


Les chercheurs montrent une puce d'IA avec une formation de précision réduite
À l'ISSCC, IBM Research a présenté une puce de test qui représente la manifestation matérielle de ses années de travail sur les algorithmes de formation et d'inférence d'IA de faible précision. La puce 7 nm prend en charge la formation 16 bits et 8 bits, ainsi que l'inférence 4 bits et 2 bits (la formation 32 bits ou 16 bits et l'inférence 8 bits sont la norme de l'industrie aujourd'hui).
Réduire la précision peut réduire la quantité de calcul et de puissance requise pour le calcul de l'IA, mais IBM a quelques autres astuces architecturales dans sa manche qui contribuent également à l'efficacité. Le défi est de réduire la précision sans affecter négativement le résultat du calcul, ce sur quoi IBM travaille depuis plusieurs années au niveau de l'algorithme.
L'IA Hardware Center d'IBM a été créé en 2019 pour soutenir l'objectif de l'entreprise d'augmenter les performances de calcul de l'IA 2,5 fois par an, avec un objectif global ambitieux d'amélioration de l'efficacité des performances (FLOPS/W) 1000 fois d'ici 2029. Des objectifs ambitieux de performances et de puissance sont nécessaires depuis la taille des modèles d'IA et la quantité de calculs nécessaires pour les entraîner augmentent rapidement. Les modèles de traitement du langage naturel (NLP) en particulier sont désormais des mastodontes de mille milliards de paramètres, et l'empreinte carbone qui accompagne l'entraînement de ces bêtes n'est pas passée inaperçue.
Cette dernière puce de test d'IBM Research montre les progrès réalisés par IBM jusqu'à présent. Pour l'entraînement 8 bits, la puce à 4 cœurs est capable de 25,6 TFLOPS, tandis que les performances d'inférence sont de 102,4 TOPS pour le calcul d'entiers à 4 bits (ces chiffres sont pour une fréquence d'horloge de 1,6 GHz et une tension d'alimentation de 0,75 V). La réduction de la fréquence d'horloge à 1 GHz et de la tension d'alimentation à 0,55 V augmente l'efficacité énergétique à 3,5 TFLOPS/W (FP8) ou 16,5 TOPS/W (INT4).
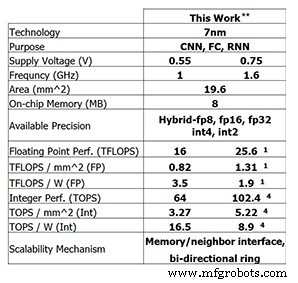
Performances de la puce de test d'IBM Research (Image :IBM Research) ** Performances rapportées à 0 % de parcimonie. (1) FP8. (4) INT4.
Entraînement de faible précision
Cette performance s'appuie sur des années de travail algorithmique sur des techniques d'entraînement et d'inférence de faible précision. La puce est la première à prendre en charge le format spécial à virgule flottante hybride 8 bits d'IBM (hybride FP8) qui a été présenté pour la première fois à NeurIPS 2019. Ce nouveau format a été spécialement développé pour permettre la formation 8 bits, réduisant de moitié le calcul requis pour 16 bits. formation, sans affecter négativement les résultats (en savoir plus sur les formats de nombres pour le traitement de l'IA ici).
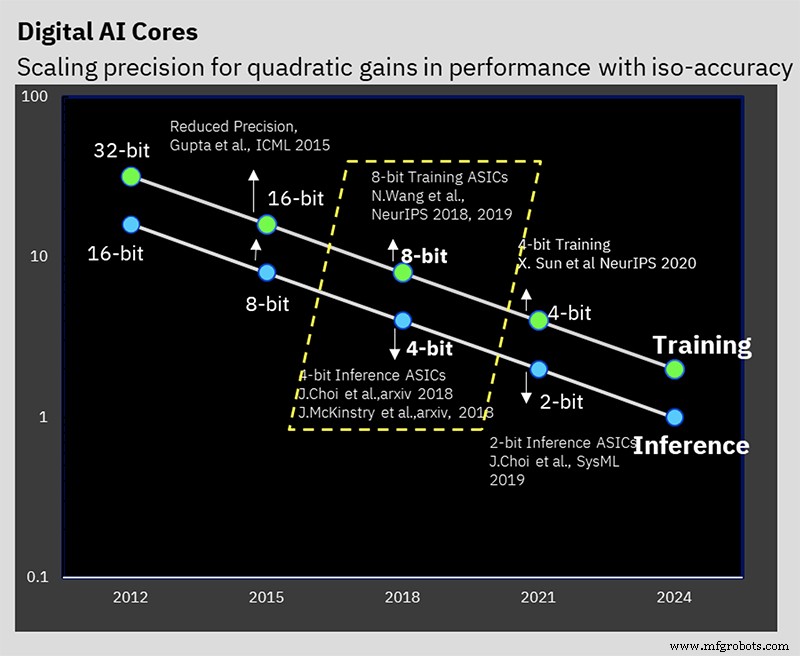
IBM Research a travaillé sur la résolution du problème du maintien de la précision tout en réduisant la précision (Image :IBM)
"Ce que nous avons appris dans nos diverses études au fil des ans, c'est que la formation de faible précision est très difficile, mais vous pouvez faire une formation 8 bits si vous avez les bons formats de nombres", Kailash Gopalakrishnan, IBM Fellow et directeur principal pour les architectures d'accélérateurs et l'apprentissage automatique chez IBM Research a déclaré EE Times . "La compréhension des bons formats numériques et leur mise sur les bons tenseurs dans l'apprentissage en profondeur en étaient un élément essentiel."
Hybrid FP8 est en fait une combinaison de deux formats différents. Un format est utilisé pour les pondérations et les activations dans la passe avant de l'apprentissage en profondeur, et un autre est utilisé dans la passe arrière. L'inférence utilise uniquement la passe avant, alors que l'entraînement nécessite à la fois des phases avant et arrière.
"Ce que nous avons appris, c'est que vous avez besoin de plus de fidélité, de plus de précision, en termes de représentation des poids et des activations dans la passe avant de l'apprentissage en profondeur", a déclaré Gopalakrishnan. « D'un autre côté [la phase arrière], les gradients ont une plage dynamique élevée, et c'est là que nous reconnaissons la nécessité d'avoir un [plus grand] exposant… c'est le compromis entre la façon dont certains tenseurs en apprentissage en profondeur ont besoin plus de précision, une représentation plus fidèle, tandis que d'autres tenseurs ont besoin d'une plage dynamique plus large. C'est la genèse du format hybride FP8 que nous avons présenté fin 2019, qui s'est maintenant traduit en matériel. »
Les travaux d'IBM ont déterminé que la meilleure façon de diviser les 8 bits entre l'exposant et la mantisse est 1-4-3 (un bit de signe, un exposant de quatre bits et une mantisse de trois bits) pour la phase avant, avec une alternative 5- version d'exposant de bits pour la phase arrière, ce qui donne une plage dynamique de 2 32 . Le matériel hybride compatible FP8 est conçu pour prendre en charge ces deux formats.
Accumulation hiérarchique
Une innovation que les chercheurs appellent « l'accumulation hiérarchique » permet à l'accumulation de réduire la précision aux côtés des poids et des activations. Les programmes de formation FP16 typiques s'accumulent en arithmétique 32 bits pour préserver la précision, mais la formation 8 bits d'IBM peut s'accumuler dans FP16. Conserver l'accumulation dans le FP32 aurait limité les avantages tirés du passage au FP8 en premier lieu.
« Ce qui se passe dans l'arithmétique à virgule flottante, c'est que si vous ajoutez un grand ensemble de nombres ensemble, disons que c'est un vecteur de 10 000 longueurs et que vous ajoutez le tout ensemble, la précision de la représentation en virgule flottante elle-même commence à limiter la précision de votre somme », a expliqué Gopalakrishnan. «Nous avons conclu que la meilleure façon de le faire n'est pas de faire l'addition de manière séquentielle, mais nous avons tendance à diviser la longue accumulation en groupes, ce que nous appelons des morceaux. Et puis nous ajoutons les morceaux les uns aux autres, et cela minimise la probabilité d'avoir ce genre d'erreurs. »
Inférence de faible précision
La plupart des inférences d'IA utilisent aujourd'hui le format d'entier 8 bits (INT8). Les travaux d'IBM ont montré que l'entier 4 bits est l'état de l'art en termes de faible précision sans perdre une précision de prédiction significative. Après la quantification (le processus de conversion du modèle en nombres de précision inférieure), un apprentissage prenant en compte la quantification est effectué. Il s'agit effectivement d'un schéma de réapprentissage qui atténue toutes les erreurs résultant de la quantification. Ce recyclage peut minimiser la perte de précision; IBM peut quantifier en arithmétique d'entiers de 4 bits « facilement » avec seulement un demi pour cent de perte de précision, ce qui, selon Gopalakrishnan, est « très acceptable » pour la plupart des applications.
Anneau sur puce
Outre l'accent mis sur l'arithmétique de faible précision, il existe d'autres innovations matérielles qui contribuent à l'efficacité de la puce.
L'une est la communication en anneau sur puce, un réseau sur puce optimisé pour l'apprentissage en profondeur qui permet à chacun des cœurs de diffuser des données en multidiffusion vers les autres. La communication multidiffusion est essentielle à l'apprentissage en profondeur, car les cœurs doivent partager les poids et communiquer les résultats aux autres cœurs. Il permet également aux données chargées à partir de la mémoire hors puce d'être diffusées vers plusieurs cœurs. Cela réduit le nombre de lectures de la mémoire et la quantité globale de données envoyées, minimisant ainsi la bande passante mémoire requise.
"Nous avons réalisé que nous pouvions faire fonctionner les cœurs plus rapidement que les anneaux, car les anneaux impliquent beaucoup de longs fils", a déclaré Ankur Agrawal, membre du personnel de recherche en apprentissage automatique et architectures d'accélérateurs chez IBM Research. « Nous avons découplé la fréquence de fonctionnement de l'anneau de la fréquence de fonctionnement des noyaux… ce qui nous permet d'optimiser indépendamment les performances de l'anneau par rapport aux noyaux. »
Gestion de l'alimentation
Une autre innovation d'IBM a été d'introduire un schéma de mise à l'échelle des fréquences pour maximiser l'efficacité.
"Les charges de travail d'apprentissage en profondeur sont un peu spéciales, car même pendant la phase de compilation, vous savez quelles phases de calcul vous allez rencontrer dans cette très grande charge de travail", a déclaré Agrawal. « Nous pouvons effectuer une préconfiguration pour déterminer à quoi ressemblera le profil de puissance dans différentes parties du calcul. »
Le profil de puissance de l'apprentissage en profondeur a généralement de grands pics (pour les opérations lourdes de calcul comme la convolution) et des creux (peut-être pour les fonctions d'activation).
Le schéma d'IBM définit la tension et la fréquence de fonctionnement initiales de la puce de manière assez agressive, de sorte que même pour les modes de puissance les plus bas, la puce est presque à la limite de son enveloppe de puissance. Ensuite, lorsque plus de puissance est requise, la fréquence de fonctionnement est réduite.
"Le résultat net est une puce qui fonctionne presque à la puissance de crête tout au long du calcul, même à travers les différentes phases", a expliqué Agrawal. « Dans l'ensemble, en n'ayant pas ces phases de faible consommation d'énergie, vous pouvez tout faire plus rapidement. Vous avez traduit toute baisse de consommation d'énergie en gains de performances en maintenant votre consommation d'énergie presque au niveau de consommation de pointe pour toutes les phases de fonctionnement. »
La mise à l'échelle de la tension n'est pas utilisée car elle est plus difficile à faire à la volée ; le temps nécessaire pour se stabiliser à la nouvelle tension est trop long pour un calcul d'apprentissage en profondeur. IBM choisit donc généralement de faire fonctionner la puce à la tension d'alimentation la plus basse possible pour ce nœud de processus.
Puce de test
La puce de test d'IBM a quatre cœurs, en partie pour permettre de tester toutes les différentes fonctionnalités. Gopalakrishnan a décrit comment la taille du noyau est délibérément choisie pour être optimale; une architecture de milliers de cœurs minuscules est complexe à connecter ensemble, alors que diviser le problème entre de gros cœurs peut également être difficile. Ce noyau intermédiaire a été conçu pour répondre aux besoins d'IBM et de ses partenaires de l'AI Hardware Center, en trouvant un juste milieu en termes de taille.
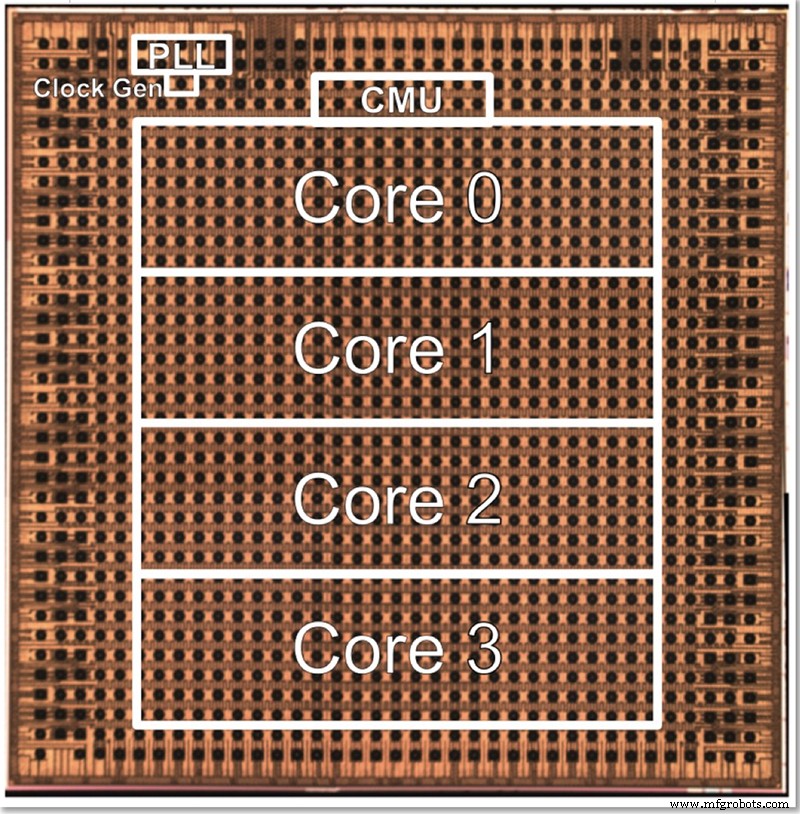
Une photo de matrice pour la puce de test basse précision à 4 cœurs d'IBM (Image :IBM)
L'architecture peut être agrandie ou réduite en modifiant le nombre de cœurs. Finalement, Gopalakrishnan imagine que les puces à 1 ou 2 cœurs conviendraient aux périphériques de périphérie, tandis que les puces à 32 à 64 cœurs pourraient fonctionner dans le centre de données. Le fait qu'il prenne en charge plusieurs formats (FP16, hybride FP8, INT4 et INT2) le rend également suffisamment polyvalent pour la plupart des applications, a-t-il déclaré.
"Différents domaines [d'application] auraient des exigences différentes en matière d'efficacité énergétique et de précision et ainsi de suite", a-t-il déclaré. "Notre couteau suisse de précision, chacun optimisé individuellement, nous permet de cibler ces noyaux dans divers domaines sans nécessairement renoncer à toute efficacité énergétique dans ce processus."
Parallèlement au matériel, IBM Research a également développé une pile d'outils ("Deep Tools") dont le compilateur permet une utilisation élevée de la puce (60-90%).
Heures EE ' une précédente interview avec IBM Research a révélé que la formation d'IA de faible précision et les puces d'inférence basées sur cette architecture devraient arriver sur le marché dans environ deux ans.
>> Cet article a été initialement publié le notre site partenaire, EE Times.
Contenus associés :
- Les puces d'IA maintiennent la précision grâce à la réduction du modèle
- Former des modèles d'IA à la pointe de la technologie
- La course est lancée pour l'IA à la limite
- Edge AI défie la technologie de la mémoire
- Le groupe d'ingénieurs cherche à pousser l'IA de 1 mW jusqu'au bout
- Application de réseaux de neurones pour des tâches à petite échelle
- La recherche AI IC explore des architectures alternatives
Pour plus d'informations sur Embedded, abonnez-vous à la newsletter hebdomadaire d'Embedded.
Embarqué
- Concevoir avec Bluetooth Mesh :puce ou module ?
- Les chercheurs créent une petite étiquette d'identification d'authentification
- Gérer un personnel de maintenance réduit
- L'alliance de Rockwell avec l'université du Minnesota étend l'accès à la formation en automatisation
- Des chercheurs montrent comment exploiter les failles de sécurité de Bluetooth Classic
- Comment IBM Watson alimente toutes les autres entreprises avec l'IA
- Améliorez vos efforts marketing pour être performants avec la précision de l'agence
- Améliorez vos efforts marketing pour être performants avec la précision de l'agence
- IBM :garantir de manière proactive la fiabilité et la sécurité avec EAM