


L'architecture hybride accélère les charges de travail d'IA et de vision
Un nouveau flux de données hybride et l'architecture Von Neumann peuvent accélérer les charges de travail, notamment réseaux de neurones, apprentissage automatique, vision par ordinateur, DSP et sous-programmes d'algèbre linéaire de base.
Quadric, une startup de la Silicon Valley, a construit un accélérateur conçu pour accélérer les charges de travail d'IA et d'algorithmes de vision par ordinateur standard pour les périphériques tels que les robots, l'automatisation d'usine et l'imagerie médicale. L'architecture matérielle de l'entreprise est un nouveau flux de données hybride et une conception Von Neumann qui peut gérer des charges de travail telles que les réseaux de neurones, l'apprentissage automatique, la vision par ordinateur, le DSP et les sous-programmes d'algèbre linéaire de base.
"Dès le début, nous savions très bien que l'IA n'était pas la seule application nécessaire pour l'informatique sur les appareils périphériques", a déclaré le PDG de Quadric, Veerbhan Kheterpal, à EE Times . « Les développeurs de ces produits ont besoin que le système complet soit capable d'exécuter des algorithmes de calcul classiques à hautes performances, ainsi que l'IA. C'est vraiment la configuration requise complète. »
Kheterpal a souligné que l'architecture n'est pas un ensemble d'accélérateurs pour des charges de travail individuelles. Il s'agit plutôt d'une architecture unifiée avec un jeu d'instructions parallèles aux données conçu pour accélérer des charges de travail variées, y compris l'inférence d'IA.
"Là où l'IA évolue ces derniers temps, il existe des tendances intéressantes concernant le remplacement de couches entières par une transformation de Fourier rapide (FFT)", a déclaré Daniel Firu, chef de produit chez Quadric. Quadric se positionne pour accélérer ces types de charges de travail, citant un article récent de Google dans lequel des chercheurs ont accéléré un réseau de transformateurs en remplaçant certaines couches par une FFT. Google a remplacé la sous-couche d'auto-attention d'un encodeur de transformateur par une FFT pour générer un réseau qui a atteint une précision de 92 % sur le benchmark BERT ; l'entraînement était jusqu'à sept fois plus rapide sur les GPU ou deux fois plus rapide sur les Google TPU.

Le kit développeur de Quadric, une carte M.2 avec le processeur Q16 et 4 Go de mémoire externe (Source :Quadric)
Robots vignerons
Les trois co-fondateurs de Quadric, Veerbhan Kheterpal, Daniel Firu et Nigel Drego, ont précédemment fondé 21, une société minière de bitcoins qui a été vendue à Coinbase. Quadric, Burlingame, Californie, n'a pas commencé à concevoir des puces. Au lieu de cela, il a à l'origine construit des robots agricoles qui pouvaient parcourir les vignobles de la Napa Valley en regardant les vignes et en envoyant des alertes lorsqu'il voyait des fuites d'irrigation ou des parasites.

Veerbhan Kheterpal (Source :Quadric)
"Lorsque nous l'avons construit, nous avons réalisé qu'il n'allait pas être un produit viable construit à partir de la chaîne d'approvisionnement des drones entre 5 et 10 000 $", a déclaré Kheterpal. « Il devrait être construit à partir de la chaîne d'approvisionnement des tracteurs pour un coût de 50 000 $, et transporter de gros PC avec des GPU, avec des tonnes de caméras. C'est à ce moment-là que nous avons cherché sous le capot de tous ces logiciels de robotique et découvert ce qui causait fondamentalement l'augmentation de ce besoin d'énergie avec des plates-formes comme Nvidia et Intel. »
L'entreprise s'est tournée vers la construction d'une puce accélératrice - "la puce que nous aurions aimé avoir", selon Firu.
Un cycle de financement d'amorçage a été lancé en 2017, suivi d'un cycle de série A qui a généré 13 millions de dollars auprès de clients potentiels, dont le principal investisseur de Quadric, l'automobile japonaise Tier-One Denso. Le financement total de Quadric est de 18 millions de dollars.
Turing terminé
Quadric utilise une architecture pilotée par instructions qui prend des éléments d'architectures de flux de données et les combine avec des éléments d'une machine Von Neumann. L'objectif est de remplacer les systèmes hétérogènes dans les dispositifs de périphérie par quelque chose de moins complexe. En tant que machines complètes de Turing, les noyaux Quadric Vortex offrent une combinaison d'accélération et de flexibilité, affirme la société. L'architecture est évolutive en termes de matrices de cœurs et portable jusqu'aux nœuds de processus avancés (7 ou 5 nm). Cela convient aux applications d'appareils de pointe avec des budgets de puissance compris entre des centaines de milliwatts et 20 W environ.
La première puce de la société, la Q16, est un réseau de 16 x 16 cœurs Vortex. Chaque cœur a la capacité d'effectuer des multiplications matricielles et des calculs d'IA, mais chacun dispose également d'une ALU multifonctionnelle, pour des opérations telles que ET, OU, réduction, décalage et autres. Le logiciel permet aux développeurs d'exprimer divers types d'algorithmes, y compris les fonctions d'activation LSTM et plus encore. Les instructions If-Then-Else sont disponibles sur l'ensemble du tableau, permettant aux développeurs de tirer parti de la rareté à grain fin.
Chaque cœur de la baie dispose d'un accès à cycle unique à ses cœurs voisins, ainsi que d'un accès à cycle unique à une mémoire interne de 4 Ko. La mémoire sur puce est également incluse à côté de la baie, offrant aux cœurs un accès déterministe à faible latence.
Les cœurs fonctionnent en parallèle de ce que Quadric appelle une manière « une seule instruction, plusieurs décodage » ; chaque noyau reçoit la même instruction à chaque cycle. Mais sur la base des données dynamiques au moment de l'exécution, chaque cœur peut interpréter cette instruction différemment. Cela permet aux cœurs, ou aux groupes de cœurs, d'exécuter des fonctions légèrement différentes.
Un bus de diffusion dédié est également inclus qui optimise la bande passante dans la matrice et peut être utilisé pour diffuser des constantes, telles que des poids de réseau neuronal, dans tous les cœurs à la fois (Firu a déclaré que de nombreux algorithmes de vision par ordinateur ont également des informations invariantes en boucle qui peuvent être mappé sur le bus).
Les informations dynamiques entrent dans la baie via des unités de stockage de charge statiques et contrôlées par logiciel qui permettent des temps d'exécution de noyau déterministes. L'appareil permet le chargement et le stockage simultanés à partir de deux bords quelconques d'un appareil, ainsi qu'une propriété spéciale à partir d'un bord qui peut être utilisée pour envoyer des poids de réseau neuronal - le chargement à partir de deux bords et le stockage à partir d'un troisième bord simultanément peuvent réduire les temps d'exécution de calcul.

Daniel Firu (Source :Quadric)
"Vous pouvez charger sur un côté, puis stocker à partir d'un côté perpendiculaire", a déclaré Firu. « Cela permet à des choses assez intéressantes de se produire au niveau logiciel. Vous pouvez également commencer à faire des choses comme des remappages de données et des rotations d'images et des choses comme ça en utilisant ce paradigme."
Pendant ce temps, les mémoires statiques contrôlées par logiciel (pas le cache) sur puce offrent de l'espace pour les grandes structures de données. Quadric permet un accès API à ceux-ci afin que les développeurs puissent définir des structures de données arbitraires à l'intérieur. Dans la puce Q16, les mémoires sont de 8 Go, suffisamment pour contenir « deux ou trois tampons d'images en HD, ou tout un réseau de neurones de poids », a déclaré Firu.
Pile logicielle
Quadric a construit sa pile logicielle avant le silicium. Les clients l'utilisent avec le simulateur d'architecture de l'entreprise, ou avec des FPGA, depuis un an, a déclaré Kheterpal. La pile de Quadric fait abstraction de l'architecture et du jeu d'instructions via un compilateur basé sur LLVM, avec une API C++ en plus.
Le mode source prend en charge différents algorithmes de données parallèles avec un contrôle C++ au niveau de la source des caractéristiques architecturales du processeur. À mesure que les réseaux de neurones deviennent plus complexes, le mode source permet également aux développeurs d'exprimer des opérations personnalisées.
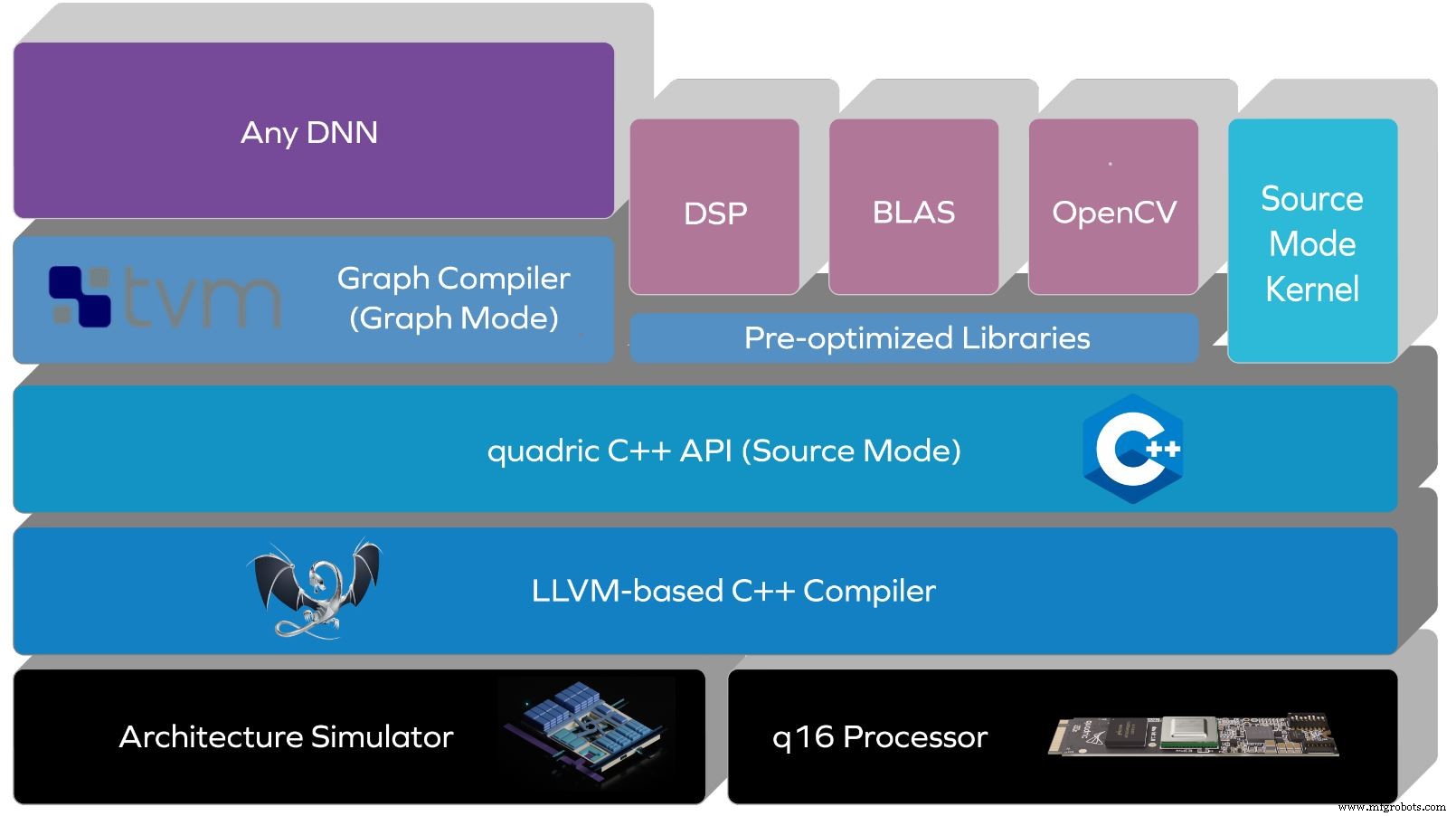
La pile logicielle de Quadric (Source :Quadric)
Une future mise à jour de la pile offrira un mode graphique sans code, qui prendra en charge les versions TensorFlow ou ONNX des réseaux de neurones. Cela inclura un compilateur de réseau de neurones profonds (DNN) basé sur TVM qui génère automatiquement du code.
"Nous combinons la puissance du no-code avec la flexibilité d'avoir votre propre code personnalisé, et les combinons de manière intéressante pour réaliser votre application", a déclaré Kheterpal. « La plupart des plates-formes n'offriront qu'une architecture spécifique à l'IA avec une sorte de compilateur DNN – mais qu'en est-il de la personnalisation ? Qu'en est-il d'un DNN qui n'est pas pris en charge ? Qu'en est-il des opérateurs qui ne sont pas pris en charge ? Nous n'avons pas ces restrictions car il s'agit d'un noyau complet de Turing, les noyaux peuvent effectuer n'importe quelle opération. La flexibilité du code donne aux développeurs la possibilité d'écrire n'importe quel algorithme qu'ils veulent. »
Feuille de route de la puce
La puce Q16 de Quadric, qui comprend 256 cœurs Vortex dans une matrice 16 x 16 en silicium 16 nm, offre 4 INT8 DNN TOPS. Il peut exécuter ResNet-50 à 200 inférences par seconde (pour les paramètres INT8 à une taille d'image de 224 x 224), consommant en moyenne 2 W.
La feuille de route de Quadric comprend une deuxième génération de l'architecture, ainsi qu'une sortie sur bande d'une puce Q32 (un réseau de 1 000 cœurs), "probablement en 7 nm", a déclaré Firu. Alors que le Q16 est strictement un accélérateur (il serait assis à côté d'un processeur hôte système), le Q32 en cours de développement peut également inclure des cœurs Arm ou RISC-V pour agir en tant qu'hôte.
Un kit de développement au format M.2, avec un processeur Q16 et 4 Go de mémoire externe directement mappés sur l'espace mémoire universel du Q16, est désormais disponible.
>> Cet article a été initialement publié sur notre site frère, EE Fois.
Contenus associés :
- Les accélérateurs matériels servent les applications d'IA
- Quand un DSP bat un accélérateur matériel
- Un guide pour accélérer les applications avec des instructions personnalisées RISC-V justes
- Les performances de la puce d'inférence reposent sur une conception optimisée du sous-système de mémoire
- Les nouveaux modules d'accélération de l'IA améliorent les performances de pointe
- Edge AI défie la technologie de la mémoire
Pour plus d'informations sur Embedded, abonnez-vous à la newsletter hebdomadaire d'Embedded.
Embarqué
- Environnements cloud hybrides :un guide des meilleures applications, charges de travail et stratégies
- L'architecture de la puce IA cible le traitement des graphes
- Le MCU sans fil présente une architecture double cœur
- Les processeurs spécialisés accélèrent les charges de travail de l'IA des points de terminaison
- La conception de référence prend en charge les charges de travail d'IA gourmandes en mémoire
- La carte de capteur intelligent accélère le développement de l'IA de pointe
- La caméra intelligente offre une IA de pointe en vision industrielle clé en main
- IBM présente une architecture blockchain hybride pour l'Internet des objets
- Omrons TM Cobot accélère l'intégration et la programmation