


Data Lake vs Big Data pour les applications industrielles
Data Lake et Big Data sont deux termes modernes souvent mal conçus et utilisés de manière incorrecte. En raison des grands volumes de données impliqués, ces termes sont parfois utilisés de manière interchangeable. Cependant, le lac de données et le big data sont différents, même si leurs définitions actuelles ne sont peut-être pas encore complètement établies.

Figure 1. Les données modernes peuvent provenir de nombreuses sources et être de différents types. Image utilisée avec l'aimable autorisation d'Analytics Vidhya
Examinons d'abord un bref contexte historique. À la fin des années 2000, avec la croissance explosive des plateformes de médias sociaux, telles que Facebook et Twitter, de nombreux scientifiques des données ont commencé à réaliser le potentiel de ces plateformes pour générer de grandes quantités de données personnelles précieuses. Par conséquent, de nouvelles applications logicielles ont été développées pour faciliter le traitement et l'analyse des données. Un exemple frappant est Apache Hadoop, essentiellement une boîte à outils d'applications open source capables de traiter des niveaux d'informations volumineux.
Au cours de la décennie suivante, l'Internet des objets (IoT) est entré en scène. Cela a ouvert la porte à des millions de sources de données supplémentaires qui pourraient fournir des informations sur les préférences et les habitudes d'une personne, tout en envoyant des informations sur le produit lui-même.
Simultanément, l'apprentissage automatique faisait des progrès importants et trouvait des applications plus pratiques dans le paysage industriel. Cela a entraîné un besoin accru de gérer de gros volumes de données dans les industries, en particulier dans les processus automatisés.
Toutes les projections indiquent que la quantité globale de données disponibles dans le monde continuera d'augmenter à un rythme accéléré dans les années à venir. Pour référence, en 2016, le monde a franchi le cap de 1 Zettaoctet de trafic Internet annuel généré. Un zettaoctet équivaut à 1 000 milliards de gigaoctets.
Le trafic Internet annuel devrait dépasser les 3 zettaoctets en 2021. Ces projections, ainsi que les capacités étendues du cloud computing, indiquent que la valeur et les utilisations des mégadonnées (et des lacs de données) ne font peut-être que commencer.
Qu'est-ce que le Big Data ?
Lorsqu'on l'examine simplement du point de vue du volume, la définition des mégadonnées est une cible mouvante. À mesure que la quantité de données et d'espace de stockage disponible continue d'augmenter, la référence de ce qui est considéré comme de grandes quantités d'informations augmente également.
Aujourd'hui, un référentiel de données de 100 téraoctets ou plus est généralement considéré comme faisant partie de la gamme des mégadonnées. Les grands référentiels de données tels que ceux des plateformes de médias sociaux peuvent être de l'ordre de plusieurs pétaoctets.
Une autre référence utilisée pour définir le Big Data est lorsque la quantité d'informations ne peut pas être gérée par des outils informatiques traditionnels, tels que SQL. Par exemple, aujourd'hui, il n'est pas rare que les bases de données atteignent une taille de 1 téraoctet par an. Mais, les applications SQL devenant de plus en plus puissantes, cette ampleur de la base de données peut toujours être gérée; par conséquent, ils ne sont généralement pas considérés comme des mégadonnées.
Modèle 4V de Big Data
Jusqu'à présent, nous avons examiné la définition des mégadonnées du point de vue du volume. Il y a trois autres facteurs importants à considérer :la vitesse, la variété et la véracité. Ceux-ci, avec le volume, forment le modèle 4V.
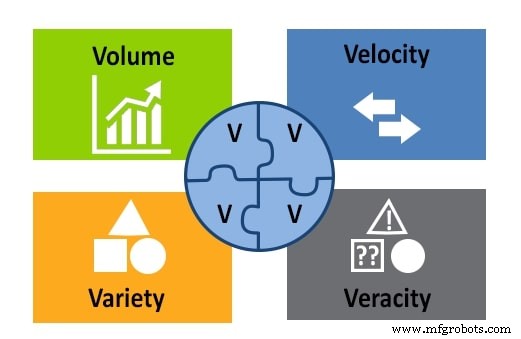
Figure 2. Le modèle 4V des mégadonnées :volume, vitesse, variété et véracité. Image utilisée avec l'aimable autorisation d'APSense
La variété fait référence à tous les différents types de données stockées dans un référentiel Big Data :texte, images, son, vidéo, etc. Elle fait également référence au fait que les données peuvent provenir de plusieurs sources.
La vitesse est une considération importante dans le Big Data, car les informations sont constamment diffusées. La vitesse concerne la vitesse à laquelle les données sont collectées, générées et distribuées.
La véracité mesure l'exactitude et la qualité des données pour évaluer si un data scientist peut les utiliser pour l'analyse et pour en tirer des conclusions.
Maintenant que nous comprenons les mégadonnées, examinons les lacs de données avant de découvrir comment les utiliser dans un système de contrôle.
Qu'est-ce qu'un lac de données ?
Les lacs de données sont des référentiels centralisés de grandes quantités de données brutes, c'est-à-dire des informations qui peuvent ou non avoir de la valeur à l'avenir et dont la finalité n'est pas encore connue à 100 %. Les lacs de données peuvent stocker des bases de données relationnelles et non relationnelles, ainsi que d'autres types de fichiers et d'entités.
Bien que les informations d'un lac de données ne soient ni traitées ni organisées, elles sont structurées de manière à ce que toutes les entrées et sorties soient prises en compte pour créer une bonne architecture.
Data Lake contre Big Data
Un lac de données est une instance d'une application Big Data. Ils suivent les critères décrits dans le modèle 4V, avec quelques particularités supplémentaires. En termes de volume, les lacs de données se situent, en moyenne, près de l'extrémité inférieure de ce qui est considéré comme des mégadonnées.
Les informations dans les lacs de données sont variées, mais la condition est qu'il ne s'agisse que de données brutes non traitées. Les vitesses d'entrée et de sortie sont aussi pertinentes qu'avec n'importe quel système moderne et les évaluations de la qualité des données sont effectuées dans un lac de données bien conçu.
Applications industrielles pour les données
L'automatisation avancée entraîne une augmentation rapide de la quantité d'informations traitées dans l'usine. Grâce à cela, la fabrication et d'autres processus industriels entrent désormais dans le domaine des mégadonnées, plusieurs activités commerciales utilisant désormais des outils tels que les lacs de données.
Un exemple frappant est la maintenance prédictive. La capacité de prédire une panne mécanique ou électrique est très précieuse et peut permettre de réaliser des économies substantielles sur les coûts de réparation. Les lacs de données sont des outils utiles qui peuvent compiler des informations provenant de fichiers journaux, de plusieurs capteurs et périphériques d'entrée, qui peuvent être utilisés pour comprendre les tendances et prévoir les problèmes.
L'apprentissage automatique est un concept dans lequel les robots reçoivent des informations qui peuvent les aider à s'adapter aux conditions externes changeantes. La capture d'informations est similaire à la maintenance prédictive, avec l'étape supplémentaire selon laquelle les évaluations et les modifications apportées au processus sont automatiquement transmises au contrôleur du système. Les données d'apprentissage automatique peuvent être stockées dans un lac de données structuré.
Figure 3. L'apprentissage automatique a plusieurs stratégies qui nécessitent chacune de grandes quantités de données. Image utilisée avec l'aimable autorisation de WordStream
Pour conclure, un lac de données est une instance d'une application Big Data. Ces deux façons de visualiser les données peuvent fonctionner ensemble. En utilisant à la fois le Big Data et le Data Lake, un ingénieur de contrôle peut prévoir les pannes, créer des routines de maintenance, développer la transformation numérique de l'installation, et bien plus encore.
Pourquoi utilisez-vous le Big Data et les lacs de données dans votre travail ?
Technologie de l'Internet des objets
- Capteurs et processeurs convergent pour les applications industrielles
- GE présente un service cloud pour les données industrielles et l'analyse
- Perspectives de développement de l'IoT industriel
- Quatre grands défis pour l'Internet des objets industriel
- Six éléments essentiels pour réussir les applications basées sur les capteurs
- Comment donner du sens au Big Data :RTU et applications de contrôle de processus
- Préparer le terrain pour le succès de la science des données industrielles
- Pour un véritable aperçu industriel de l'Internet :ne vous contentez pas de capturer des données, utilisez-les
- Les mégadonnées seront-elles une panacée pour les budgets de santé en difficulté ?