


Un guide pour accélérer les applications avec des instructions personnalisées RISC-V justes
L'architecture de jeu d'instructions ouverte (ISA) de RISC-V permet une grande flexibilité de mise en œuvre et offre des fonctionnalités optionnelles qui peuvent permettre de nouvelles approches pour résoudre les compromis de conception matériel-logiciel. Sur la base d'une structure modulaire, un certain nombre d'extensions et d'options standard peuvent être utilisées pour configurer le processeur de base comme point de départ. Pourtant, la vraie valeur réside en fait dans les opportunités que RISC-V offre aux développeurs pour créer de nouvelles extensions, instructions et configurations qui répondent de manière unique aux besoins de leurs idées d'applications innovantes.
Le défi logiciel des ISA fixes
Traditionnellement, les ISA étaient la propriété intellectuelle (IP) d'organisations commerciales qui voulaient soit vendre des microprocesseurs ou des microcontrôleurs, soit qui voulaient concéder sous licence leurs conceptions pour que d'autres puissent les utiliser. Les développeurs embarqués doivent exécuter un logiciel d'analyse comparative pour déterminer quelle solution est la mieux optimisée pour les besoins de leurs applications. En raison du coût de développement d'un ISA indépendant avec tout l'écosystème nécessaire, les fournisseurs de semi-conducteurs s'appuyaient de plus en plus sur les ISA fixes standard proposés par les principaux fournisseurs IP, en s'appuyant sur la loi de Moore et des périphériques intégrés pour offrir une différenciation, telle que l'ultra basse consommation. , à leurs clients.
Le défi ici est que les instructions utilisées pour exécuter le code ne peuvent pas être modifiées. Par conséquent, les gains d'efficacité qui pourraient potentiellement être obtenus par, par exemple, une instruction optimisée pour un algorithme de cryptage, ne peuvent pas être réalisés. Cela peut signifier que l'application du développeur est trop lente, utilise potentiellement trop d'énergie ou manque régulièrement une échéance en temps réel dur dans une boucle de contrôle. Même avec la meilleure volonté du monde, ce sont des facteurs qui sont difficiles à résoudre uniquement avec des améliorations de fabrication de semi-conducteurs ou des rétrécissements de processus.
Le RISC-V ISA a commencé comme un projet à l'Université de Californie, Berkeley et est maintenant maintenu par l'Association internationale RISC-V, un groupe à but non lucratif avec plus de 300 membres. Ceux-ci contribuent aux spécifications ISA, aux outils logiciels, tels que les simulateurs et les compilateurs, et au reste de l'écosystème nécessaire pour prendre en charge une telle entreprise. La pertinence ou non de l'utilisation dépend de la possibilité d'exploiter l'un des deux facteurs suivants :elle est gratuite en termes de licence ou la liberté qu'elle offre.
Étant ouvert et disponible gratuitement, il fournit une plate-forme de traitement de base qui peut facilement être utilisée par les universités pour l'enseignement et la recherche, ainsi que pour des applications commerciales. Un ISA ouvert prend également en charge un certain nombre de modèles commerciaux pour les développeurs qui cherchent à s'approvisionner en propriété intellectuelle pour semi-conducteurs, du fournisseur de propriété intellectuelle commercial aux projets open source et aux conceptions auto-construites propres. Les organisations commerciales trouvent également cela attrayant, en l'utilisant dans des FPGA, des SoC ou même au cœur d'un microcontrôleur ou d'une offre de produits standard.
Grâce à la liberté qu'elle offre, les universités peuvent étudier de nouvelles approches pour relever les défis de calcul, en mettant en œuvre de nouvelles instructions et autres accélérateurs, des conceptions hétérogènes multicœurs et multicœurs ainsi que différentes options de microarchitecture. Bon nombre de ces options sont également attrayantes pour les startups et les entreprises qui cherchent à relever des défis complexes, tels que les chipsets d'intelligence artificielle (IA) à faible consommation qui fonctionnent à la périphérie, en ajoutant des instructions personnalisées adaptées aux exigences de l'application finale.
Comme l'écosystème a été établi avec la flexibilité RISC-V intégrée, toute configuration standard ou extension personnalisée devrait pouvoir tirer parti des outils et logiciels dans le cadre conforme à l'ISA.
Comprendre la flexibilité du RISC-V ISA ouvert
Grâce à l'accessibilité de l'ISA RISC-V et des outils associés, il est simple de lancer un projet d'investigation pour évaluer son adéquation à une utilisation dans une application spécifique. Les outils de simulation permettent d'essayer un ISA de base standard pour déterminer les performances prêtes à l'emploi. Par exemple, un bon point de départ serait une configuration RISC-V 32 bits avec un entier « I » et des extensions « M » multiples (qui peuvent être référencées comme RV32IM) prenant en charge un jeu d'instructions entières de base 32 bits; plus d'options sont disponibles mais cela est suffisant pour cet exemple. Ceci est ensuite instancié avec une mémoire simulée comprenant les délais d'accès et les états d'attente.
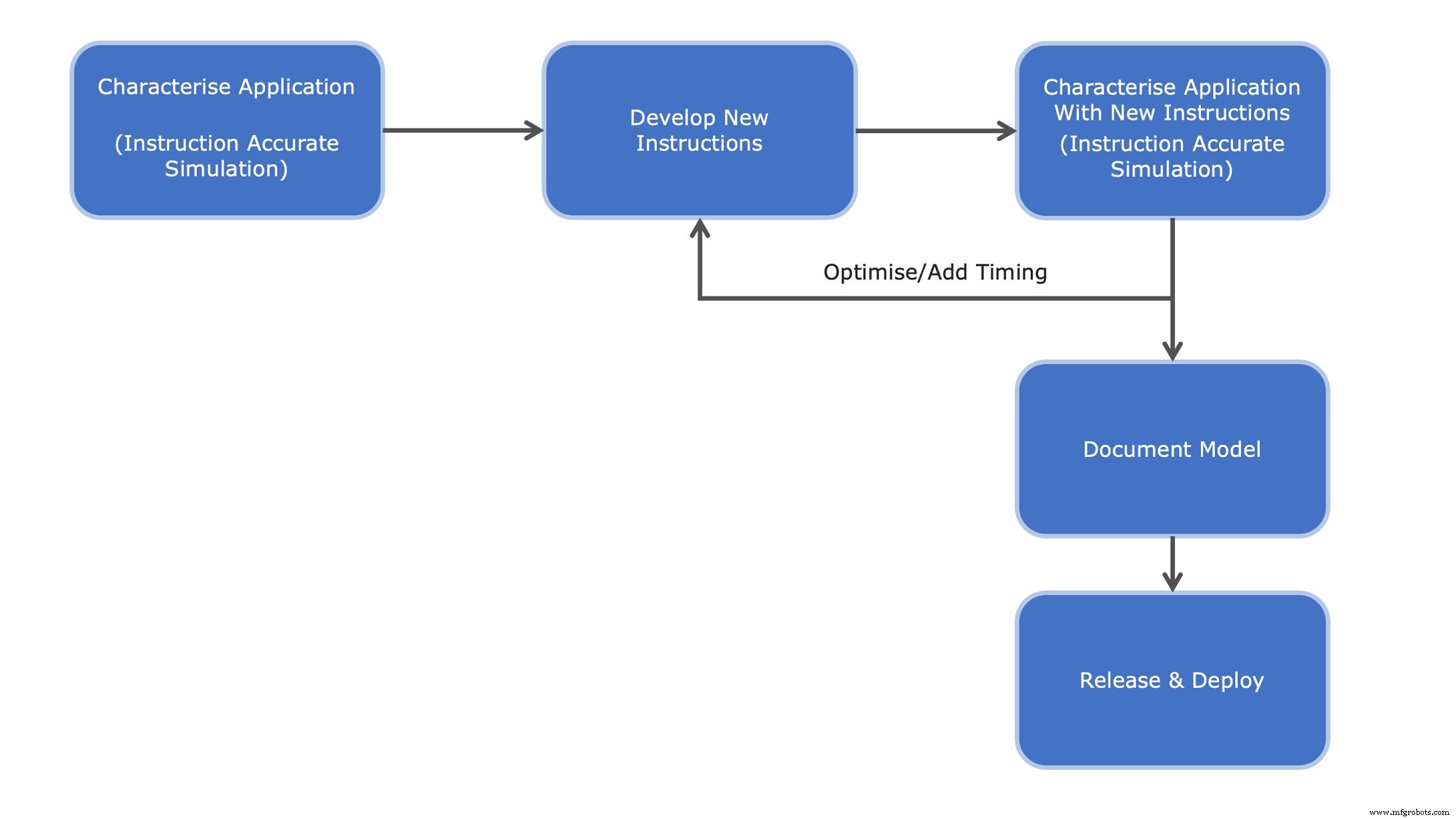
Une application écrite en C/C++ peut ensuite être compilée de manière croisée à l'aide de chaînes d'outils standard. Cela peut fonctionner sur bare metal ou dans le cadre d'un système d'exploitation (en temps réel) (RTOS/OS). Le code binaire résultant est ensuite exécuté à l'aide d'outils tels qu'un simulateur de jeu d'instructions (ISS) qui permet d'intégrer et de simuler le modèle de processeur de base choisi (figure 1). Cet environnement fournit également une fonctionnalité d'entrée/sortie standard et un accès au système de fichiers hôte. Des outils standard d'environnement de développement intégré (IDE) tels qu'Eclipse peuvent ensuite être utilisés pour contrôler l'exécution du code, en s'interfaçant via le débogueur GNU GDB.
À partir de là, grâce à un processus de profilage et d'analyse, les candidats à l'instruction sont identifiés, conçus et modélisés. En utilisant le code d'application d'origine comme modèle fonctionnel de base, l'amélioration résultante peut être rapidement testée, vérifiée et les performances comparées. Cette itération rapide de profilage et d'analyse permet une sélection et une optimisation rapides des instructions qui méritent d'être mises en œuvre. La documentation peut être générée à partir du modèle et constitue la base d'une spécification de fonction pour la conception de la logique de transfert de registre (RTL) et d'un modèle optimisé.
Par exemple, un algorithme de chiffrement tel que ChaCha20 peut être critique pour une application particulière. Le code source disponible peut être compilé pour une base RV32IM « vanille », exécuté, puis analysé avec une estimation du temps de cycle d'instruction en utilisant le profilage de bloc de base pour déterminer combien de temps a été passé dans quelles sections de code. Le cœur de l'algorithme ChaCha20 fait un usage intensif des instructions XOR et de rotation appelées quarts de tour (figure 2). Les résultats du profilage de bloc mettent immédiatement en évidence que la majorité du temps d'exécution est consacrée à ces fonctions.

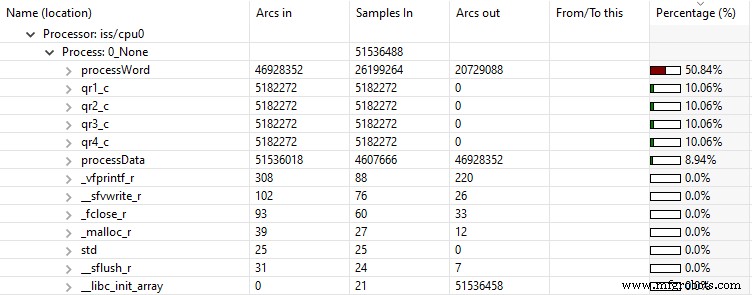
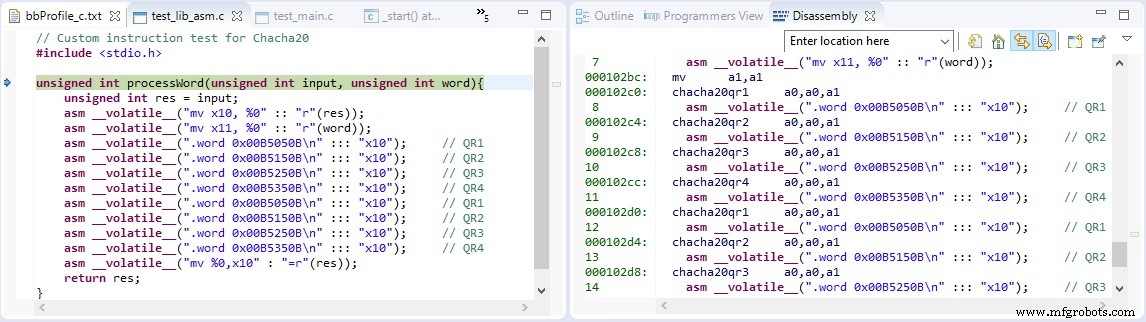
La visualisation graphique de ces hotspots peut également être générée à l'aide d'un outil de vérification, d'analyse et de profilage (VAP). Plutôt que de fournir une sortie textuelle, le temps d'exécution est fourni sous la forme d'un arbre de statistiques réductibles, aidant à mieux visualiser les points chauds avec une proportion élevée d'instructions exécutées. Cela peut être vu dans la figure 3 où la fonction processWord() implémente l'algorithme ChaCha20, en appelant tour à tour les quatre qrx_c fonctions pour mettre en œuvre les fonctions quart de rond requises.
En examinant le code assembleur généré par le compilateur et/ou en exécutant un profilage de bloc de base, il est alors possible de déterminer quelles instructions et combinaisons d'instructions ont été utilisées pour implémenter l'algorithme. À partir de là, la prochaine étape consiste à déterminer quelles instructions personnalisées, dans les limites des spécifications de l'ISA, pourraient potentiellement augmenter la vitesse d'exécution.
Détermination de l'amélioration potentielle que RISC-V pourrait apporter
L'algorithme ChaCha20 fait un usage intensif d'un XOR couplé à une rotation à gauche de 7, 8, 12 et 16 bits. L'utilisation des instructions disponibles de la spécification de base RV32IM montre que cela nécessite une instruction XOR suivie d'une instruction shift-left. Cela signifie qu'il est possible d'optimiser ces deux étapes en quatre instructions dédiées qui implémentent un XOR avec 7, 8, 12 ou 16 bits de rotation à gauche.
Étant une architecture de stockage de chargement, toutes les instructions personnalisées doivent supposer que les données à manipuler résident déjà dans l'un des registres 32 bits de ce RISC-V. Cela détermine immédiatement qu'une instruction de type R (registre) sera nécessaire qui peut être située dans custom-1 espace de décodage (figure 4).
 L'ISA fournit une structure claire pour de telles instructions. En suivant ces règles, nous pouvons déterminer rapidement comment encoder nos nouvelles instructions. Les 7 bits inférieurs sont définis comme l'opcode, qui reçoit une valeur qui la marque comme une instruction personnalisée dans le custom-1 décoder l'espace. Ceci est par opposition au OP ou OP-IMM opcodes utilisés respectivement pour les instructions XOR et shift-left existantes.
L'ISA fournit une structure claire pour de telles instructions. En suivant ces règles, nous pouvons déterminer rapidement comment encoder nos nouvelles instructions. Les 7 bits inférieurs sont définis comme l'opcode, qui reçoit une valeur qui la marque comme une instruction personnalisée dans le custom-1 décoder l'espace. Ceci est par opposition au OP ou OP-IMM opcodes utilisés respectivement pour les instructions XOR et shift-left existantes.
Trois blocs de bits prédéfinis sont réservés dans la définition ISA pour prescrire les deux registres source et le registre de destination pour le résultat. Cela laisse un bloc de bits appelé funct3 . Ces trois bits nous permettent de coder huit instructions possibles, dont quatre seront utilisées dans cet exemple.
Sans nécessiter la mise en œuvre matérielle détaillée du RTL pour ces instructions, il est possible de les simuler dans l'environnement ISS pour voir si elles seraient d'un quelconque avantage pour le défi à relever. Les quatre nouvelles instructions sont modélisées à l'aide de l'interface de programmation d'applications (API) VMI des plates-formes virtuelles ouvertes (OVP). Cela permet au développeur d'itérer rapidement la conception des instructions qui fournissent le résultat optimal souhaité sur la base des nouvelles instructions pour l'application cible. Ce n'est qu'une fois cet objectif atteint qu'il est nécessaire d'affecter des ressources à une mise en œuvre RTL.
Aux fins de l'évaluation fonctionnelle initiale des instructions, deux approches sont possibles. La première consiste à appeler la version originale C/C++ de l'algorithme, en liant les nouvelles instructions à cette fonction (figure 5a). La seconde consiste à les implémenter en tant qu'instructions de morphing VMI qui créent le même comportement (figure 5b). Cela a l'avantage d'être plus efficace et c'est l'approche recommandée.


Bien entendu, la simple existence de nouvelles instructions ne signifie pas qu'un compilateur peut immédiatement les utiliser. Par conséquent, l'application C/C++ d'origine doit être réécrite à l'aide de l'assembleur en ligne et compilée de manière croisée pour utiliser les nouvelles instructions. Comme le profilage et l'analyse des instructions candidates peuvent être une tâche itérative, l'approche basée sur l'intrinsèque fournit le moyen le plus efficace d'adapter l'application C d'origine pour utiliser les nouvelles instructions personnalisées.
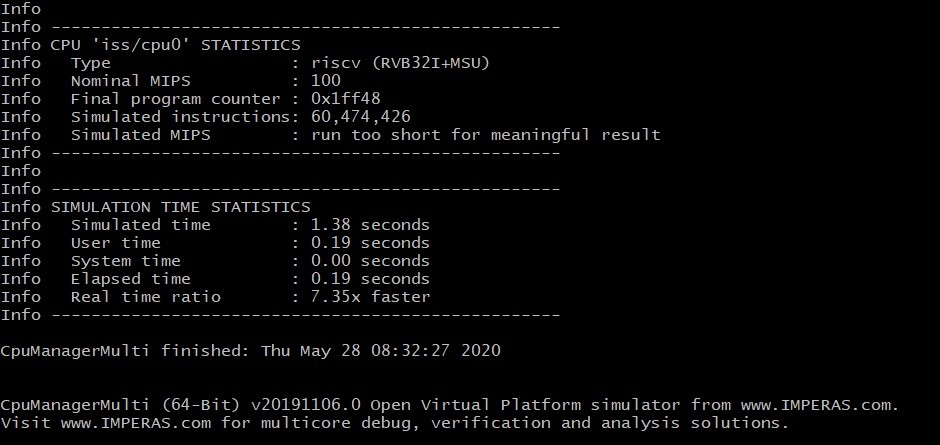
L'implémentation de base RISC-V chargée dans le simulateur doit également être informée des nouvelles instructions afin d'en bénéficier. Ceci est réalisé en les incluant dans le modèle avant de relancer la simulation. Dans cet exemple particulier, la répétition du profilage indique moins de temps global passé à exécuter l'algorithme (figure 6). L'outil de profilage Imperas VAP montre que le processWord() La fonction, utilisant les instructions intégrées dédiées, représente désormais 66% de l'exécution globale de l'algorithme mais le temps d'exécution global de l'algorithme est considérablement réduit (figure 6b).
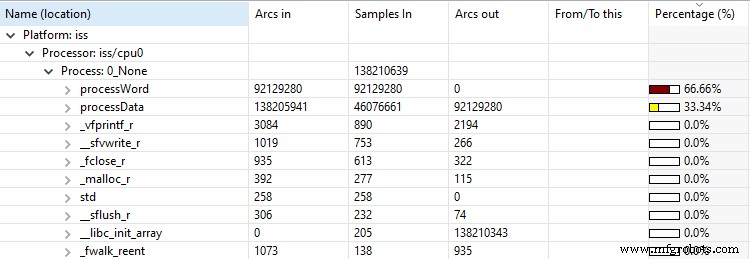
Résultats avec l'implémentation C d'origine
Info Instructions simulées :316 709 013
Info Temps simulé :5,15 secondes
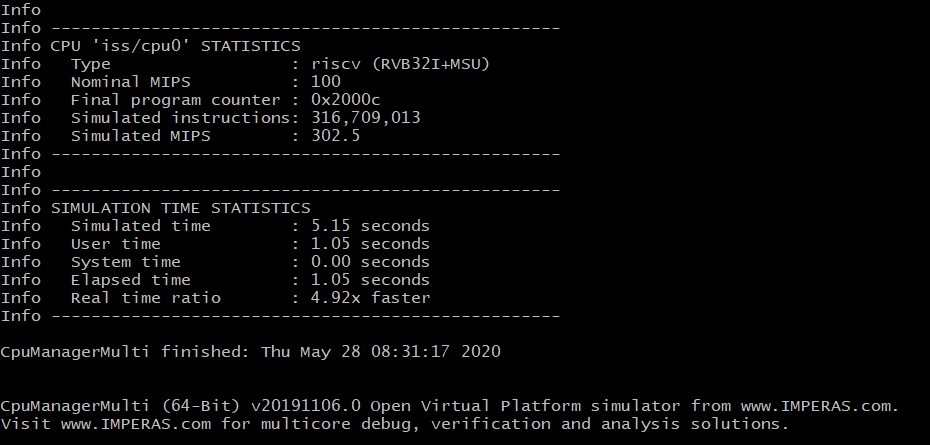
Résultats avec instructions personnalisées
Info Instructions simulées :60 474 426
Infos Durée simulée :1,38 seconde
Une fois que la fonctionnalité correcte a été déterminée, le modèle est encore affiné en déclarant le temps d'exécution pour chaque instruction en cycles de processeur. D'autres cycles de simulation peuvent ensuite être utilisés pour déterminer toute amélioration des performances, même en tenant compte des états d'attente associés aux accès mémoire qui peuvent se produire dans une éventuelle implémentation matérielle.
Grâce à l'étroite intégration avec les IDE open source communs et les outils GDB, le débogage complet de la solution peut être entrepris en conjonction avec la conception RISC-V optimisée avant d'engager la conception dans une implémentation matérielle (figure 7).
Passer de la simulation à la mise en œuvre
Une fois l'amélioration potentielle des performances déterminée, l'étape suivante nécessite la mise en œuvre des quatre nouvelles instructions dans RTL. Grâce aux travaux préliminaires entrepris, cela devient la spécification fonctionnelle qui définit les exigences et peut également être utilisée dans le cadre du plan de test de vérification RTL comme modèle de référence d'or. Bien que l'utilisation de fonctions intrinsèques dans l'application C ait aidé au profilage et à l'analyse d'instructions personnalisées, cette approche peut également être utilisée pour le développement futur de code de production ou peut être envisagée pour des améliorations potentielles de la chaîne d'outils du compilateur.
L'autre tâche essentielle restante, la documentation, est également un processus simple. Tous les modèles de processeurs rapides de plates-formes virtuelles ouvertes (OVP) incluent une documentation qui peut être étendue pour couvrir la fonctionnalité des changements et des modifications. En suivant le modèle donné, les nouvelles instructions peuvent être déclarées et décrites, permettant à la communauté des développeurs de découvrir leurs capacités et de les utiliser. La documentation est ensuite convertie en un fichier TeX à partir duquel un PDF peut être généré (figure 8).

Résumé
Avec les libertés de l'ISA ouvert de RISC-V, en plus des options et fonctionnalités standard définies dans la spécification, les utilisateurs peuvent développer d'autres extensions et instructions personnalisées. Dans sa forme la plus simple, il permet des modèles commerciaux nouveaux et créatifs, y compris des implémentations commerciales et open source, et il permet une plus grande liberté d'explorer des fonctionnalités à valeur ajoutée au-delà des approches traditionnelles traditionnelles.
Cependant, la vraie valeur réside dans le fait de prendre un noyau de base à part entière, documenté et pris en charge et de le modifier pour répondre aux besoins spécifiques des applications. Grâce à une analyse minutieuse des applications, au profilage du code et à la simulation, des améliorations de performances significatives peuvent être obtenues qui ne pourraient pas être réalisées avec des ISA fixes. Tout cela peut être développé et profilé avec des charges de travail d'application réelles avant de commencer la mise en œuvre matérielle détaillée.
Embarqué
- Profilage d'applications distribuées avec Perf
- Micropuce :applications spatiales à l'échelle avec des MCU Core COTS tolérants aux radiations
- Renesas :MCU RX72M avec prise en charge EtherCAT pour les applications industrielles
- Axiomtek :système embarqué avec switch PoE géré de couche 2 intégré
- Renégocier les coûts avec les fournisseurs existants :un guide
- Routeuse à bois CNC - Avec des applications étonnantes
- Premiers pas avec l'IA dans l'assurance :un guide d'introduction
- 5 applications réelles de l'IA en médecine (avec exemples)
- Un guide des sabots et plaquettes de frein personnalisés pour les applications ferroviaires à grande vitesse