


Union en langage C pour l'emballage et le déballage des données
En savoir plus sur l'emballage et le déballage des données avec des unions en langage C.
En savoir plus sur l'emballage et le déballage des données avec les unions en langage C.
Dans un article précédent, nous avons expliqué que l'application originale des unions avait créé une zone de mémoire partagée pour les variables mutuellement exclusives. Cependant, au fil du temps, les programmeurs ont largement utilisé les unions pour une application complètement différente :extraire de plus petites parties de données à partir d'un objet de données plus grand. Dans cet article, nous examinerons plus en détail cette application particulière des syndicats.
Utiliser des unions pour emballer/déballer des données
Les membres d'un syndicat sont stockés dans une zone de mémoire partagée. C'est la caractéristique clé qui nous permet de trouver des applications intéressantes pour les syndicats.
Considérez l'union ci-dessous :
union { mot uint16_t ; struct { uint8_t byte1; uint8_t octet2 ; };} u1; Il y a deux membres à l'intérieur de cette union :Le premier membre, « mot », est une variable à deux octets. Le deuxième membre est une structure de deux variables d'un octet. Les deux octets alloués à l'union sont partagés entre ses deux membres.
L'espace mémoire alloué peut être comme indiqué dans la figure 1 ci-dessous.
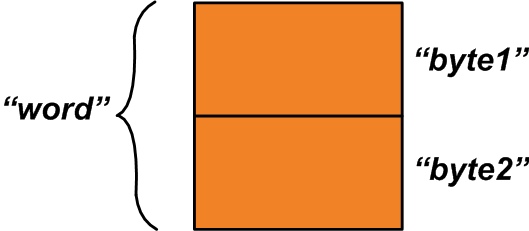
Figure 1
Alors que la variable "mot" fait référence à l'ensemble de l'espace mémoire alloué, les variables "octet1" et "octet2" font référence aux zones d'un octet qui construisent la variable "mot". Comment pouvons-nous utiliser cette fonctionnalité ? Supposons que vous ayez deux variables à un octet, « x » et « y », qui doivent être combinées pour produire une seule variable à deux octets.
Dans ce cas, vous pouvez utiliser l'union ci-dessus et affecter « x » et « y » aux membres de la structure comme suit :
u1.byte1 =y;u1.byte2 =x; Maintenant, nous pouvons lire le "mot" membre de l'union pour obtenir une variable à deux octets composée de variables "x" et "y" (voir Figure 2).
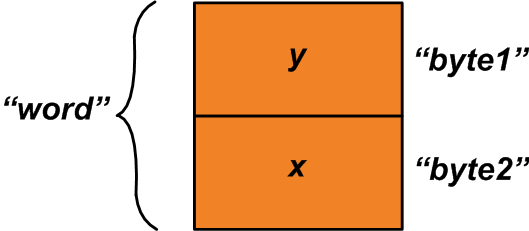
Figure 2
L'exemple ci-dessus montre l'utilisation d'unions pour regrouper deux variables d'un octet dans une seule variable de deux octets. Nous pourrions également faire l'inverse :écrire une valeur de deux octets dans « word » et la décompresser en deux variables d'un octet en lisant les variables « x » et « y ». L'écriture d'une valeur à un membre d'un syndicat et la lecture d'un autre membre de celui-ci sont parfois appelées « données de calembour ».
L'extrémité du processeur
Lors de l'utilisation d'unions pour l'emballage/déballage des données, nous devons faire attention à l'extrémité du processeur. Comme indiqué dans l'article de Robert Keim sur l'endianité, ce terme spécifie l'ordre dans lequel les octets d'un objet de données sont stockés en mémoire. Un processeur peut être little endian ou big endian. Avec un processeur big-endian, les données sont stockées de manière à ce que l'octet contenant le bit le plus significatif ait l'adresse mémoire la plus faible. Dans les systèmes little-endian, l'octet contenant le bit le moins significatif est stocké en premier.
L'exemple illustré à la figure 3 illustre le stockage petit-boutiste et grand-boutiste de la séquence 0x01020304.
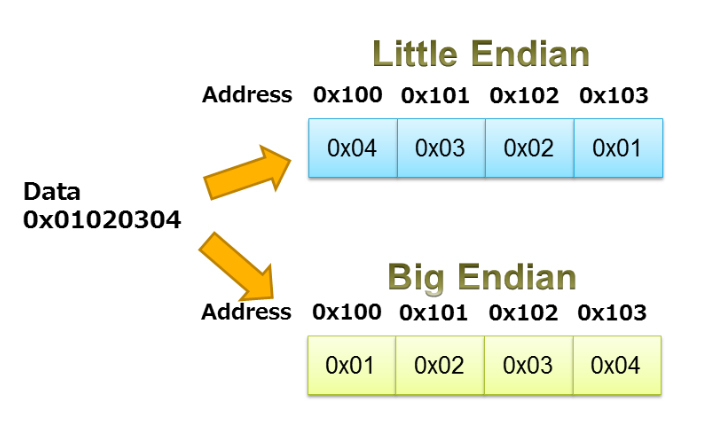
Figure 3. Image reproduite avec l'aimable autorisation de l'IRA.
Utilisons le code suivant pour expérimenter l'union de la section précédente :
#include <stdio.h>#include <stdint.h>int main(){ union { struct{ uint8_t byte1; uint8_t octet2 ; } ; uint16_t mot ; } u1; u1.byte1 =0x21;u1.byte2 =0x43; printf("Le mot est : %#X", u1.word);return 0;} En exécutant ce code, j'obtiens le résultat suivant :
Le mot est :0X4321
Cela montre que le premier octet de l'espace mémoire partagé (« u1.byte1 ») est utilisé pour stocker l'octet de poids faible (0X21) de la variable « word ». En d'autres termes, le processeur que j'utilise pour exécuter le code est little endian.
Comme vous pouvez le voir, cette application particulière des unions peut présenter un comportement dépendant de l'implémentation. Cependant, cela ne devrait pas être un problème grave car pour un tel codage de bas niveau, nous connaissons généralement le caractère endian du processeur. Si nous ne connaissons pas ces détails, nous pouvons utiliser le code ci-dessus pour savoir comment les données sont organisées dans la mémoire.
Solution alternative
Au lieu d'utiliser des unions, nous pouvons également utiliser les opérateurs au niveau du bit pour effectuer le compactage ou le dépaquetage des données. Par exemple, nous pouvons utiliser le code suivant pour combiner deux variables d'un octet, "byte3" et "byte4", et produire une seule variable de deux octets ("word2") :
word2 =(((uint16_t) byte3) <<8 ) | ((uint16_t) octet4) ; Comparons la sortie de ces deux solutions dans les cas petit et gros boutien. Considérez le code ci-dessous :
#include <stdio.h>#include <stdint.h>int main(){union { struct { uint8_t byte1; uint8_t octet2 ; } ; uint16_t mot1; } u1; u1.byte1 =0x21;u1.byte2 =0x43;printf("Word1 is:%#X\n", u1.word1); uint8_t octet3, octet4;uint16_t mot2;octet3 =0x21;octet4 =0x43;mot2 =(((uint16_t) octet3) <<8 ) | ((uint16_t) byte4);printf("Word2 est :%#X \n", word2) ; return 0;} Si nous compilons ce code pour un processeur big endian tel que TMS470MF03107 , la sortie sera :
Word1 est :0X2143
Word2 est :0X2143
Cependant, si nous le compilons pour un petit processeur endian tel que STM32F407IE , la sortie sera :
Word1 est :0X4321
Word2 est :0X2143
Alors que la méthode basée sur l'union présente un comportement dépendant du matériel, la méthode basée sur l'opération de décalage conduit au même résultat quel que soit l'endianisme du processeur. Ceci est dû au fait qu'avec cette dernière approche, on attribue une valeur au nom d'une variable (« word2 ») et le compilateur se charge de l'organisation mémoire employée par l'appareil. Cependant, avec la méthode basée sur l'union, nous modifions la valeur des octets qui construisent la variable "word1".
Bien que la méthode basée sur l'union présente un comportement dépendant du matériel, elle a l'avantage d'être plus lisible et maintenable. C'est pourquoi de nombreux programmeurs préfèrent utiliser des unions pour cette application.
Un exemple pratique de « Data Punning »
Lorsque vous travaillez avec des protocoles de communication série courants, nous pouvons avoir besoin d'effectuer un emballage ou un déballage des données. Considérons un protocole de communication série qui envoie/reçoit un octet de données au cours de chaque séquence de communication. Tant que nous travaillons avec des variables d'un octet, il est facile de transférer les données, mais que se passe-t-il si nous avons une structure de taille arbitraire qui doit passer par le lien de communication ? Dans ce cas, nous devons en quelque sorte représenter notre objet de données sous la forme d'un tableau de variables d'un octet. Une fois que nous obtenons cette représentation de tableau d'octets, nous pouvons transférer les octets via le lien de communication. Ensuite, du côté du récepteur, nous pouvons les emballer de manière appropriée et reconstruire la structure d'origine.
Par exemple, supposons que nous devions envoyer une variable flottante, "f1", via la communication UART. Une variable flottante occupe généralement quatre octets. Par conséquent, nous pouvons utiliser l'union suivante comme tampon pour extraire les quatre octets de « f1 » :
union { float f; struct { uint8_t octet[4]; };} u1; L'émetteur écrit la variable « f1 » dans le membre flottant de l'union. Ensuite, il lit le tableau "byte" et envoie les octets sur la liaison de communication. Le récepteur fait l'inverse :il écrit les données reçues dans le tableau "byte" de sa propre union et lit la variable flottante de l'union comme valeur reçue. Nous pourrions utiliser cette technique pour transférer un objet de données de taille arbitraire. Le code suivant peut être un simple test pour vérifier cette technique.
#include <stdio.h>#include <stdint.h>int main(){float f1=5.5; union buffer { float f; struct { uint8_t octet[4]; } ; } ; tampon union buff_Tx;tampon union buff_Rx;buff_Tx.f =f1;buff_Rx.byte[0] =buff_Tx.byte[0];buff_Rx.byte[1] =buff_Tx.byte[1];buff_Rx.byte[2] =buff_Tx .byte[2];buff_Rx.byte[3] =buff_Tx.byte[3]; printf("Les données reçues sont :%f", buff_Rx.f); return 0;} La figure 4 ci-dessous visualise la technique discutée. Notez que les octets sont transférés séquentiellement.
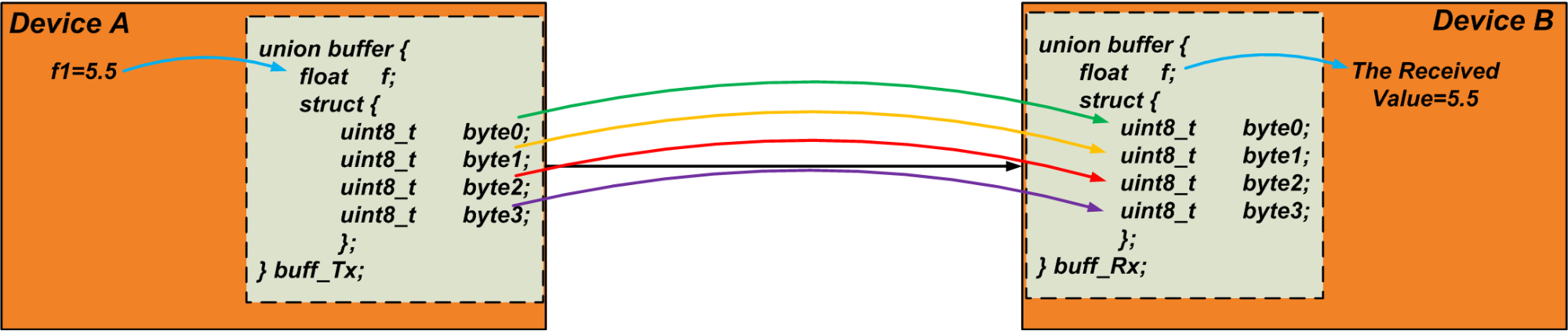
Figure 4
Conclusion
Alors que l'application originale des unions créait une zone de mémoire partagée pour les variables mutuellement exclusives, au fil du temps, les programmeurs ont largement utilisé les unions pour une application complètement différente :utiliser les unions pour le compactage/décompression des données. Cette application particulière des syndicats consiste à écrire une valeur à un membre du syndicat et à en lire un autre.
Le « punition des données » ou l'utilisation d'unions pour le regroupement/décompression des données peut entraîner un comportement dépendant du matériel. Cependant, il a l'avantage d'être plus lisible et maintenable. C'est pourquoi de nombreux programmeurs préfèrent utiliser des unions pour cette application. Le « donc de jeu de mots » peut être particulièrement utile lorsque nous avons un objet de données de taille arbitraire qui doit passer par une liaison de communication série.
Pour voir une liste complète de mes articles, veuillez visiter cette page.
Embarqué
- Sémaphores :services utilitaires et structures de données
- Stratégie et solutions de l'armée pour la maintenance conditionnelle
- Les avantages de l'adaptation des solutions IIoT et d'analyse de données pour l'EHS
- Créer une IA responsable et digne de confiance
- Qu'est-ce que le fog computing et qu'est-ce que cela signifie pour l'IoT ?
- C - Syndicats
- Pourquoi les données et le contexte sont essentiels pour la visibilité de la chaîne d'approvisionnement
- Pour la gestion de flotte, l'IA et l'IoT sont mieux ensemble
- AIoT industriel :combiner l'intelligence artificielle et l'IoT pour l'industrie 4.0