


Compilateurs dans le monde étranger de la sécurité fonctionnelle
Dans tous les secteurs, le monde de la sécurité fonctionnelle impose de nouvelles exigences aux développeurs. Un code fonctionnellement sûr doit inclure un code défensif pour se défendre contre des événements inattendus pouvant résulter de diverses causes. Par exemple, une corruption de mémoire due à des erreurs de codage ou à des événements de rayons cosmiques peut conduire à l'exécution de chemins de code « impossibles » selon la logique du code. Les langages de haut niveau, en particulier C et C++, incluent un nombre surprenant de fonctionnalités dont le comportement n'est pas prescrit par la spécification du langage auquel le code adhère. Ce comportement indéfini peut conduire à des résultats inattendus et potentiellement désastreux qui seraient inacceptables dans une application fonctionnellement sûre. Pour ces raisons, les normes exigent qu'un codage défensif soit appliqué, que le code soit testable, qu'il soit possible de rassembler une couverture de code adéquate et que le code d'application soit traçable par rapport aux exigences pour garantir que le système les implémente entièrement et de manière unique.
Le code doit également atteindre des niveaux élevés de couverture de code, et dans certains secteurs, en particulier l'automobile, il est courant que la conception nécessite des outils de diagnostic, d'étalonnage et de développement externes sophistiqués. Le problème qui se pose est que les pratiques telles que le codage défensif et l'accès aux données externes ne font pas partie d'un monde que les compilateurs reconnaissent. Par exemple, ni C ni C++ ne tiennent compte de la corruption de mémoire, donc à moins que le code conçu pour la protéger ne soit accessible lorsqu'il n'y a pas de corruption, il peut simplement être ignoré lorsque le code est optimisé. Par conséquent, le code défensif doit être accessible syntaxiquement et sémantiquement s'il ne veut pas être « optimisé ».
Des exemples de comportement indéfini peuvent également causer des surprises. Il est facile de suggérer qu'ils doivent être simplement évités, mais il est souvent difficile de les identifier. Lorsqu'ils existent, rien ne garantit que le comportement du code exécutable compilé correspondra aux intentions des développeurs. L'accès « par la porte arrière » aux données utilisées par les outils de débogage représente une autre situation à laquelle le langage ne tient pas compte, et peut donc avoir des conséquences inattendues.
L'optimisation du compilateur peut avoir un impact majeur sur tous ces domaines, car aucun d'entre eux ne fait partie du mandat des fournisseurs de compilateurs. L'optimisation peut entraîner l'élimination d'un code défensif apparemment solide lorsqu'il est associé à une « infaisabilité », c'est-à-dire lorsqu'il existe sur des chemins qui ne peuvent être testés et vérifiés par aucun ensemble de valeurs d'entrée possibles. Encore plus alarmant, le code défensif qui s'est révélé présent lors des tests unitaires pourrait bien être éliminé lors de la construction de l'exécutable du système. Ce n'est pas parce que la couverture du code défensif a été obtenue lors du test unitaire que cela garantit qu'il est présent dans le système terminé.
Dans cet étrange pays de sécurité fonctionnelle, le compilateur peut être hors de son élément. C'est pourquoi la vérification du code objet (OCV) représente la meilleure pratique pour tout système pour lequel il y a des conséquences désastreuses associées à une défaillance, et en fait, pour tout système où seule la meilleure pratique est suffisante.
Avant et après compilation
Les pratiques de vérification et de validation défendues par les normes de sécurité fonctionnelle, de sécurité et de codage telles que IEC 61508, ISO 26262, IEC 62304, MISRA C et C++ mettent considérablement l'accent sur l'affichage de la quantité de code source de l'application utilisée lors des tests basés sur les exigences.
L'expérience nous a montré que si le code s'est avéré fonctionner correctement, la probabilité d'échec sur le terrain est considérablement plus faible. Et pourtant, parce que cet effort louable se concentre sur le code source de haut niveau (quel que soit le langage), une telle approche accorde une grande confiance à la capacité du compilateur à créer un code objet qui reproduit précisément ce que les développeurs destiné. Dans les applications les plus critiques, cette hypothèse implicite ne peut pas être justifiée.
Il est inévitable que le contrôle et le flux de données du code objet ne soient pas un miroir exact du code source dont il est dérivé, et ainsi prouver que tous les chemins de code source peuvent être exercés de manière fiable ne prouve pas la même chose du code objet . Étant donné qu'il existe une relation 1:1 entre le code objet et l'assembleur, une comparaison entre le code source et le code assembleur est révélatrice. Prenons l'exemple de la figure 1, où le code assembleur sur la droite a été généré à partir du code source sur la gauche (à l'aide d'un compilateur TI avec l'optimisation désactivée).

Figure 1 :Le code assembleur de droite a été généré à partir du code source de gauche, montrant la comparaison révélatrice entre le code source et le code assembleur. (Source :LDRA)
Comme illustré plus loin, lorsque ce code source est compilé, le flowgraph du code assembleur résultant est assez différent de celui du code source car les règles suivies par les compilateurs C ou C++ leur permettent de modifier le code comme bon leur semble, à condition que le binaire se comporte « comme si c'était la même chose ».
Dans la plupart des cas, ce principe est tout à fait acceptable, mais il existe des anomalies. Les optimisations du compilateur sont essentiellement des transformations mathématiques appliquées à une représentation interne du code. Ces transformations « tournent mal » si les hypothèses ne tiennent pas - comme c'est souvent le cas lorsque la base de code comprend des instances de comportement indéfini, par exemple.
Seul le DO-178C, utilisé dans l'industrie aérospatiale, met l'accent sur le potentiel d'incohérences dangereuses entre l'intention du développeur et le comportement de l'exécutable. Cependant, de telles approches sont excusées, il n'en reste pas moins que les différences entre le code source et le code objet peuvent avoir des conséquences dévastatrices dans toute application critique.
Intention du développeur par rapport au comportement de l'exécutable
Malgré les différences claires entre les flux de code source et objet, ils ne sont pas la principale préoccupation. Les compilateurs sont généralement des applications très fiables, et bien qu'il puisse y avoir des bogues comme dans tout autre logiciel, l'implémentation d'un compilateur répondra généralement à ses exigences de conception. Le problème est que ces exigences de conception ne reflètent pas toujours les besoins d'un système fonctionnellement sûr.
En bref, on peut supposer qu'un compilateur est fonctionnellement fidèle aux objectifs de ses créateurs. Mais ce n'est peut-être pas tout à fait ce qui est souhaité ou attendu, comme illustré dans la figure 2 ci-dessous avec un exemple résultant d'une compilation avec le compilateur CLANG.

La figure 2 montre une compilation avec le compilateur CLANG (Source :LDRA)
Il est clair que l'appel défensif à la fonction « erreur » n'a pas été exprimé dans le code assembleur.
L'objet 'state' n'est modifié que lorsqu'il est initialisé et dans les cas 'S0' et 'S1', et ainsi le compilateur peut raisonner que les seules valeurs données à 'state' sont 'S0' et 'S1'. conclut que le "par défaut" n'est pas nécessaire car "état" ne contiendra jamais d'autres valeurs, en supposant qu'il n'y a pas de corruption - et en effet, le compilateur fait exactement cette hypothèse.
Le compilateur a également décidé que, comme les valeurs des objets réels (13 et 23) ne sont pas utilisées dans un contexte numérique, il utilisera simplement les valeurs 0 et 1 pour basculer entre les états, puis utilisera un "ou" exclusif pour mettre à jour la valeur de l'état. Le binaire adhère à l'obligation "comme si" et le code est rapide et compact. Dans le cadre de son mandat, le compilateur a fait du bon travail.
Ce comportement a des implications pour les outils de « calibrage » qui utilisent le fichier de mappe de mémoire de l'éditeur de liens pour accéder indirectement aux objets et pour un accès direct à la mémoire via un débogueur. Encore une fois, de telles considérations ne font pas partie du mandat du compilateur et ne sont donc pas prises en compte lors de l'optimisation et/ou de la génération de code.
Supposons maintenant que le code reste inchangé, mais que son contexte dans le code présenté au compilateur change légèrement, comme dans la figure 3.
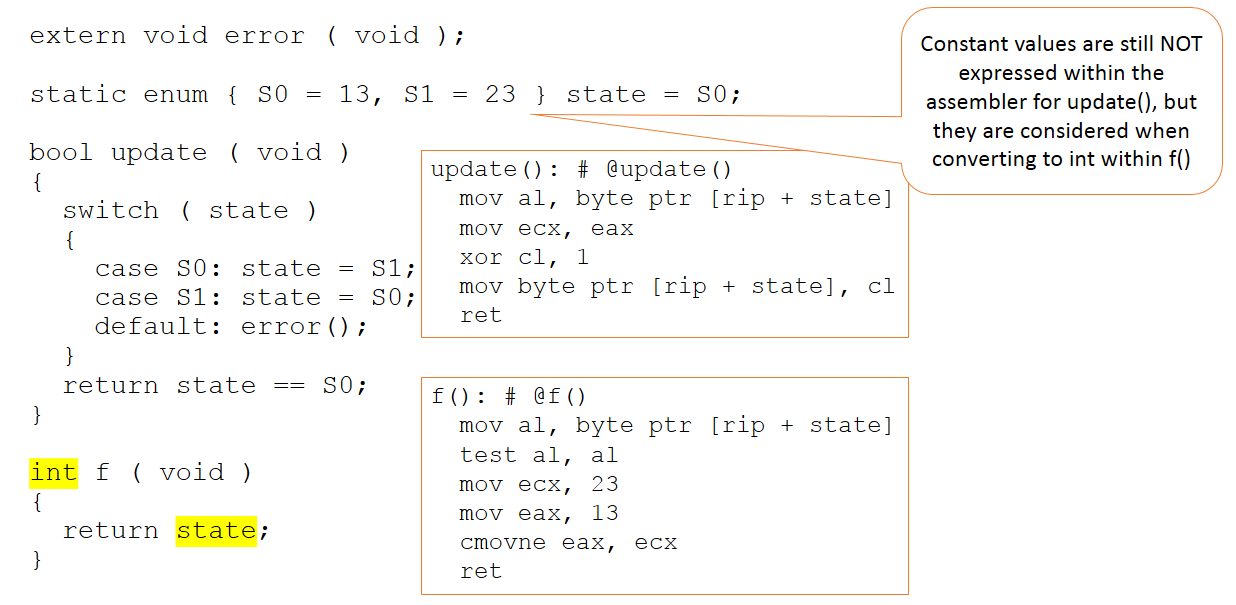
Figure 3 :Le code reste inchangé mais son contexte dans le code présenté au compilateur change légèrement. (Source :LDRA)
Il existe maintenant une fonction supplémentaire, qui renvoie la valeur de la variable d'état sous forme d'entier. Cette fois les valeurs absolues 13 et 23 importent dans le code soumis au compilateur. Même ainsi, ces valeurs ne sont pas manipulées dans la fonction de mise à jour (qui reste inchangée) et ne sont apparentes que dans notre nouvelle fonction "f".
En bref, le compilateur continue (à juste titre) à porter des jugements de valeur sur l'endroit où les valeurs de 13 et 23 doivent être utilisées - et elles ne sont en aucun cas appliquées dans toutes les situations où elles pourraient l'être.
Si la nouvelle fonction est modifiée pour renvoyer un pointeur vers notre variable d'état, le code assembleur change considérablement. Parce qu'il existe désormais un potentiel d'accès aux alias via un pointeur, le compilateur ne peut plus déduire ce qui se passe avec l'objet d'état. Comme le montre la figure 4 ci-dessous, il ne peut pas conclure que les valeurs de 13 et 23 sont sans importance et donc elles sont maintenant exprimées explicitement dans l'assembleur.
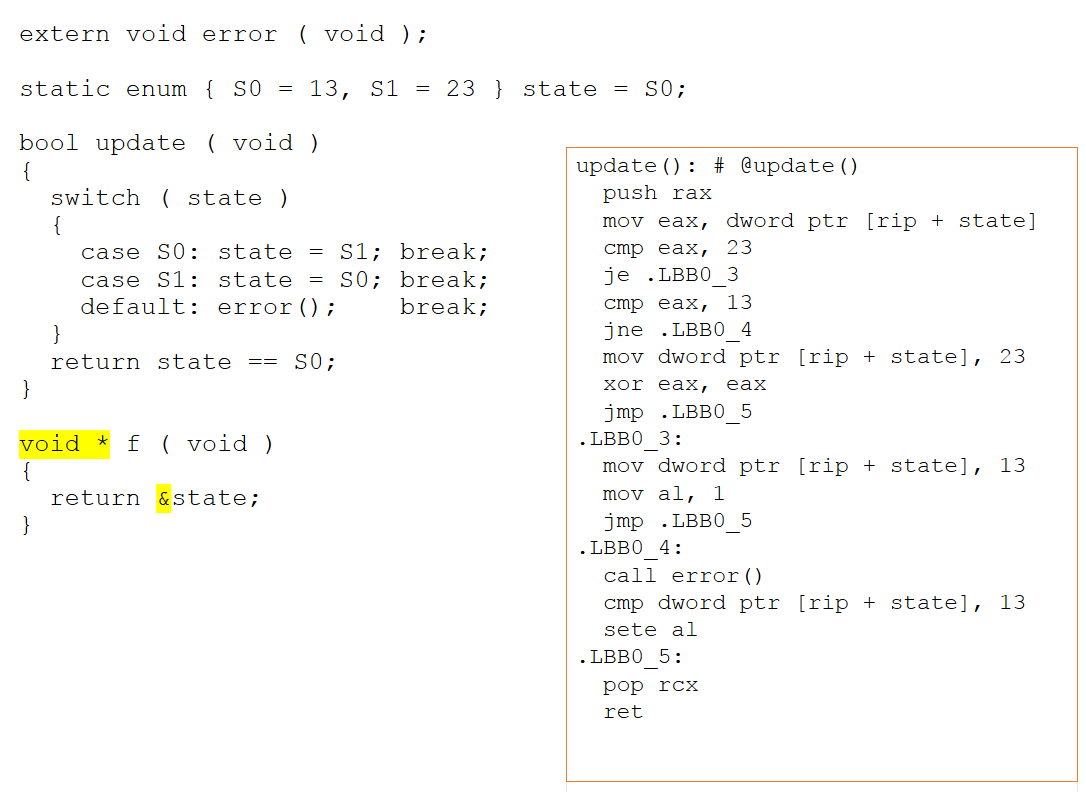
Figure 4 :Si la nouvelle fonction est modifiée pour renvoyer un pointeur vers notre variable d'état, le code assembleur change considérablement. Il ne peut pas conclure que les valeurs de 13 et 23 sont sans importance et donc elles sont maintenant exprimées explicitement au sein de l'assembleur (Source :LDRA).
Implications pour le test unitaire du code source
Considérons maintenant l'exemple dans le contexte d'un faisceau de test unitaire imaginaire. En conséquence de la nécessité d'un harnais pour accéder au code en cours de test, la valeur de la variable d'état est manipulée et, par conséquent, la valeur par défaut n'est pas « optimisée ». Une telle approche est tout à fait justifiable dans un outil de test qui n'a aucun contexte relatif au reste du code source et qui est nécessaire pour tout rendre accessible, mais comme effet secondaire, elle peut masquer l'omission légitime de code défensif par le compilateur.
Le compilateur reconnaît qu'une valeur arbitraire est écrite dans la variable d'état via un pointeur, et encore une fois, il ne peut pas conclure que les valeurs de 13 et 23 sont sans importance. Par conséquent, ils sont maintenant exprimés explicitement au sein de l'assembleur. A cette occasion, il ne peut pas conclure que S0 et S1 représentent les seules valeurs possibles pour la variable d'état, ce qui signifie que le chemin par défaut peut être réalisable. Comme le montre la figure 5, la manipulation de la variable d'état atteint son objectif et l'appel à la fonction d'erreur est maintenant apparent dans l'assembleur.

Figure 5 :La manipulation de la variable d'état atteint son but et l'appel à la fonction d'erreur est maintenant apparent dans l'assembleur. (Source :LDRA)
Cependant, cette manipulation ne sera pas présente dans le code qui sera expédié au sein d'un produit, et donc l'appel à error() n'est pas vraiment présent dans le système complet.
L'importance de la vérification du code objet
Pour illustrer comment la vérification du code objet peut aider à résoudre cette énigme, considérons à nouveau le premier exemple d'extrait de code, illustré à la figure 6 :

Figure 6 :Cela illustre comment la vérification du code objet peut aider à résoudre le fait que l'appel à l'erreur ne se trouve pas dans le système complet. (Source :LDRA)
Il est possible de démontrer que ce code C atteint une couverture de 100 % du code source au moyen d'un seul appel :
f_while4(0,3) ;
Le code peut être reformaté en une seule opération par ligne et représenté sur un organigramme comme une collection de nœuds « bloc de base », dont chacun est une séquence de code en ligne droite. La relation entre les blocs de base est représentée sur la figure 7 en utilisant des arêtes dirigées entre les nœuds.
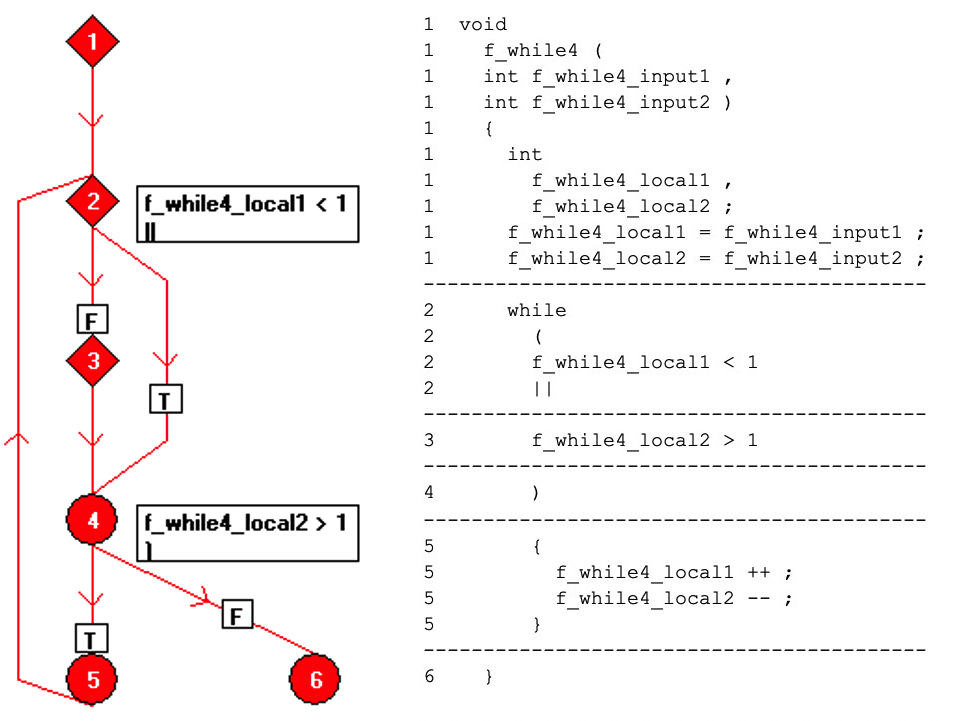
Figures 7 :Ceci montre la relation entre les blocs de base en utilisant des arêtes dirigées entre les nœuds. (Source :LDRA)
Lorsque le code est compilé, le résultat est comme indiqué ci-dessous (Figure 8). Les éléments bleus du graphe de flux représentent le code qui n'a pas été exercé par l'appel f_while4(0,3).
En tirant parti de la relation un à un entre le code objet et le code assembleur, ce mécanisme expose quelles parties du code objet ne sont pas exercées, incitant le testeur à concevoir des tests supplémentaires et à obtenir une couverture complète du code assembleur, et donc à réaliser la vérification du code objet.
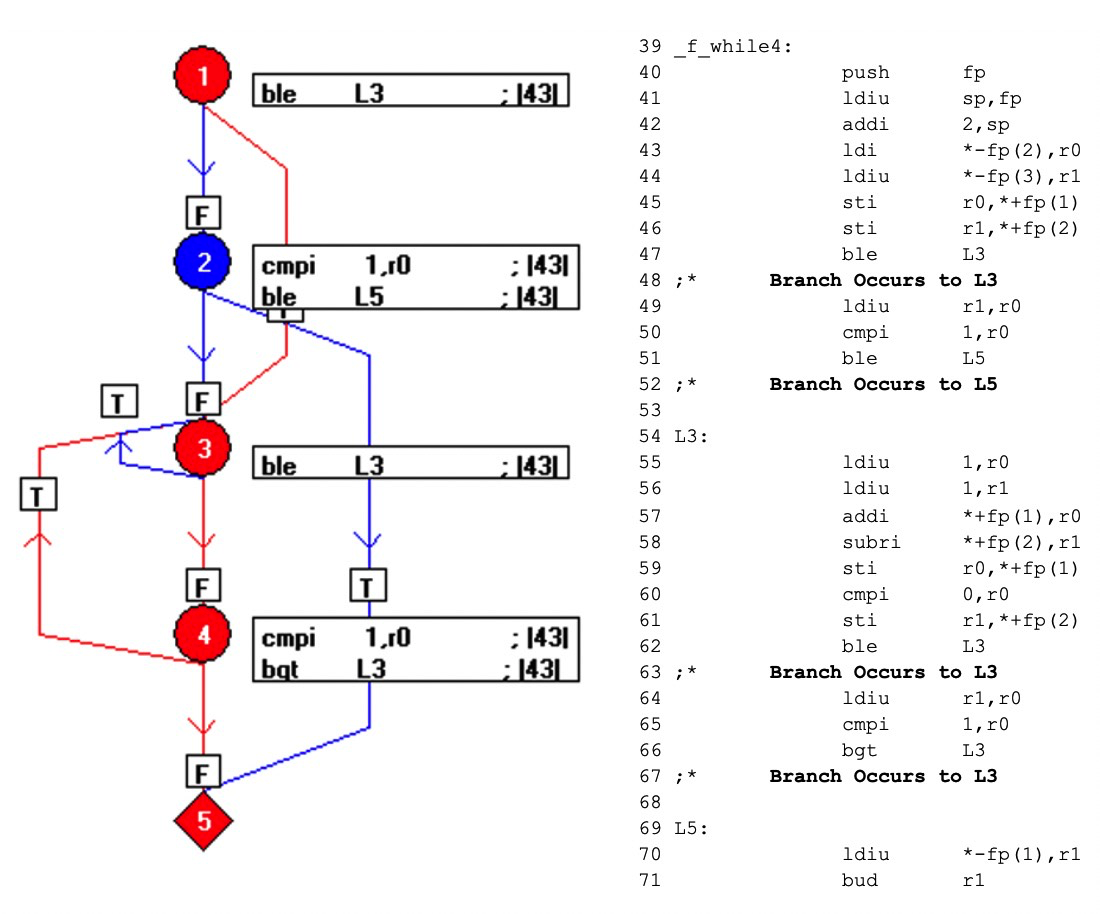
Figures 8 :Ceci montre le résultat lorsque le code est compilé. Les éléments bleus du graphe de flux représentent le code qui n'a pas été exercé par l'appel f_while4(0,3). (Source :LDRA)
De toute évidence, la vérification du code objet n'a aucun pouvoir pour empêcher le compilateur de suivre ses règles de conception et de contourner par inadvertance les meilleures intentions des développeurs. Mais il peut attirer l'attention des imprudents sur de telles inadéquations et le fait.
Considérez maintenant ce principe dans le contexte de l'exemple précédent d'« appel à l'erreur ». Le code source dans le système terminé serait, bien sûr, identique à celui prouvé au niveau des tests unitaires et donc une comparaison de cela ne révélerait rien. Mais l'application de la vérification du code objet au système achevé serait inestimable pour fournir l'assurance que le comportement essentiel est exprimé comme prévu par les développeurs.
Meilleures pratiques dans n'importe quel monde
Si le compilateur gère le code différemment dans le faisceau de test par rapport au test unitaire, alors la couverture du test unitaire du code source en vaut-elle la peine ? La réponse est un oui qualifié." De nombreux systèmes ont été certifiés sur la base de la preuve de tels artefacts et se sont avérés sûrs et fiables en service. Mais pour les systèmes les plus critiques dans tous les secteurs, si le processus de développement doit résister à l'examen le plus détaillé et adhérer aux meilleures pratiques, la couverture des tests unitaires au niveau de la source doit être complétée par OCV. Il est raisonnable de supposer qu'il remplit ses critères de conception, mais ces critères n'incluent pas les considérations de sécurité fonctionnelle. La vérification du code objet représente actuellement l'approche la plus sûre du monde de la sécurité fonctionnelle où les comportements du compilateur sont conformes aux normes, mais peuvent néanmoins avoir un impact négatif significatif.
Embarqué
- L'importance de la sécurité électrique
- Le monde des teintures textiles
- Application de teintures acides dans le monde des tissus
- Regard sur le monde des teintures
- Les nombreuses utilisations des paniers de sécurité
- Le monde de la simulation en évolution rapide
- Les capitales mondiales de la fabrication
- 5 des conseils de sécurité les plus importants pour les grues
- L'importance des matériaux de friction dans les systèmes de sécurité