


Extension de l'architecture RISC-V avec des accélérateurs spécifiques au domaine
Lorsque le marché RISC-V a commencé, la précipitation initiale était de réduire les coûts des conceptions qui auraient autrement utilisé des architectures de jeu d'instructions de processeur (ISA) propriétaires dans des applications profondément intégrées. Lorsque ces systèmes sur puces (SoC) ont commencé à être fabriqués dans la technologie de traitement des semi-conducteurs FinFET, les coûts des masques sont devenus si chers que de nombreuses machines à états finis ont été remplacées par des micro-séquenceurs programmables basés sur le jeu d'instructions RISC-V. Ceux-ci ont créé l'enthousiasme initial et plus tard la banalisation des cœurs RISC-V simples de 2014 à 2018.
Au fur et à mesure que l'architecture RISC-V est devenue plus mature et que les concepteurs de SoC se sont familiarisés avec l'ISA, elle a été adoptée dans les applications en temps réel qui exigeaient des performances élevées :en particulier, servant de front-end à des moteurs d'accélération hautement spécialisés pour des applications telles que l'intelligence artificielle. . L'une des principales raisons de cette adoption est que RISC-V est une architecture ouverte permettant aux utilisateurs d'ajouter des instructions, de sorte que les processeurs RISC-V n'ont pas eu à traiter les accélérateurs comme des périphériques d'E/S mappés en mémoire, comme c'était le cas pour les architectures traditionnelles. . Au lieu de cela, ils peuvent utiliser un coprocesseur à faible latence.
La disponibilité des processeurs RISC-V avec extension vectorielle a permis à des accélérateurs spécialisés de traiter les couches entre les boucles internes du noyau pour des applications telles que l'intelligence artificielle (IA), la réalité augmentée/réalité virtuelle (AR/VR) et la vision par ordinateur. Mais cela n'est pas possible sans des extensions spécialement conçues, telles qu'une instruction de chargement personnalisée pour transférer les données d'un accélérateur externe dans des registres vectoriels internes.
Le modèle de programmation exigé par ces applications est à l'origine de ce changement. L'accélérateur à usage spécial - qui est un large éventail de multiplicateurs - est très efficace, bien que plutôt rigide, à la fois dans les opérations qu'il effectue et dans le mouvement des données. Comparez cela avec un processeur à usage général comme le x86 qui permet au programmeur la flexibilité ultime pour programmer sans tenir compte des contraintes du moteur de calcul - si seulement la conception a 100 W de puissance à brûler, ce qui n'est pas le cas pour la plupart.
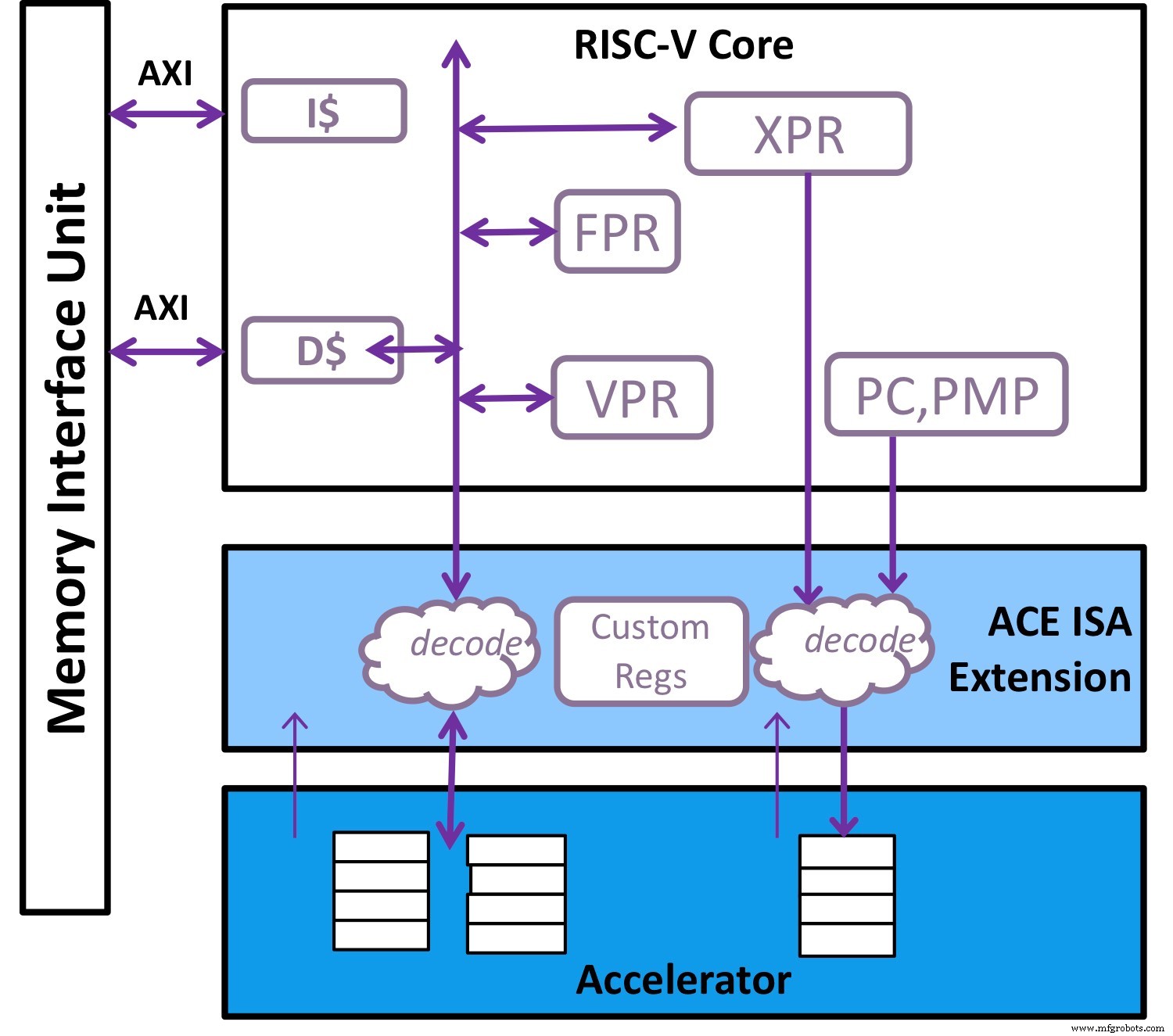
L'extension vectorielle standard dans RISC-V augmentée d'instructions personnalisées spécialisées est un compagnon idéal pour l'accélérateur (Image :Andes Technology)
La solution évidente consiste à combiner la flexibilité d'un processeur à usage général avec un accélérateur capable de gérer une tâche très spécifique (voir la figure ci-dessus). Dans RISC-V, l'extension vectorielle standard en cours de maturation augmentée d'instructions personnalisées spécialisées est un compagnon idéal pour l'accélérateur, et cette adoption est devenue apparente au cours des 18 derniers mois alors que les solutions d'accélération spécifique au domaine (DSA) convergent vers les plates-formes RISC-V.
Pour rendre cette vision possible, nous avons observé que l'accélérateur doit être capable d'exécuter son propre jeu de commandes en utilisant ses propres ressources dont la mémoire. Pour rationaliser l'exécution de l'accélérateur, le RISC-V devrait également être capable d'aplatir le microcode aussi large que nécessaire et de regrouper toutes les informations de contrôle requises vers l'accélérateur en une seule commande. De plus, cet ensemble de commandes d'accélérateur doit connaître les registres scalaires et les registres vectoriels du processeur RISC-V ainsi que ses propres ressources telles que les fichiers de registre de contrôle et la mémoire.
Lorsque l'accélérateur a besoin d'aide pour réorganiser ou manipuler les données de manière spéciale, l'architecture des Andes gère cela avec une unité de traitement vectoriel (VPU) pour gérer le travail compliqué de déplacement, de collecte, de compression et d'extension des permutations de données. Entre les couches, il y a des noyaux qui entraînent des complications. Ici, le VPU offre la flexibilité nécessaire pour répondre à ce besoin. Dans ces sockets, l'accélérateur et le VPU effectuent tous deux une énorme quantité de calculs parallèles; par conséquent, nous avons ajouté du matériel pour augmenter considérablement la bande passante du sous-système de mémoire pour répondre à la demande de calcul, y compris, mais sans s'y limiter, les transactions de prélecture et non bloquantes avec retour dans le désordre.
Le premier processeur vectoriel RISC-V d'Andes Technology prenant en charge la dernière version V-extension 0.8, le NX27V, effectue chaque calcul dans l'unité d'entiers 8 bits, 16 bits et 32 bits en virgules flottantes 16 bits et 32 bits. Il prend également en charge les formats Bfloat16 et Int4 pour réduire le stockage et la bande passante de transfert pour les valeurs de poids des algorithmes d'apprentissage automatique. La spécification vectorielle RISC-V est très flexible en permettant aux concepteurs de configurer les paramètres de conception clés tels que la longueur du vecteur, le nombre de bits dans chaque registre vectoriel et la largeur SIMD, le nombre de bits traités par le moteur vectoriel à chaque cycle.
Le NX27V a une longueur vectorielle allant jusqu'à 512 bits et extensible jusqu'à 4096 bits en combinant jusqu'à huit registres vectoriels. Avec plusieurs unités fonctionnelles supplémentaires fonctionnant dans des pipelines parallèles, il peut supporter les débits de calcul nécessaires dans des applications diversifiées. Dans une implémentation configurée avec une longueur vectorielle de 512 bits et la même largeur SIMD, il atteint une vitesse de 1 GHz en 7 nm dans le pire des cas dans une zone de 0,3 mm 2 . Pour le support du développement logiciel, en plus du compilateur, du débogueur, des bibliothèques vectorielles et du simulateur de cycle, un outil de visualisation pour le pipeline NX27V, Clarity, permet d'analyser et d'optimiser les performances des boucles critiques. Cette solution a déjà commencé à être livrée dans notre programme d'accès anticipé.
Au cours des 15 derniers mois, nous avons constaté une forte demande de hautes performances avec l'ajout d'une puissante extension vectorielle RISC-V, l'associant à un sous-système de mémoire à large bande passante et rapprochant l'accélérateur du processeur. C'est le type d'exigence informatique qui, selon nous, stimulera la demande de RISC-V et de traitement vectoriel.
>> Cet article a été initialement publié le notre site partenaire, EE Times.
Embarqué
- Présentation de l'IIC, maintenant avec OpenFog !
- La 2e version de l'architecture de référence de l'Internet industriel est sortie avec le bus de données en couches
- Combattre les incendies de forêt avec l'IoT
- Atteindre l'inaccessible avec l'IoT par satellite
- Impression du fusible 1 avec le fusible 1
- Que dois-je faire avec les données ? !
- Edge computing :L'architecture du futur
- Sécurisation du vecteur de menace IoT
- En route avec l'IoT