


Lecteur/enregistreur de disquettes Arduino Amiga (V2.2)
Composants et fournitures
 |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 1 |
Applications et services en ligne
 |
|
À propos de ce projet
Ce projet poursuit le travail de mon précédent projet de lecteur de disque à https://create.arduino.cc/projecthub/projects/485582/
Pour plus d'informations, visitez http://amiga.robsmithdev.co.uk
- Mon objectif : Pour créer un moyen simple, bon marché et open source de récupérer et de réécrire des données depuis et vers des disquettes Amiga DD à partir de Windows 10.
- Ma solution : Un sketch Arduino + une application Windows (qui peut être porté sur d'autres O/S ) qui fonctionne réellement !
- Pourquoi : Pour préserver les données de ces disques pour l'avenir. De plus, un PC normal ne peut pas lire/écrire sur les disques Amiga en raison de la façon dont ils sont écrits.
Écriture de données - Tentative 1
Ainsi, après avoir réussi à lire les disques, j'ai pensé que si vous souhaitez conserver le support physique d'origine, vous souhaiterez peut-être réécrire les disques. J'ai pensé que je travaillerais à l'envers, en commençant par le logiciel (c'est-à-dire :convertir les fichiers du disque ADF en données MFM pour que l'interface écrive d'une manière ou d'une autre ).
J'ai donc commencé par ajouter des classes pour lire un disque ADF et encoder tous les secteurs en une seule piste. Sachant que je pouvais potentiellement tester les données que j'avais créées en les renvoyant dans la partie décodage, j'ai commencé à travailler là-dessus. En travaillant là-dessus, j'ai décidé d'essayer de découvrir ce qui n'allait pas avec mon Amiga. Après tout, je ne peux pas tester les disques que je crée si je n'ai rien de réel pour les tester.
En démontant mon A500+, j'ai remarqué qu'il avait subi l'un des problèmes les plus courants, la pile de l'horloge avait fui partout. J'ai donc dessoudé cela de la carte et j'ai commencé à nettoyer la carte. Pendant ce temps, j'ai sorti toute la machine et je me suis mis à nettoyer 20 ans de poussière et de crasse. J'ai même démonté le lecteur de disquette pour le nettoyer.
Pendant le nettoyage, j'ai décidé qu'il était temps de se débarrasser du jaunissement, alors j'ai suivi les informations sur Retr0brite et l'ai essayé.
J'ai ensuite vérifié tous les joints de la carte mère principale et trouvé une connexion lâche par le connecteur d'alimentation, quelques retouches avec le fer à souder et comme neuf. J'ai attendu d'être satisfait du processus Retr0brite avant de remonter l'ordinateur.
Pendant ce temps, j'ai continué à travailler sur le code d'écriture des disques. Je voulais lire l'état de la ligne de protection en écriture, mais peu importe ce que je lui ai réglé, cela ne semblait pas changer de tension. J'ai donc séparé le lecteur et suivi les traces des petits commutateurs qui détectent l'état de protection en écriture jusqu'à un petit circuit intégré. À ce stade, j'ai deviné que la sortie n'est probablement disponible que lorsque vous souhaitez réellement écrire des données.
Après beaucoup d'expérimentation, j'ai trouvé que vous deviez tirer le /WRITE_GATE broche LOW avant de faire tourner le lecteur pour permettre l'écriture. À ce stade, vous pouvez obtenir le statut de protection en écriture. J'ai également remarqué que tandis que le /WRITE_GATE était faible, le lecteur ne s'est pas éteint comme avant jusqu'à ce que cette broche soit revenue à son état HAUT par défaut.
L'Amiga écrirait une piste entière en une seule fois. Une piste en mémoire fait 11*512 octets (5638 octets), cependant, après encodage MFM et mise au format AmigaDOS correct, la piste revient à 14848 octets. Eh bien, il n'y a aucun moyen qui puisse tenir dans les 2k de mémoire de l'Arduino, ni ses 1k d'EEPROM. J'avais besoin d'une méthode alternative.
J'ai décidé d'essayer d'envoyer les données 1 octet à la fois dans un thread de haute priorité et d'attendre un octet de réponse de l'Arduino avant d'envoyer le suivant. J'ai changé le débit en bauds à 2M pour réduire le décalage entre les caractères. Cela signifiait qu'il fallait environ 5,5 uSec pour envoyer chaque caractère et 5,5 uSec pour en recevoir un en retour. L'Arduino aurait besoin d'écrire 8 bits, à 500 kHz, il aurait donc besoin d'un nouvel octet toutes les 16 uSec. Il devrait donc y avoir du temps, en supposant que la boucle de code est suffisamment serrée et que le système d'exploitation ne retarde pas trop l'envoi et la réception.
Ce fut un échec complet et total. L'ensemble du cycle de lecture/écriture a pris beaucoup trop de temps, bien au-delà d'une révolution du disque. Le côté Arduino était probablement assez rapide, mais le système d'exploitation n'était pas assez réactif. La lecture des disques fonctionne parce que le système d'exploitation (Windows dans mon cas) mettrait en mémoire tampon les données entrantes, mais en écriture, Windows les enverrait simplement en une seule fois, mais parce que le débit auquel j'envoie est beaucoup plus rapide que l'Arduino n'en a besoin, les données seraient perdues. C'est pourquoi j'ai opté pour ce processus de reconnaissance bidirectionnelle.
Écriture de données - Tentative 2
Le contrôle du flux logiciel pour cette application n'était tout simplement pas assez rapide. J'ai décidé d'enquêter sur le contrôle de flux matériel. J'ai remarqué sur la carte de dérivation FTDI qu'il y a des broches CTS et DTR. Ceux-ci signifient Clear To Send et Terminal de données prêt . J'ai remarqué que pendant que la carte de dérivation était connectée, la carte Arduino connectait le CTS à GND.

Je ne savais pas non plus dans quelle direction se trouvaient ces broches, mais après quelques expérimentations, j'ai découvert que la broche CTS pouvait être signalée par l'Arduino et utilisée par le PC pour contrôler le flux. Normalement, cela se fait à l'aide d'un tampon circulaire, mais dans mon cas, je ne pouvais pas l'autoriser.

Cela signifiait maintenant que je pouvais simplement demander au système d'exploitation d'envoyer les octets en bloc en un seul bloc, et espérer que tout était géré au niveau du noyau afin qu'il ne soit pas interrompu.
J'avais une boucle interne qui produisait chaque bit à partir des 8 bits, mais j'ai décidé qu'il était probablement préférable de le décomposer en 8 ensembles de commandes à la place.
Cela n'a pas fonctionné. Si j'autorisais le code à s'exécuter sans réellement exécuter la partie d'écriture du disque, alors tous les octets ont été reçus correctement, mais avec l'exécution du code, cela n'a pas été le cas et les octets reçus ont été perdus.
Je soupçonnais que changer l'état de la ligne CTX n'arrêtait pas instantanément le flux de données et que l'ordinateur pouvait toujours envoyer un caractère ou deux. Peut-être qu'au moment où j'avais signalé la ligne CTX, elle était déjà en train d'envoyer le caractère suivant.
Écriture de données - Tentative 3
Je ne voulais pas d'interruption série car je ne voulais pas que les horaires d'écriture soient déformés. J'ai réalisé qu'entre l'écriture de chaque bit sur le lecteur de disquette, il y aurait un certain nombre de cycles CPU dans la boucle while suivante. J'ai décidé de vérifier entre chaque écriture de bit si un autre octet avait été reçu depuis que CTX est devenu haut et de le stocker.
Ma théorie était que lorsque vous avez augmenté le CTX, l'ordinateur était probablement déjà en train de transmettre l'octet suivant et comme vous ne pouvez pas l'arrêter à mi-chemin, il le ferait à moitié après celui-ci. Cela signifie que je n'ai besoin de vérifier qu'un octet supplémentaire pendant la boucle et de l'utiliser s'il est trouvé au lieu de regarder à nouveau le port série.
Cela a donc semblé fonctionner et l'Arduino a terminé l'écriture sans perdre aucune donnée de l'ordinateur. Les seules questions étaient maintenant :a-t-il réellement écrit des données, et si oui, certaines d'entre elles sont-elles valides ?
À ce stade, je n'avais encodé qu'une seule piste, j'ai donc décidé d'exécuter l'intégralité de l'algorithme pour encoder les 80 pistes. Quelque chose d'étrange se passait. La tête d'entraînement ne bougeait pas du tout. C'était toujours le cas lors de la lecture, mais pas lors de l'écriture.
J'ai découvert que pour déplacer la tête d'entraînement d'avant en arrière, vous deviez d'abord soulever la broche / WRITE GATE, je pensais que cela était également nécessaire pour changer la surface. Une fois que j'ai ajouté le code pour ce faire, la tête d'entraînement s'est déplacée comme prévu. Cela avait du sens et empêcherait l'écriture accidentelle de pistes tout en déplaçant la tête.
Donc, à ce stade, j'ai écrit une image disque que j'avais créée précédemment, puis j'ai essayé de la relire. Rien n'a pu être détecté ! Soit les données que j'avais écrites étaient invalides, soit la façon dont je les écrivais était fausse.
J'ai décidé d'alimenter les données de secteur MFM encodées que je créais dans mon algorithme de décodage de secteur utilisé par le lecteur pour valider que ce que je générais était correct et valide, et c'était le cas. Quelque chose n'allait manifestement pas avec la façon dont j'écrivais les données sur le disque.
Écriture de données - Tentative 4
Comme aucune donnée n'était lue correctement, j'ai décidé d'essayer différentes approches. Je ne savais pas si la broche /WRITE DATA devait être pulsée (et si oui, de combien de temps), basculée ou simplement définie sur la valeur des données brutes. Ma mise en œuvre actuelle a pulsé la broche. Je n'avais pas pu trouver d'informations en ligne sur la façon dont la broche d'écriture était supposée être physiquement manipulée lors de l'écriture.
La tête de lecture nous enverrait une impulsion à chaque inversion de flux. J'ai décidé de modifier l'implémentation afin que WRITE DATA soit simplement défini sur la valeur du bit. Cela n'a pas fonctionné non plus. J'ai donc changé le code pour basculer l'état actuel de la broche. Toujours pas de chance.
Il est clair que l'une de ces approches doit avoir été la bonne. J'ai donc décidé de sortir à nouveau le fidèle oscilloscope pour voir ce qui se passait. J'ai décidé d'écrire le modèle MFM 0xAA sur chaque octet d'une piste en continu. 0xAA en binaire est B10110110, donc cela me donnerait une onde carrée parfaite que je pourrais surveiller pour la fréquence requise.
S'il ne voyait pas une onde carrée parfaite à la fréquence souhaitée, alors je savais qu'il devait y avoir une sorte de problème de synchronisation.
J'ai branché la lunette, mais j'ai été surpris de voir les minutages étaient parfait. Cependant, étant un ancien oscilloscope, je ne pouvais pas voir plus que quelques impulsions. La lunette avait ce merveilleux mode "mag" x10. Lorsqu'il est enfoncé, il augmente la base de temps de 10, mais plus important encore, vous permet de faire défiler toutes les données un peu comme sur un oscilloscope numérique moderne.
Quelque chose n'allait pas ici. Cela ressemblait à tous les 12 bits environ, je me suis retrouvé avec une période de seulement "élevée" .
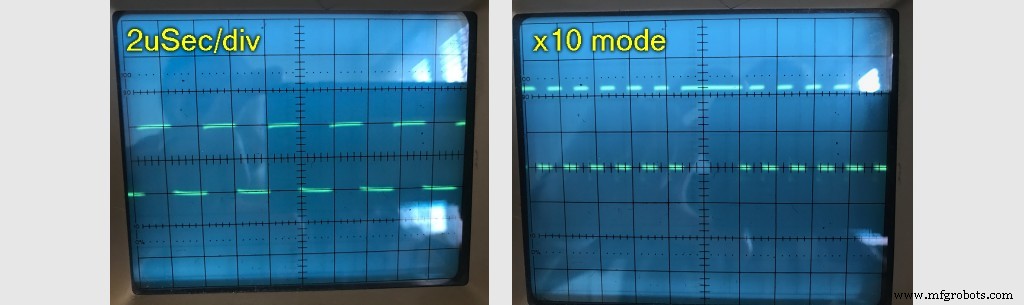
Soit les données que j'envoyais étaient invalides, soit quelque chose causait une pause dans le processus d'écriture tous les 12 bits environ. 12 étant un nombre étrange étant donné qu'il n'y a que 8 bits dans un octet.
Après avoir réfléchi à cela, je me suis demandé si j'étais de retour avec un problème de contrôle de flux. La façon dont j'avais conçu la boucle consistait à récupérer tous les octets supplémentaires parasites reçus après en avoir attendu un. Mais ce n'était pas assez intelligent pour empêcher l'attente tous les deux octets. J'avais deux choix, déplacer quelque chose dans une interruption ou patcher la boucle.
J'ai décidé d'essayer de corriger le fonctionnement de la boucle en premier. Le problème résultait d'un retard causé par l'attente du prochain octet de l'ordinateur. Si nous réduisions le CTX et attendions un octet, au moment où nous augmentions à nouveau le CTX, un autre octet était déjà en route.
Je modifie la boucle de sorte que lorsque le deuxième octet reçu a été utilisé, l'Arduino tire momentanément le CTS vers le bas puis vers le haut pour permettre l'envoi d'un autre caractère. Cela signifiait que lors de la prochaine boucle, nous aurions déjà reçu le prochain octet, donc aucune attente n'était requise.
Le test a produit une onde carrée parfaite :
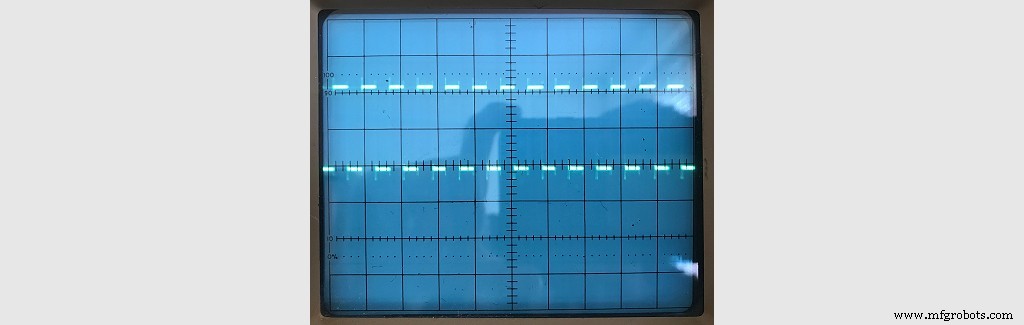
Cela signifiait que tout le timing pour écrire une piste était parfait, c'était juste pour le réel données qui étaient en cours d'écriture. J'ai décidé de laisser cela fonctionner pendant quelques pistes et côtés, puis de le relire pour voir s'il avait été écrit correctement. Je réglais la broche /WRITE_DATA sur la valeur de bit correspondante à partir des données reçues.
Lors de la lecture des données, il semblait que rien n'avait été encodé, mais j'ai ensuite sauté de l'autre côté du disque. Effectivement, il y avait mon modèle. Je ne savais pas pourquoi il n'avait écrit que sur une seule face du disque.
Après quelques réflexions, j'ai commencé à me demander si la broche /WRITE GATE ne fonctionnait pas comme je le pensais. Il s'est avéré qu'en tirant la broche vers le bas, cela pouvait activer la tête d'effacement sur le lecteur. Si tel était le cas, je ne devrais le faire que lorsque j'écrivais réellement, sinon je pourrais me retrouver avec du bruit sur le disque lorsqu'il tourne et s'efface.
J'ai modifié tout le code pour que /WRITE GATE ne soit utilisé que lors du premier démarrage du lecteur, et plus tard uniquement pendant la boucle d'écriture. Ça a marché! J'écrivais maintenant des données sur les deux côtés du disque !
J'ai donc réessayé avec une vraie image disque ADF et je l'ai laissé se terminer. J'ai ensuite utilisé la partie lecteur pour voir si je pouvais le relire. Ça a marché! Mais pour une raison quelconque, il a fallu un certain temps pour relire ce disque. Je n'obtenais aucune erreur MFM, mais j'avais du mal à trouver tous les secteurs.
Il y avait deux possibilités pour moi d'examiner maintenant :premièrement, les données avaient-elles été écrites suffisamment à temps ? et deuxièmement, le disque fonctionnerait-il réellement dans un vrai Amiga ?
Trop excité à l'idée que j'ai peut-être écrit un disque, j'ai démarré le fonctionne maintenant A500+ et insérez le disque. Quelques instants plus tard, le disque a démarré et a affiché le fameux message d'erreur de somme de contrôle. Alors j'écrivais quelque chose valide, mais ce n'était pas cohérent.
J'ai décidé qu'à moins de pouvoir relire les données à un rythme beaucoup plus précis, l'écriture d'un disque était inutile.
Lecture des données (à nouveau)
Je voulais améliorer la qualité de lecture car je n'étais pas satisfait de la mise en œuvre actuelle. La mise en œuvre actuelle ne permettait pas une flexibilité suffisante pour que les impulsions arrivent à des moments légèrement impairs. J'avais besoin d'une nouvelle approche.
Tout d'abord, j'ai décidé que j'allais synchroniser la lecture avec l'impulsion /INDEX. Ce n'est pas requis par l'Amiga mais peut m'être utile plus tard pour tester, écrire et lire.
Plusieurs personnes dans les commentaires sur la première moitié de ce projet ont suggéré que je devrais enregistrer le temps entre les impulsions plutôt que la méthode que j'avais mise en œuvre. Le seul problème avec cela était d'obtenir ces données sur le PC assez rapidement. Si je devais envoyer un octet pour chaque bit, je pourrais facilement dépasser le maximum de 2 M bauds.
J'ai décidé que la meilleure chose à faire serait d'essayer de comprendre un peu les données. J'ai donc décidé de laisser le compteur que j'utilisais à l'origine tourner librement, jusqu'à 255. J'ai ensuite mis le code dans une boucle en attendant une impulsion et que ce point voyait combien de temps s'était écoulé.
Dans une situation idéale, la valeur minimale la plus basse possible serait de 32 (correspondant à 2 uSec). Avec MFM, vous ne pouvez avoir qu'un maximum de trois 0 d'affilée, donc le maximum que cette valeur devrait atteindre était de 128. Cela signifiait qu'il y avait un maximum de 4 combinaisons possibles d'affilée.
J'ai échantillonné plusieurs disques pour voir où se trouvent la majorité de ces fréquences, et les résultats peuvent être vus ci-dessous :

En regardant cela, je trouve la majorité des points autour d'un compteur de 52, 89 et 120. Cependant, ceux-ci étaient quelque peu spécifiques à mon entraînement et n'étaient donc pas une bonne ligne directrice. Après quelques expérimentations, j'ai utilisé la formule suivante :value =(COUNTER - 16) / 32 . Lorsqu'il est écrêté entre 0 et 3, cela m'a donné la sortie dont j'avais besoin. Tous les 4 d'entre eux et je pourrais écrire un octet.
Il m'est venu à l'esprit que parce que vous ne pouviez pas avoir deux '1' ensemble dans un flux binaire codé MFM, je pouvais supposer en toute sécurité que n'importe quoi pour la première valeur n'était pas valide et pouvait être traité comme une autre séquence '01'. La partie suivante consistait à déballer ces données une fois reçues par le PC et à les retransformer en données MFM. C'était simple, puisque 00 ne pouvait pas arriver, un 01 signifiait écrire « 01 », un 10 signifiait écrire « 001 » et un 11 signifiait écrire « 0001 ». J'ai essayé et, à ma grande surprise, mes résultats ont été 100% réussis. J'ai aussi essayé avec quelques disques de plus, à 100 % ! J'avais maintenant un lecteur de disque très fiable.
Cette nouvelle approche étant beaucoup plus tolérante sur les données du disque, je n'avais plus besoin d'analyse de phase ni d'autant de tentatives. La plupart de mes disques lisent maintenant parfaitement. Certains ont nécessité quelques tentatives mais y sont finalement parvenus. La dernière partie consistait à analyser statistiquement les données et à voir si elles pouvaient être réparées. Cependant, 99% du temps, les mauvaises données entrantes étaient complètement méconnaissables et n'étaient donc guère utiles.
Écriture de données - Tentative 5
Maintenant que je pouvais vérifier ce que j'avais écrit avec une grande précision, cela signifiait que tester l'écrivain serait beaucoup plus facile.
Je me suis mis à analyser le code pour voir ce qui n'allait pas. J'ai écrit une séquence 0x55 sur une piste entière, puis je l'ai relue. De temps en temps, les données revenaient un peu, ce qui signifiait qu'il y avait une sorte de problème de synchronisation dans l'écriture.
Il s'est avéré que cela était dû en partie à la façon dont je gérais le port série et en partie à l'utilisation de la minuterie. J'attendais que la minuterie atteigne la valeur 32, écrivais le bit, puis le réinitialisant. Je l'ai changé pour ne pas avoir à modifier la valeur du compteur de minuterie.
J'écrirais le premier bit lorsque le compteur atteignait 16, puis le suivant lorsqu'il atteignait 48 (16+32), et le suivant lorsqu'il atteignait 80 (16+32+32) et ainsi de suite. Timer2 n'étant que de 8 bits revient à zéro après le 8ème bit, exactement au moment où nous en avions besoin. Cela signifiait que tant que nous écrivions le bit à la valeur de minuterie requise, nous serions à exactement 500 kbps.
J'ai également regardé comment je lisais les données du port série. Cela était lu entre chaque bit, mais cela devait aussi être aussi court que possible. Après un peu d'expérimentation, j'ai obtenu le bloc de travail le plus court.
Après avoir modifié le code Windows pour prendre en charge la vérification, j'étais maintenant prêt à réessayer. Cette fois, je savais que si le disque était correctement vérifié, alors il devrait fonctionner correctement dans l'Amiga.
J'ai donc essayé d'écrire un autre disque. Avec vérifier, cela a pris plus de temps. Avec le nouvel algorithme, environ 95% des pistes ont passé la vérification du premier coup, seuls les 5% restants devant être réécrits une fois de plus. J'en étais content et j'ai inséré le disque dans l'Amiga. Cela a parfaitement fonctionné !
Écriture de données - Tentative 6
Après quelques retours de certaines personnes qui l'utilisaient, il était clair que même avec la vérification sur le lecteur, il ne produisait pas toujours des disques entièrement lisibles. Le logiciel pourrait les lire parfaitement, mais les ordinateurs Amiga rapporteraient quelques erreurs de somme de contrôle ici et là.
J'ai jeté un autre coup d'œil au code, je me suis demandé s'il s'agissait d'un problème de synchronisation et j'ai cherché à voir s'il pouvait être piloté par interruption, mais malheureusement, avec le peu de temps entre chaque bit, il n'y a tout simplement pas assez de temps avec des interruptions pour y parvenir en préservant les registres que vous modifiez etc.
J'ai ensuite revu le code d'écriture. Il y a une petite chance qu'après l'écriture d'un octet complet, le code ait pu revenir en arrière pour commencer à écrire l'octet suivant avant que le temporisateur ne revienne à 0, permettant au premier bit d'être écrit plus tôt.
J'ai ajouté une petite boucle pour m'assurer que cela ne pourrait pas se produire, ce qui, espérons-le, résoudra le problème pour tous ceux qui rencontrent ce problème.
Écriture de données - Tentative 7
Après avoir reçu de nombreux rapports d'erreurs de somme de contrôle pour les disques écrits, j'ai commencé à enquêter. Je pensais au début que j'allais devoir me mettre à regarder les données MFM du disque mais le problème était en fait beaucoup plus simple
En regardant XCopy Pro pour voir les erreurs de somme de contrôle, il a signalé les codes 4 et 6 signifiant des erreurs de somme de contrôle dans les en-têtes de secteur et les zones de données. Si cela n'avait été que la zone de données, j'aurais supposé que c'était purement quelque chose à voir avec l'écriture des derniers morceaux de la piste, mais ce n'était pas le cas.
J'ai commencé à regarder le code d'écriture et le rembourrage que j'avais autour de chaque piste, en me demandant si j'écrasais le début d'une piste de temps en temps, alors j'ai massivement réduit le rembourrage post-piste de 256 octets à 8. À ma grande surprise, ma vérification puis a renvoyé une tonne d'erreurs.
Cela m'a fait me demander si le problème réel est que je n'écris pas assez de données. J'ai commencé à ajouter une commande d'effacement de piste à l'Arduino qui écrirait le motif 0xAA sur toute la piste, puis écrirait ma piste par la suite. À ma grande surprise, XCopy l'a approuvé à 100%. J'espère donc que cela a résolu ce problème.
Diagnostic
J'ai eu beaucoup de retours de personnes qui ont réalisé ce projet avec succès, à la fois pleinement fonctionnels et non fonctionnels. J'ai décidé de créer un module de diagnostic dans le code pour aider tous ceux qui ne peuvent pas faire fonctionner le leur.
L'option de diagnostic se compose de quelques commandes supplémentaires à traiter par l'Arduino, ainsi que de toute une série d'événements qui sont exécutés pour s'assurer que tout est correctement câblé.
Et ensuite ?
L'ensemble du projet est gratuit et open source sous GNU General Public License V3. Si nous voulons avoir le moindre espoir de préserver l'Amiga, alors nous ne devrions pas nous arnaquer pour ce privilège. Et en plus, je veux redonner à la meilleure plateforme sur laquelle j'ai jamais travaillé. J'espère également que les gens développeront cela, iront plus loin et continueront à partager.
La solution d'écriture actuelle n'est pas une option sur l'Arduino UNO à moins que vous n'utilisiez une carte de dérivation FTDI/série séparée, donc mes prochaines tâches sont de la faire fonctionner (éventuellement en utilisant le 23K256 IC pour mettre la piste en mémoire tampon avant de l'écrire sur disque).
Je veux toujours regarder d'autres formats. Les fichiers ADF sont bons, mais ils ne fonctionnent que pour les disques formatés AmigaDOS. Il existe de nombreux titres avec une protection contre la copie personnalisée et des formats de secteur non standard qui ne peuvent tout simplement pas être pris en charge par ce format. J'ai reçu des informations très utiles à ce sujet mais je n'ai actuellement pas beaucoup de disques avec lesquels tester.
Selon Wikipedia, il existe un autre format de fichier de disque, le format FDI. Un format universel, c'est bien documenté. L'avantage de ce format est qu'il essaie de stocker les données de la piste aussi près que possible de l'original, ce qui, espérons-le, résoudra les problèmes ci-dessus !
Je suis également tombé sur la Software Preservation Society, en particulier CAPS (anciennement la Classic Amiga Preservation Society ) et leur format IPF. Après un peu de lecture, j'ai été très déçu; tout est fermé, et j'avais l'impression qu'ils utilisaient simplement ce format pour vendre leur matériel de lecture de disque.
Je me concentrerai donc sur le format FDI. Ma seule préoccupation ici concerne l'intégrité des données. Il n'y aura pas de sommes de contrôle contre lesquelles vérifier si la lecture était valide, mais j'ai quelques idées pour résoudre ce problème !
Code
Source de l'esquisse et de l'application Windows
Arduino Sketch et exemple de code source de l'application Windowshttps://github.com/RobSmithDev/ArduinoFloppyDiskReaderSchémas
Circuit pour Arduino Pro Mini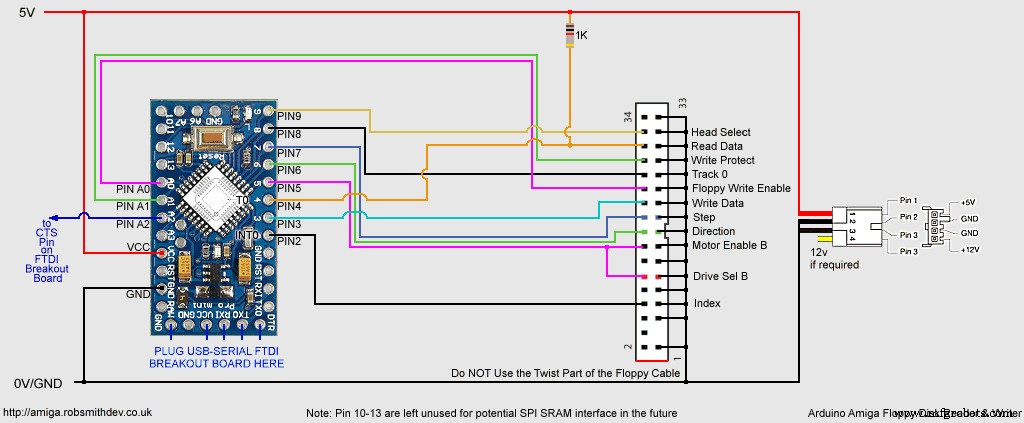 Circuit pour Arduino UNO
Circuit pour Arduino UNO 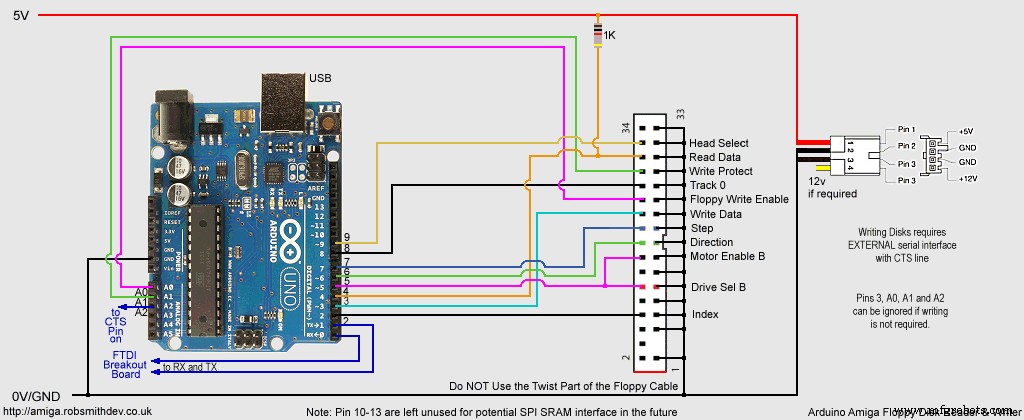
Processus de fabrication