


Comment entraîner un algorithme pour détecter et prévenir la cécité précoce
Un dispositif médical portable capable de détecter avec précision les différents stades de la rétinopathie diabétique, sans avoir besoin d'une connexion Internet, réduirait considérablement le nombre de cas de cécité dus à la rétinopathie dans le monde. Avec l'apprentissage automatique intégré, il est désormais possible de développer des algorithmes qui peuvent s'exécuter directement sur des appareils médicaux alimentés par batterie et effectuer une détection ou un diagnostic. Dans cet article, nous proposons une présentation des étapes nécessaires pour entraîner rapidement un algorithme afin de fournir cette capacité à l'aide d'une plate-forme logicielle d'Edge Impulse.
La rétinopathie diabétique est une affection dans laquelle des dommages surviennent aux vaisseaux sanguins dans les tissus situés à l'arrière de l'œil. Elle peut survenir chez les personnes diabétiques et dont la glycémie est mal gérée. Dans les cas chroniques extrêmes, la rétinopathie diabétique peut conduire à la cécité.
Plus de deux Américains sur cinq atteints de diabète souffrent d'une forme de rétinopathie diabétique. Cela rend la détection précoce critique, à quel point le mode de vie ou une intervention médicale peut être effectué. Pour les zones rurales du monde entier où l'accès aux soins de la vue est limité, les stades de la rétinopathie sont encore plus difficiles à détecter plus tôt avant qu'un cas ne s'aggrave. En utilisant la détection de la rétinopathie diabétique comme objectif, nous avons cherché à prendre des données médicales accessibles au public et à former un modèle d'apprentissage automatique dans Edge Impulse qui pourrait exécuter l'inférence directement sur un appareil de pointe. L'algorithme serait idéalement capable d'évaluer la gravité de la rétinopathie diabétique entre les images des yeux prises par une caméra rétinienne. L'ensemble de données que nous avons utilisé pour ce projet peut être trouvé ici.
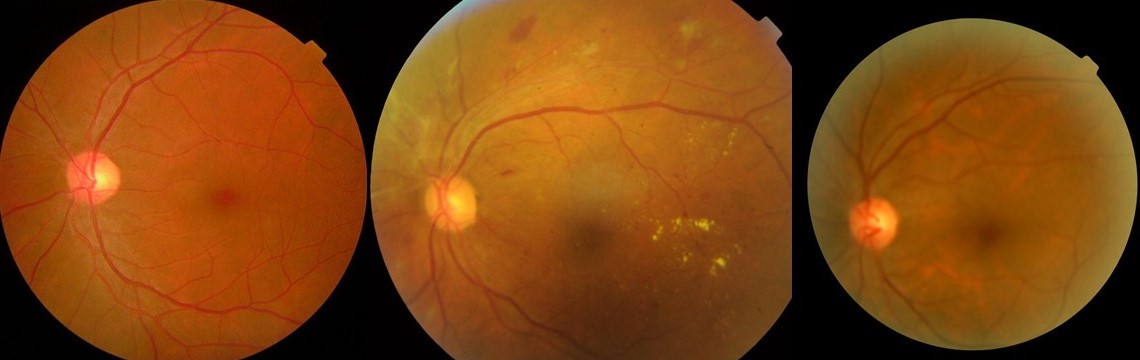
Pour cet algorithme, nous avons divisé les classes en cinq ensembles de données différents :
- Pas de rétinopathie diabétique (Pas de RD)
- DR légère
- RD modérée
- RD sévère
- RD proliférative
Comme pour de nombreux ensembles de données accessibles au public, un nettoyage et un étiquetage des données ont dû être effectués.
Pour protéger l'identité des patients, chaque image de l'ensemble de données a simplement reçu un id_code et un diagnostic de 0 à 5, 0 étant la gravité la plus faible de l'absence de DR et 5 étant la pire ou DR proliférative.
Afin d'ingérer les données dans Edge Impulse, un certain partitionnement des images devait se produire. Compte tenu de la nature simple de la façon dont les données ont été divisées, j'ai décidé d'écrire un script VBA pour lire l'image id_code à partir d'Excel, récupérer l'image associée et la placer dans son dossier respectif. Le script pour déplacer ces fichiers est lié ici. Pour ceux qui ont de meilleures compétences en Python ou en d'autres langages de script, il existe de nombreuses façons de le faire, qui pourraient même être plus simples.
Edge Impulse possède d'autres fonctionnalités d'ingestion de données telles que l'intégration de compartiments de données cloud ou la collecte de données à partir d'appareils, mais le téléchargement de données était la méthode que j'ai utilisée ici. En utilisant l'option de téléchargement de données, j'ai pu apporter dans mes 5 classes différentes une série de cinq téléchargements. Chaque téléchargement consistait à étiqueter les données comme l'une des 5 classes et à télécharger les images associées contenues dans chaque dossier.
Edge Impulse a la possibilité de diviser automatiquement les données en données d'entraînement ou de test avec une répartition 80/20. Cependant, j'ai ajouté manuellement environ 500 images dans les différentes classes à l'ensemble de données de test.
Ensuite, il était temps de configurer mon modèle et de choisir le bloc de traitement du signal et le bloc de réseau neuronal pour ce modèle. Pour ce modèle, j'ai introduit le bloc image dans un bloc d'apprentissage par transfert dans le but de différencier cinq classes différentes.
De là, je suis allé former le réseau de neurones. En jouant avec les paramètres du réseau de neurones, la meilleure précision que j'obtenais était d'environ 74%. Pas mal, mais le modèle restait bloqué en ce qui concerne certains des cas extrêmes. Par exemple, la RD sévère était parfois classée comme RD légère. Le modèle n'était pas très précis au fur et à mesure que DR progressait, comme vous pouvez le voir dans la capture d'écran ci-dessous.
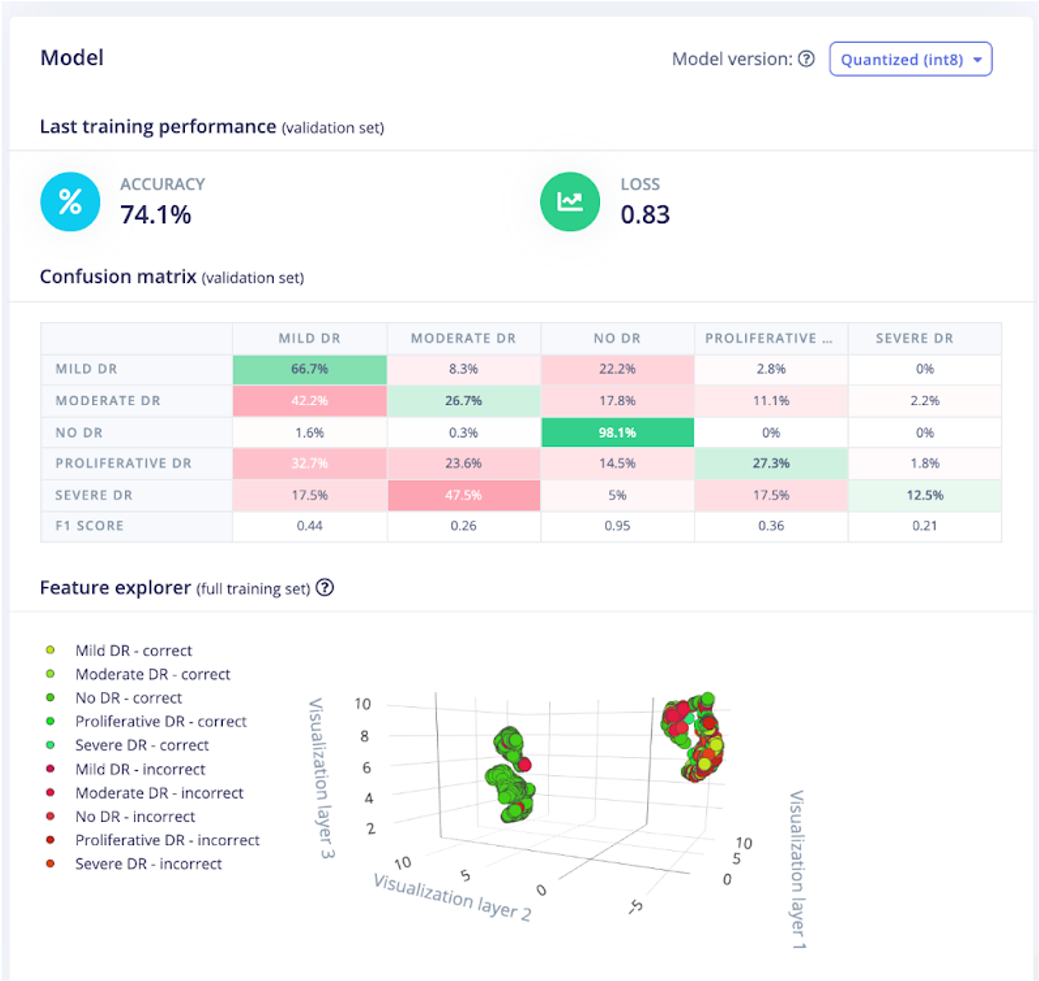
Cela m'a fait penser aux applications réelles d'un projet comme celui-ci et si ce niveau de précision serait acceptable. Idéalement, une sorte de caméra d'imagerie rétinienne portable (dans un environnement à faible connectivité sans fil) pourrait exécuter un algorithme comme celui-ci sur l'appareil lui-même. Lorsque la photo est prise, traitée et le résultat obtenu, la personne administrant le test oculaire peut alors dire au patient qu'il doit aller chercher une aide ou une intervention médicale supplémentaire, en fonction du résultat.
Pour cette application, il est plus important de détecter la RD à tous les stades afin que le patient puisse soit commencer un traitement préventif, soit pour les cas plus graves, rechercher une aide médicale immédiate. Compte tenu de ce cas d'utilisation, le modèle sert en fait relativement bien son application potentielle.
De mémoire, il y a quelques modifications ou améliorations que je pourrais apporter au modèle, qui pourraient rendre la sortie résultante plus précise en termes de diagnostic de la gravité de la DR :
- Plus de données, c'est toujours mieux. Cependant, étant donné cet ensemble de données limité, une collecte de données supplémentaire serait nécessaire.
- Une idée pourrait être de combiner les classes, en créant une classe légère – modérée et une classe proliférative – sévère. Je me demande si cela pourrait aider l'algorithme à mieux classer, étant donné les similitudes entre certains cas de RD légère et modérée, qui appartiendraient désormais tous au même groupe.
Jouez avec le nombre de couches au sein du réseau de neurones (NN), ainsi que le décrochage.

Du point de vue du déploiement, ce modèle entraîné avait une plus grande empreinte en termes de mémoire, occupant environ 306 Ko de Flash et 236 Ko de RAM. Selon l'appareil sélectionné pour exécuter l'inférence, le temps nécessaire pour qu'un résultat d'inférence soit renvoyé était compris entre 0,8 seconde et 6 secondes, lors de l'analyse comparative sur un Cortex-M4 à 80 MHz ou un Cortex-M7 à 216 MHz. Étant donné que ce produit final devrait cependant prendre des images, je prévois que quelque chose comme les capacités de traitement du Cortex-M7 ou plus serait nécessaire.
En résumé, à l'aide d'un ensemble de données open source, nous avons pu former un modèle d'apprentissage automatique relativement performant pour détecter diverses formes de rétinopathie diabétique (RD). L'objectif final serait de déployer des modèles comme celui-ci directement sur le microcontrôleur intégré ou l'appareil Linux et d'avoir plus de dispositifs médicaux comme celui ci-dessous pour exécuter l'inférence à la périphérie. Cela ouvre de nouvelles possibilités pour les services de santé, en fournissant une technologie médicale qui peut être utilisée dans les zones rurales, sans connectivité sans fil pour fournir des tests aux populations qui ont un faible accès aux soins de santé.
Il existe en effet une bonne opportunité pour le déploiement de l'apprentissage automatique (ML) embarqué dans les dispositifs médicaux. Plus de détails sur ce projet, y compris d'autres possibilités d'amélioration, sont disponibles ici.
Embarqué
- Le cloud et comment il change le monde informatique
- Quatre types de cyberattaques et comment les prévenir
- Comment prévenir les problèmes courants de machinerie lourde et d'équipement
- Qu'est-ce que la porosité du soudage et comment la prévenir ?
- Qu'est-ce que la rouille et comment prévenir la rouille ? Un guide complet
- Principales causes de panne de machine et comment les prévenir
- Qu'est-ce que l'interopérabilité et comment mon entreprise peut-elle y parvenir ?
- Les pièges de la protection des machines et comment les éviter
- Comment détecter les fuites et les réparer