


Créer des applications IoT efficaces avec tinyML et le machine learning automatisé
L'IoT permet une surveillance continue des environnements et des machines à l'aide de minuscules capteurs. Les progrès des technologies de capteurs, des microcontrôleurs et des protocoles de communication ont rendu possible la production en série de plates-formes IoT, avec de nombreuses options de connectivité, à des prix abordables. En raison du faible coût du matériel IoT, les capteurs sont déployés à grande échelle dans les lieux publics, les résidences et sur les machines.
Ces capteurs surveillent les propriétés physiques associées à leurs environnements de déploiement, 24h/24 et 7j/7, et génèrent une énorme quantité de données. Par exemple, les accéléromètres et les gyroscopes déployés sur une machine tournante enregistrent en permanence les modèles de vibration et la vitesse angulaire du rotor attaché à l'arbre. Des capteurs de qualité de l'air surveillent en permanence les polluants gazeux dans l'air, à l'intérieur ou à l'extérieur. Les microphones d'un babyphone sont toujours à l'écoute. Les capteurs à l'intérieur des montres intelligentes mesurent en permanence les paramètres de santé vitaux. De même, divers autres capteurs comme le magnétomètre, la pression, la température, l'humidité, la lumière ambiante, etc., mesurent les conditions physiques partout où ils sont déployés.
Les algorithmes d'apprentissage automatique (ML) permettent de découvrir des modèles intéressants dans ces données, qui dépassent la compréhension de l'analyse et de l'inspection manuelles. La convergence des appareils IoT et des algorithmes ML permet une large gamme d'applications intelligentes et des expériences utilisateur améliorées, rendues possibles par une inférence d'apprentissage automatique à faible consommation, faible latence et légère, c'est-à-dire tinyML. De nombreux secteurs industriels sont en train d'être révolutionnés par cette convergence, comme le montre la figure 1, y compris, mais sans s'y limiter, les technologies portables, la maison intelligente, les usines intelligentes (Industrie 4.0), l'automobile, la vision industrielle et d'autres appareils électroniques grand public intelligents.
tinyML avec apprentissage automatique automatisé
Les algorithmes de ML déployés sur de minuscules microcontrôleurs (MCU) dans les appareils IoT sont particulièrement intéressants en raison de multiples avantages :
- Confidentialité et sécurité des données :l'inférence ML se produit sur les microcontrôleurs intégrés locaux, au lieu d'avoir à transmettre des flux de données au cloud pour traitement. Les données restent sur l'appareil et sur site, où elles sont privées et sécurisées.
- Économies d'énergie :les algorithmes tinyML consomment beaucoup moins d'énergie en raison de la faible ou de l'absence de transmission de données.
- Faible latence et haute disponibilité :étant donné que l'inférence est effectuée localement, la latence est de l'ordre de quelques millisecondes et n'est pas soumise à la latence et à la disponibilité du réseau.
cliquez pour l'image en taille réelle

Figure 1 :tinyML ajoute des fonctionnalités avancées aux appareils IoT traditionnels (Source :Qeexo)
L'apprentissage automatique automatisé à l'aide de données de capteurs implique les étapes décrites dans la figure 2. La configuration des capteurs et la collecte de données de qualité pour l'application ML cible sont terminées avant ces étapes. Une plate-forme d'apprentissage automatique automatisée telle que Qeexo AutoML gère l'ensemble du flux de travail pour la création de modèles d'apprentissage automatique légers et hautes performances pour les MCU de classe Arm Cortex-M0 à M4 et d'autres environnements contraints.
cliquez pour l'image en taille réelle
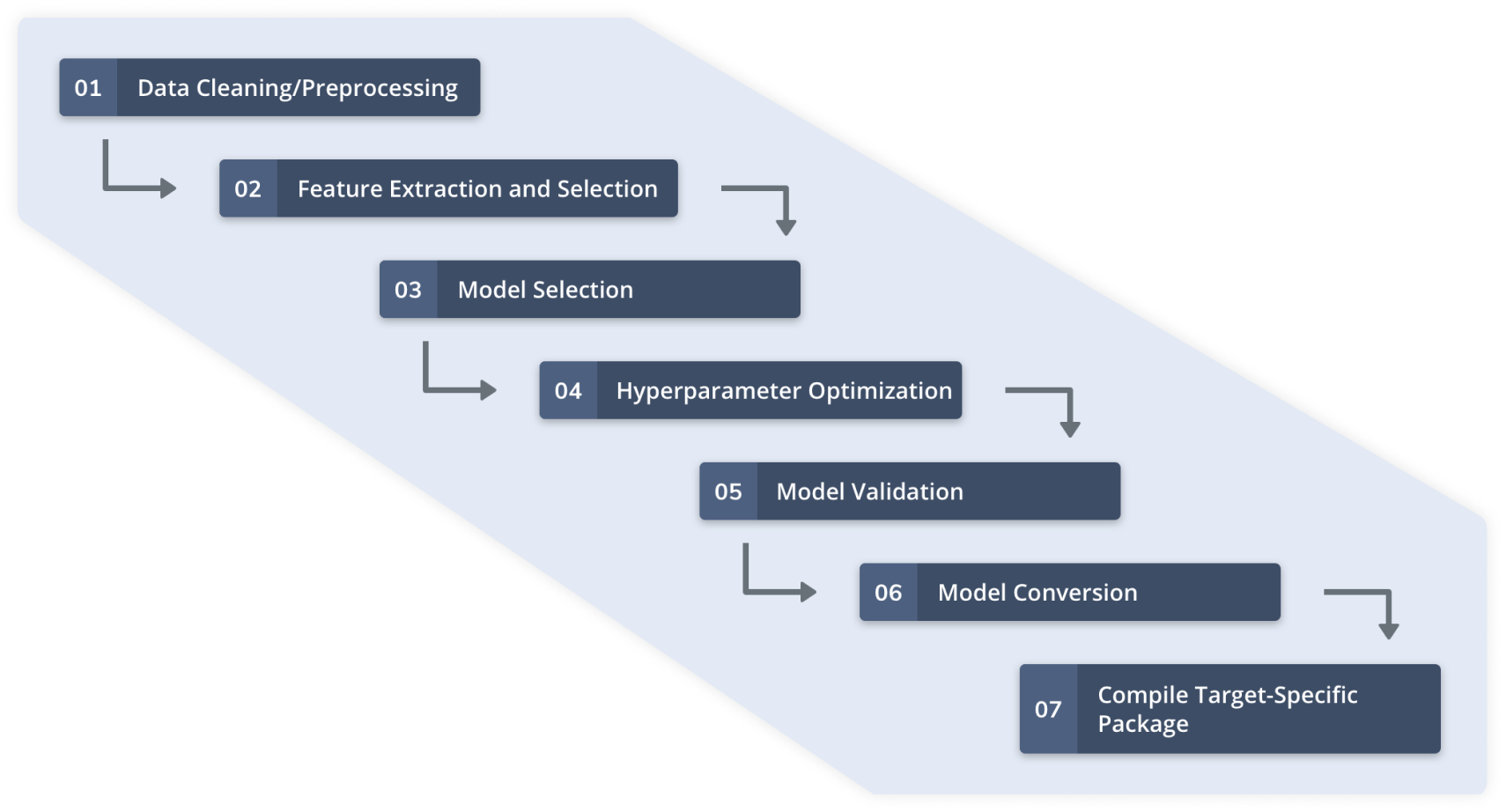
Figure 2 : Flux de travail Qeexo AutoML (Source :Qeexo)
tinyML avec l'architecture ARM® Cortex™ M0+
La prolifération des technologies IoT et les exigences de déploiement à grande échelle des capteurs repoussent encore plus les limites des architectures de microcontrôleurs et du calcul d'apprentissage automatique. Par exemple, les microcontrôleurs Arm Cortex M0+ fonctionnant à 48 MHz sont largement utilisés sur les cartes de capteurs conçues pour les applications IoT en raison de leur faible consommation d'énergie. Il ne consomme que 7 mA par broche d'E/S par rapport à la version Cortex M4 qui fonctionne à 64 MHz et consomme 15 mA.
La faible consommation d'énergie des MCU Cortex-M0+ se fait au prix d'une mémoire et d'un profil de calcul réduits. Les MCU M0+ ne peuvent effectuer que des opérations mathématiques à virgule fixe 32 bits, ne prennent pas en charge l'arithmétique de saturation et n'ont pas les capacités DSP. Basé sur ce MCU, l'Arduino Nano 33 IoT, l'une des plates-formes IoT les plus populaires, est livré avec seulement 256 Ko de flash et 32 Ko de SRAM. En revanche, un module de capteur populaire avec architecture Cortex M4, l'Arduino Nano 33 BLE Sense peut effectuer des opérations à virgule flottante 32 bits, prend en charge le DSP et l'arithmétique de saturation, ainsi que quatre fois le flash et huit fois la SRAM.
Le déploiement d'algorithmes d'apprentissage automatique sur le M0+ est de loin plus difficile que le déploiement sur un M4 en raison de ces trois principaux défis :
- Calcul à virgule fixe : L'apprentissage automatique typique avec les données de capteurs implique le traitement du signal numérique, l'extraction de caractéristiques et l'exécution d'inférences. L'extraction de caractéristiques statistiques et basées sur la fréquence (par exemple, l'analyse FFT) à partir des signaux des capteurs est cruciale pour le développement de modèles d'apprentissage automatique hautement performants. Les flux de données de capteurs représentant des phénomènes physiques réels sont de nature non stationnaire. De manière générale, meilleures sont les informations extraites des signaux de capteurs non stationnaires, meilleures sont les opportunités de développement de modèles ML à hautes performances. Effectuer des opérations mathématiques dans une représentation à virgule fixe tout en maintenant une précision et des performances de qualité commerciale est un défi. Le pipeline d'apprentissage automatique à virgule fixe commence par la représentation des données des capteurs et s'étend jusqu'à l'inférence du modèle pour générer des sorties de classification/régression.
- Faible capacité de mémoire : 256 Ko de mémoire flash et 32 Ko de SRAM imposent des restrictions strictes sur la taille des modèles d'apprentissage automatique et la mémoire d'exécution que ces modèles peuvent utiliser pendant l'exécution. Les problèmes d'apprentissage automatique du monde réel ont souvent des limites de décision/classification compliquées représentées par des modèles d'apprentissage automatique avec un grand nombre de paramètres. Pour les modèles d'ensemble basés sur des arbres, la résolution de problèmes aussi complexes peut entraîner des arbres profonds et un grand nombre de boosters, affectant à la fois la taille du modèle et la mémoire d'exécution. La réduction de la taille du modèle se fait souvent au prix d'un sacrifice des performances du modèle, ce qui n'est généralement pas le critère de compromis le plus souhaitable.
- Faible vitesse du processeur : La faible latence a toujours été une mesure clé lors de la sélection d'un modèle pour les déploiements commerciaux. La vitesse d'horloge de 16 MHz que nous sacrifions sur une architecture M0+ à 48 MHz par rapport à l'architecture M4 à 64 MHz fait une grande différence en ce qui concerne les mesures de latence au niveau de la milliseconde.
Cadre AutoML M0+
Développé pour relever ces défis, Qeexo AutoML fournit un pipeline d'apprentissage automatique à virgule fixe, hautement optimisé pour l'architecture Arm Cortex M0+. Ce pipeline comprend la gestion des données de capteur dans le calcul de caractéristiques à virgule fixe et à virgule fixe et l'inférence à virgule fixe pour les algorithmes d'ensemble basés sur des arbres tels que Gradient Boosting Machine (GBM), Random Forest (RF) et eXtreme Gradient Boosting ( algorithmes XGBoost). Qeexo AutoML encode les paramètres du modèle d'ensemble dans des structures de données très efficaces et les combine avec une logique d'interprétation qui se traduit par une inférence extrêmement rapide sur la cible M0+. La figure 3 articule le pipeline d'apprentissage automatique à virgule fixe développé par Qeexo pour la cible embarquée Arm Cortex M0+.
cliquez pour l'image en taille réelle
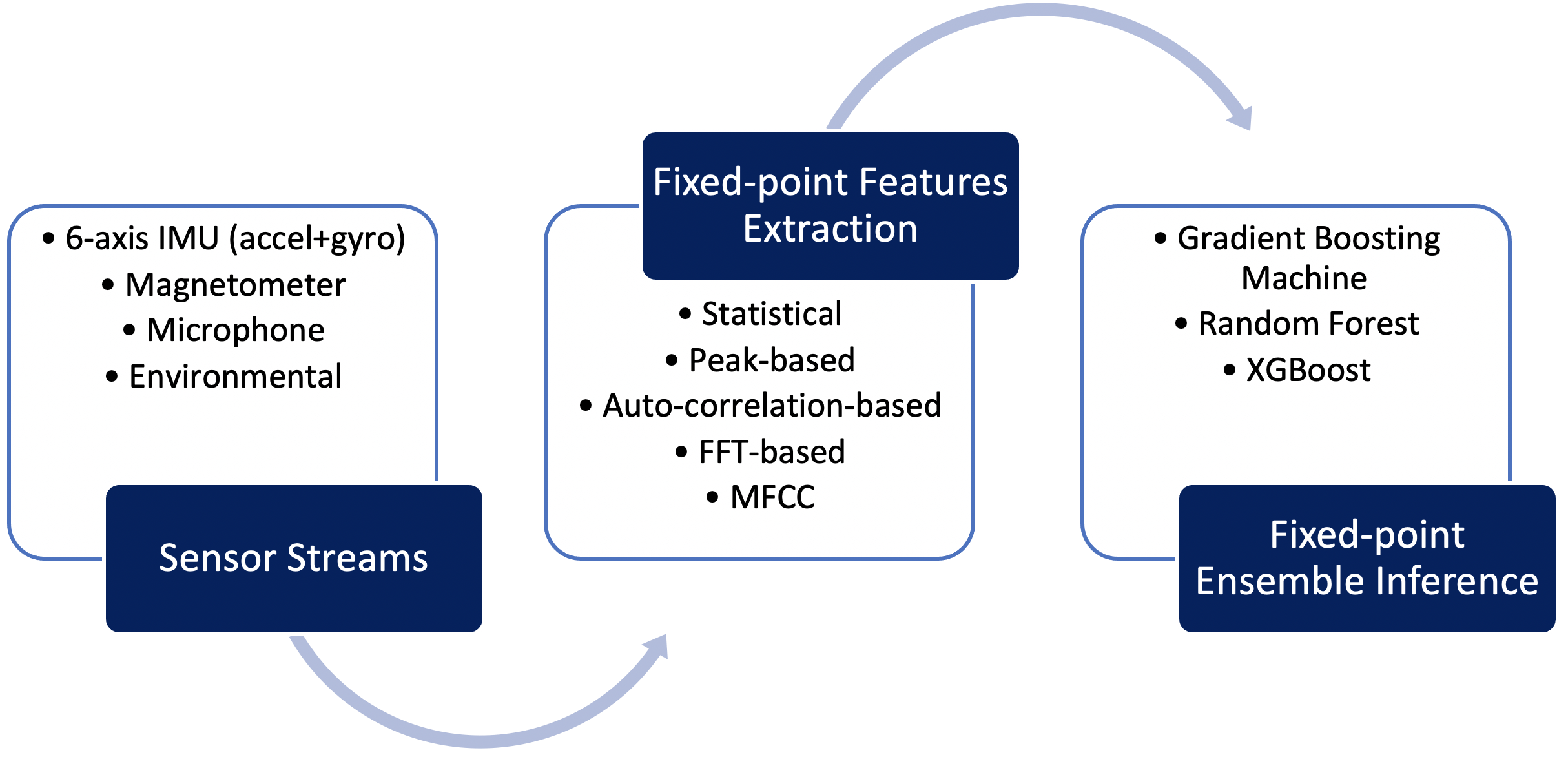
Figure 3 : Pipeline d'inférence Qeexo AutoML M0+ (Source :Qeexo)
Qeexo AutoML effectue une compression et une quantification des modèles en instance de brevet pour réduire davantage l'empreinte mémoire des modèles d'ensemble développés sans compromettre les performances de classification. La figure 4 décrit le processus d'entraînement Qeexo AutoML pour la cible intégrée Cortex M0+.
cliquez pour l'image en taille réelle
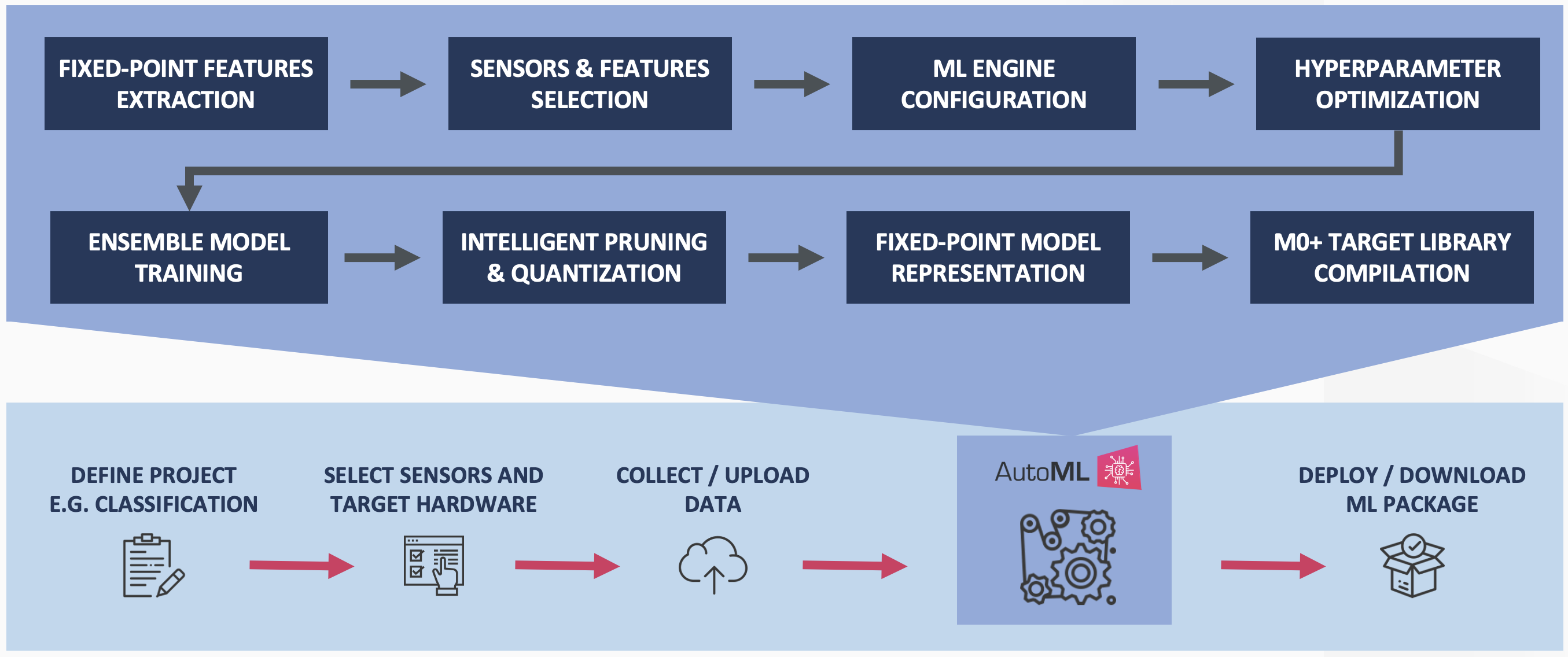
Figure 4 : Pipeline de formation Qeexo AutoML M0+ (Source :Qeexo)
Élagage intelligent
L'élagage intelligent permet la compression des modèles sans perte de performances. En termes simples, Qeexo AutoML crée d'abord un modèle d'ensemble complet tel que recommandé par un optimiseur d'hyperparamètres, puis sélectionne intelligemment uniquement les boosters les plus puissants.
Cette approche consistant à développer un modèle plus grand, puis à l'élaguer intelligemment pour le déploiement cible est beaucoup plus efficace que de créer un modèle plus petit en premier lieu. Un modèle initial plus grand donne la possibilité de sélectionner des boosters (ou arbres) hautes performances qui se traduisent finalement par de meilleures performances du modèle.
Comme le montre la figure 5, le modèle d'ensemble compressé est d'environ 1/10 ème la taille du modèle complet tout en ayant des performances de validation croisée plus élevées. (L'axe X représente le nombre d'arbres (ou booster) dans le modèle d'ensemble et l'axe Y représente les performances de validation croisée.) Notez que notre méthode d'élagage intelligente Qeexo AutoML sélectionne uniquement les 20 boosters les plus puissants, ce qui entraîne une compression de 90 % dans la taille du modèle.
cliquez pour l'image en taille réelle
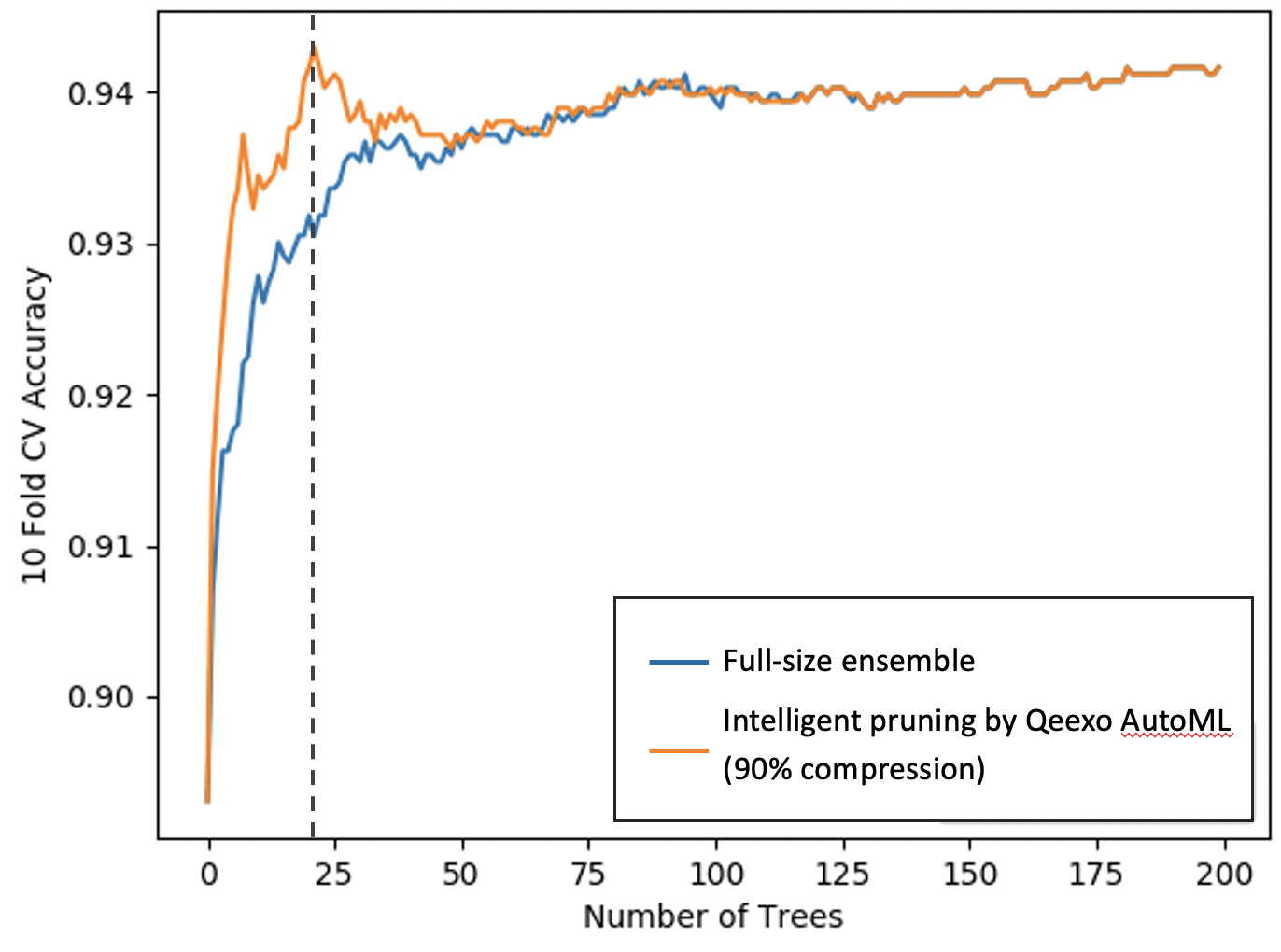
Figure 5 : Élagage intelligent du modèle Qeexo AutoML (Source :Qeexo)
Quantification du modèle d'ensemble
Qeexo AutoML effectue une quantification post-formation des algorithmes d'ensemble. La quantification post-entraînement est une fonctionnalité banalisée pour les modèles basés sur les réseaux de neurones et est prise en charge prête à l'emploi dans des frameworks tels que TensorFlow Lite. Cependant, la quantification des modèles d'ensemble est la technique en instance de brevet de Qeexo qui peut réduire encore plus la taille du modèle tout en améliorant la latence au niveau du MCU avec peu ou pas de dégradation des performances du modèle. Le pipeline Qeexo AutoML M0+ génère des modèles d'ensemble à virgule fixe représentés avec une précision de 32 bits. Des options supplémentaires pour la quantification 16 bits et 8 bits peuvent réduire davantage les modèles de ½ et ¼, respectivement, avec une accélération de 2x à 3x.
Exemples de cas d'utilisation de tinyML
Quelles sont les applications ou les cas d'utilisation de tinyML ? Les possibilités sont illimitées et nous en soulignons ici quelques-unes :
- Nous voulons créer un mur intelligent compatible avec l'IA sur lequel les utilisateurs peuvent appuyer pour contrôler l'éclairage (allumer/éteindre et modifier l'intensité de la lumière). Nous pouvons définir les gestes de la main associés au ON/OFF et au contrôle de l'intensité, puis collecter et étiqueter les données gestuelles à l'aide d'un module accéléromètre et gyroscope fixé au dos du mur. Avec ces données étiquetées, Qeexo AutoML peut utiliser des algorithmes d'IA pour créer un modèle permettant de détecter les gestes « frapper » et « essuyer » sur le mur pour contrôler l'éclairage. Dans la vidéo ci-dessous, vous pouvez voir un prototype de mur intelligent développé par Qeexo AutoML en quelques minutes.
- En utilisant l'apprentissage automatique et l'IoT, nous voulons nous assurer que les envois sont traités avec le plus grand soin conformément aux directives d'expédition. Dans la vidéo ci-dessous, vous pouvez voir comment une boîte d'expédition compatible avec l'IA est capable de détecter comment l'expédition a été traitée de la source à la destination.
- La convergence de l'IA avec l'IoT peut également créer des plans de travail de cuisine intelligents. La vidéo ci-dessous montre des modèles construits par Qeexo AutoML pour détecter divers appareils de cuisine.
- La surveillance des machines est l'un des cas d'utilisation les plus prometteurs de tinyML. Plusieurs modèles de pannes de la machine sont détectés dans la vidéo ci-dessous.
- La détection d'anomalies est un autre scénario qui bénéficie grandement de l'apprentissage automatique. Souvent, il est difficile de collecter des données pour divers défauts dans un environnement industriel, alors qu'il est relativement facile de surveiller l'état de fonctionnement sain de la machine. En observant simplement l'état de fonctionnement sain, les algorithmes Qeexo AutoML peuvent développer des systèmes d'IA pour la détection d'anomalies, comme indiqué dans la partie 1 (ci-dessous), la partie 2, la partie 3 et la partie 4.
- La reconnaissance d'activité à l'aide de capteurs intégrés dans les appareils portables est un autre cas d'utilisation qui profite à notre vie quotidienne. La vidéo ci-dessous montre comment créer une solution de reconnaissance d'activité à l'aide de Qeexo AutoML en quelques minutes.
Technologie de l'Internet des objets
- Créer des applications hybrides blockchain/cloud avec Ethereum et Google
- La chaîne d'approvisionnement et l'apprentissage automatique
- Émetteurs-récepteurs bidirectionnels 1G pour les fournisseurs de services et les applications IoT
- Capteurs et processeurs convergent pour les applications industrielles
- Créer des robots avec Raspberry Pi et Python
- Conduire la fiabilité et améliorer les résultats de la maintenance avec l'apprentissage automatique
- IoT et éducation :Combler la fracture numérique
- Améliorer la surveillance de la pollution de l'air avec des capteurs IoT
- IdO industriel et les blocs de construction pour l'industrie 4.0