou en faisant plus de formation, a déclaré Koopman .
Ceci, bien sûr, est une version très simplifiée de Hologram, car l'outil lui-même, en réalité, "est livré avec beaucoup de sauces secrètes soutenues par une tonne d'ingénierie", a déclaré Koopman. Mais si Hologram peut dire aux utilisateurs « seulement les bonnes parties » qui méritent un examen humain, cela peut constituer un moyen très efficace d'obtenir une valeur réelle des données actuellement verrouillées.
"Les machines sont incroyablement douées pour jouer avec le système", a noté Koopman. Ou « faire des choses comme le « p-hacking ». » Le p-hacking est un type de biais qui se produit lorsque les chercheurs collectent ou sélectionnent des données ou des analyses statistiques jusqu'à ce que des résultats non significatifs deviennent significatifs. Les machines, par exemple, peuvent trouver des corrélations dans les données là où il n'y en a pas.
Ensemble de données open source
Lorsqu'on lui a demandé s'il s'agissait d'une bonne nouvelle pour Edge Case Research, Koopman a déclaré :« Malheureusement, ces ensembles de données ne sont disponibles que pour la communauté des chercheurs. Pas pour l'usage commercial."
De plus, même si vous utilisez un tel ensemble de données pour exécuter Hologram, vous devez utiliser le même moteur de perception utilisé pour collecter des données, pour comprendre les zones de faiblesse de votre système d'IA.
Capture d'écran de l'hologramme
Vous trouverez ci-dessous une capture d'écran montrant le fonctionnement de la dernière version commerciale d'Hologram.
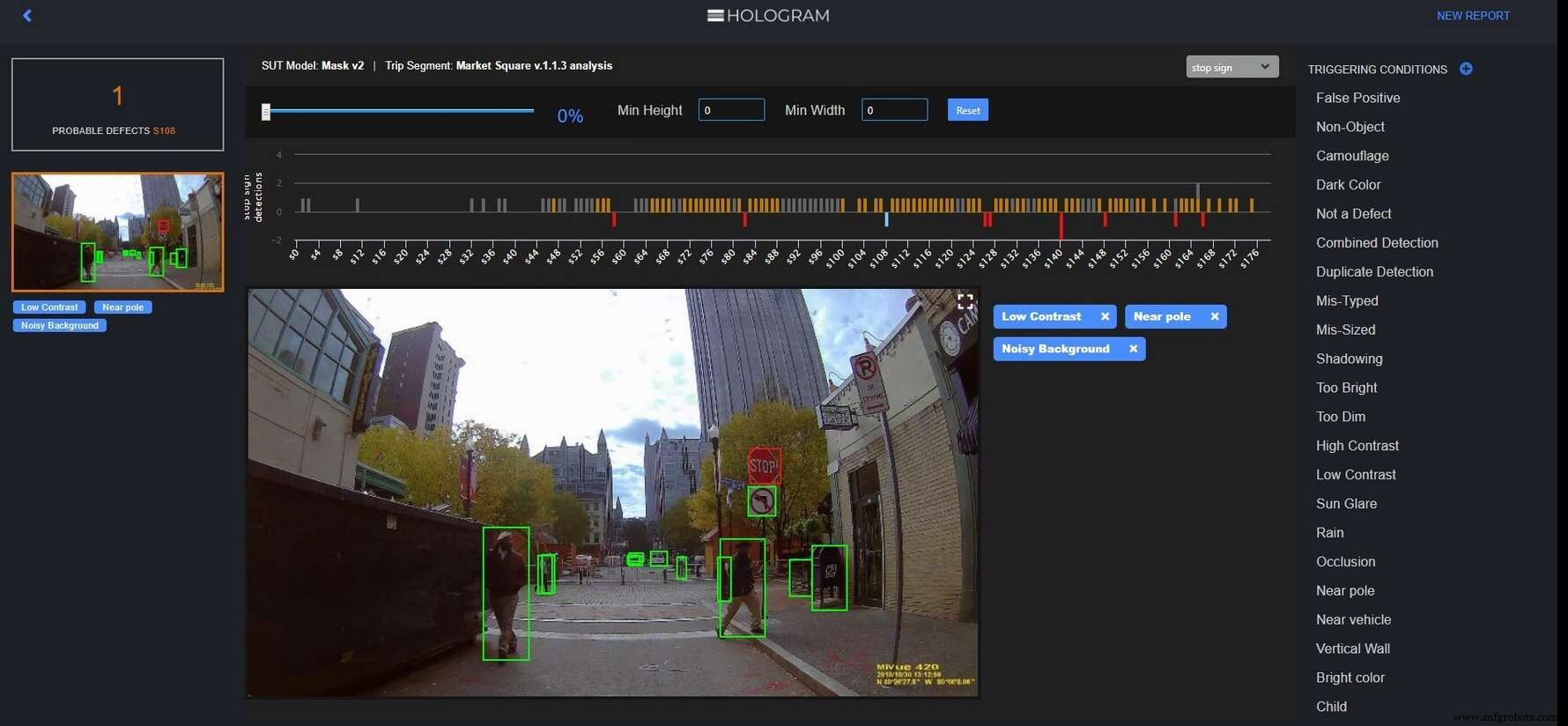
Le moteur d'hologramme trouve les cas où un système de perception n'a pas réussi à identifier ce panneau d'arrêt et fournit aux analystes des outils puissants pour découvrir les conditions de déclenchement telles que le bruit de fond. (Source :Étude de cas Edge)
En ajoutant du bruit, Hologram recherche les conditions de déclenchement qui ont fait qu'un système d'IA a presque manqué un panneau d'arrêt (barres orange) ou a complètement échoué à reconnaître un panneau d'arrêt (barres rouges vers le bas).
Les barres orange avertissent les concepteurs d'IA des domaines spécifiques qui nécessitent un recyclage de l'algorithme AL, en collectant plus de données. Les barres rouges permettent aux concepteurs d'IA d'explorer et de spéculer sur les conditions de déclenchement :qu'est-ce qui a fait que l'IA a raté le panneau d'arrêt ? Le signe était-il trop près d'un poteau ? Y avait-il un fond bruyant ou pas assez de contraste visible ? Lorsque suffisamment d'exemples de conditions de déclenchement s'accumulent, il peut être possible d'identifier des déclencheurs spécifiques, a expliqué Eben Myers, chef de produit d'Edge Case Research.
 Hologram aide les concepteurs audiovisuels à trouver les cas limites où leur logiciel de perception présente un comportement étrange et potentiellement dangereux. (Source :Étude de cas Edge)
Hologram aide les concepteurs audiovisuels à trouver les cas limites où leur logiciel de perception présente un comportement étrange et potentiellement dangereux. (Source :Étude de cas Edge)
Partenariat avec Ansys
Plus tôt cette semaine, Ansys a annoncé un accord de partenariat avec Edge Case Research. Ansys prévoit d'intégrer Hologram dans son logiciel de simulation. Ansys considère l'intégration comme un composant sous-jacent essentiel pour concevoir « la première chaîne d'outils de simulation holistique du secteur pour le développement d'AV ». Ansys collabore avec BMW, qui a promis de livrer son premier AV en 2021.

ANSYS et BMW créent une chaîne d'outils de simulation pour la conduite autonome (Source :Ansys)
— Junko Yoshida, co-rédacteur en chef mondial, AspenCore Media, correspondant international en chef, EE Times
>> Cet article a été initialement publié le notre site jumeau, EE Times :« Utilisez des données non étiquetées pour voir si l'IA fait juste semblant. »
Technologie de l'Internet des objets
- Que dois-je faire avec les données ? !
- Perspectives de développement de l'IoT industriel
- Le potentiel d'intégration de données visuelles avec l'IoT
- Démocratiser l'IoT
- Maximiser la valeur des données IoT
- Il est temps de changer :une nouvelle ère à la limite
- La valeur de la mesure analogique
- Préparer le terrain pour le succès de la science des données industrielles
- Les tendances continuent de pousser le traitement vers la périphérie pour l'IA