


Comment l'informatique en mémoire analogique peut résoudre les problèmes de puissance de l'inférence Edge AI
L'apprentissage automatique et l'apprentissage en profondeur font déjà partie intégrante de nos vies. Les applications d'intelligence artificielle (IA) via le traitement du langage naturel (NLP), la classification d'images et la détection d'objets sont profondément ancrées dans de nombreux appareils que nous utilisons. La plupart des applications d'IA sont servies via des moteurs basés sur le cloud qui fonctionnent bien pour ce pour quoi elles sont utilisées, comme l'obtention de prédictions de mots lors de la saisie d'une réponse par e-mail dans Gmail.
Autant nous apprécions les avantages de ces applications d'IA, autant cette approche introduit des défis en matière de confidentialité, de dissipation de puissance, de latence et de coût. Ces défis peuvent être résolus s'il existe un moteur de traitement local capable d'effectuer un calcul partiel ou complet (inférence) à l'origine des données elles-mêmes. Cela a été difficile à faire avec les implémentations traditionnelles de réseaux de neurones numériques, dans lesquels la mémoire devient un goulot d'étranglement énergivore. Le problème peut être résolu avec une mémoire à plusieurs niveaux et l'utilisation d'une méthode de calcul analogique en mémoire qui, ensemble, permet aux moteurs de traitement de répondre aux exigences de puissance beaucoup plus faibles, allant du milliwatt (mW) au microwatt (uW) pour effectuer l'inférence de l'IA à la périphérie du réseau.
Défis du Cloud Computing
Lorsque les applications d'IA sont servies via des moteurs basés sur le cloud, l'utilisateur doit télécharger certaines données (volontairement ou non) vers des clouds où les moteurs de calcul traitent les données, fournissent des prédictions et envoient les prédictions en aval à l'utilisateur pour qu'il les consomme.

Figure 1 :Transfert de données d'Edge vers le Cloud. (Source :Microchip Technology)
Les défis associés à ce processus sont décrits ci-dessous :
- Préoccupations relatives à la confidentialité et à la sécurité : Avec des appareils toujours allumés et toujours conscients, il y a un risque que les données personnelles (et/ou les informations confidentielles) soient mal utilisées, que ce soit pendant les téléchargements ou pendant leur durée de conservation dans les centres de données.
- Dissipation de puissance inutile : Si chaque bit de données va vers le cloud, il consomme de l'énergie du matériel, des radios, de la transmission et potentiellement des calculs indésirables dans le cloud.
- Latence pour les inférences en petits lots : Parfois, cela peut prendre une seconde ou plus pour obtenir une réponse d'un système basé sur le cloud si les données proviennent de la périphérie. Pour les sens humains, tout ce qui dépasse 100 millisecondes (ms) de latence est perceptible et peut être ennuyeux.
- L'économie des données doit avoir du sens : Les capteurs sont partout, et ils sont très abordables; cependant, ils produisent beaucoup de données. Il n'est pas économique de télécharger chaque bit de données dans le cloud et de les traiter.
Pour résoudre ces problèmes à l'aide d'un moteur de traitement local, le modèle de réseau de neurones qui effectuera les opérations d'inférence doit d'abord être formé avec un ensemble de données donné pour le cas d'utilisation souhaité. Généralement, cela nécessite des ressources de calcul (et de mémoire) élevées et des opérations arithmétiques en virgule flottante. En conséquence, la partie formation d'une solution d'apprentissage automatique doit toujours être effectuée sur des clouds publics ou privés (ou une ferme GPU, CPU, FPGA locale) avec un ensemble de données pour générer un modèle de réseau neuronal optimal. Une fois que le modèle de réseau neuronal est prêt, le modèle peut en outre être optimisé pour un matériel local avec un petit moteur informatique, car le modèle de réseau neuronal n'a pas besoin de rétro-propagation pour l'opération d'inférence. Un moteur d'inférence a généralement besoin d'une mer de moteurs de multiplication-accumulation (MAC), suivi d'une couche d'activation telle que l'unité linéaire rectifiée (ReLU), sigmoïde ou tanh en fonction de la complexité du modèle de réseau neuronal et d'une couche de mise en commun entre les couches.
La majorité des modèles de réseaux de neurones nécessitent une grande quantité d'opérations MAC. Par exemple, même un modèle « 1.0 MobileNet-224 » relativement petit comporte 4,2 millions de paramètres (poids) et nécessite 569 millions d'opérations MAC pour effectuer une inférence. Étant donné que la plupart des modèles sont dominés par les opérations MAC, l'accent sera mis ici sur cette partie du calcul de l'apprentissage automatique - et sur l'exploration de l'opportunité de créer une meilleure solution. Un réseau à deux couches simple et entièrement connecté est illustré ci-dessous dans la figure 2.
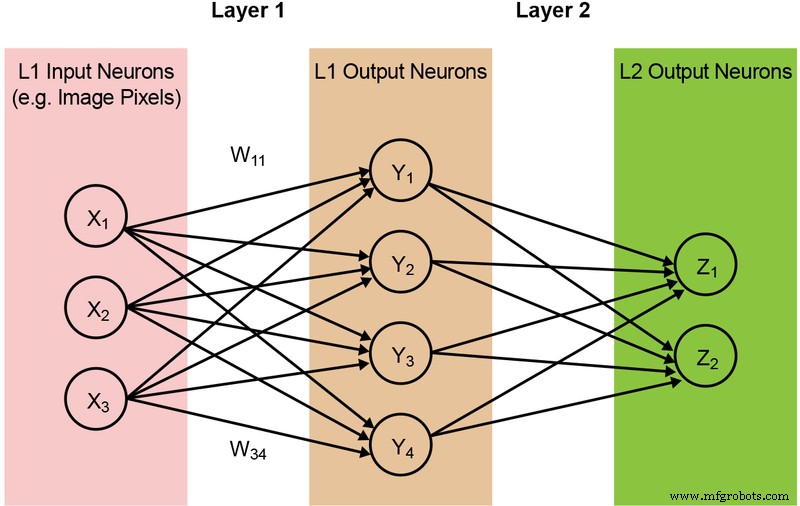
Figure 2 : réseau neuronal entièrement connecté à deux couches. (Source :Microchip Technology)
Les neurones d'entrée (données) sont traités avec la première couche de poids. Les neurones de sortie des premières couches sont ensuite traités avec la deuxième couche de poids et fournissent des prédictions (disons, si le modèle a pu trouver un visage de chat dans une image donnée). Ces modèles de réseaux neuronaux utilisent le « produit scalaire » pour le calcul de chaque neurone dans chaque couche, illustré par l'équation suivante (en omettant le terme « biais » dans l'équation pour la simplification) :
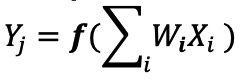
Mémoire Engorgement de l'informatique numérique
Dans une mise en œuvre de réseau neuronal numérique, les poids et les données d'entrée sont stockés dans une DRAM/SRAM. Les poids et les données d'entrée doivent être déplacés vers un moteur MAC pour l'inférence. Conformément à la figure 3 ci-dessous, cette approche entraîne la dissipation de la majeure partie de la puissance lors de la récupération des paramètres du modèle et des données d'entrée vers l'ALU où se déroule l'opération MAC réelle.
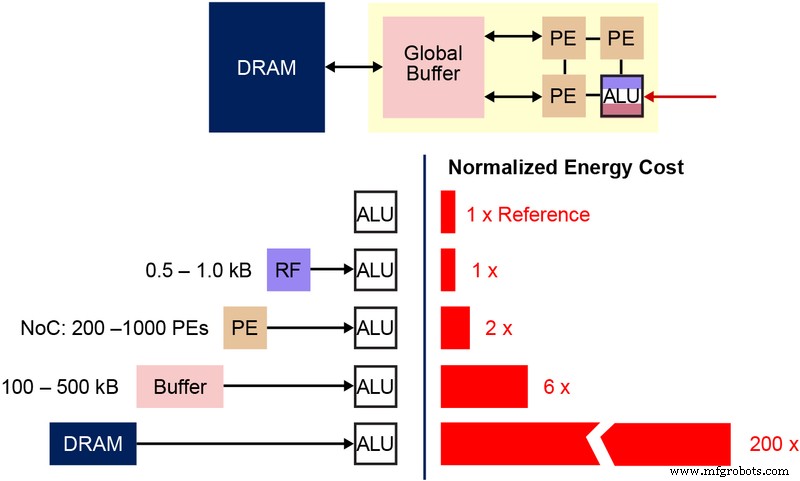
Figure 3 :Goulot d'étranglement de la mémoire dans le calcul de l'apprentissage automatique. (Source :Y.-H. Chen, J. Emer et V. Sze, « Eyeriss :A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks », dans ISCA, 2016.)
Pour mettre les choses dans une perspective énergétique - une opération MAC typique utilisant des portes logiques numériques consomme ~ 250 femtojoules (fJ, ou 10 -15 joules) d'énergie, mais l'énergie dissipée lors du transfert de données est de plus de deux ordres de grandeur que le calcul lui-même et se situe dans la plage de 50 picojoules (pJ, ou 10 −12 joules) à 100pJ. Pour être juste, il existe de nombreuses techniques de conception disponibles pour minimiser le transfert de données de la mémoire vers l'ALU; Cependant, l'ensemble du schéma numérique est toujours limité par l'architecture Von Neumann - cela présente donc une grande opportunité de réduire le gaspillage d'énergie. Et si l'énergie nécessaire pour effectuer une opération MAC pouvait être réduite de ~100pJ à une fraction de pJ ?
Suppression du goulot d'étranglement de la mémoire avec l'informatique analogique en mémoire
L'exécution d'opérations d'inférence à la périphérie devient économe en énergie lorsque la mémoire elle-même peut être utilisée pour réduire la puissance requise pour le calcul. L'utilisation d'une méthode de calcul en mémoire minimise la quantité de données à déplacer. Ceci, à son tour, élimine le gaspillage d'énergie pendant le transfert de données. La dissipation d'énergie est encore minimisée à l'aide de cellules flash qui peuvent fonctionner avec une dissipation de puissance active ultra-faible et presque aucune dissipation d'énergie en mode veille.
Un exemple de cette approche est la technologie memBrain™ de Silicon Storage Technology (SST), une société de Microchip Technology. Basé sur le SuperFlash ® de SST technologie de mémoire, la solution comprend une architecture informatique en mémoire qui permet d'effectuer des calculs là où les poids du modèle d'inférence sont stockés. Cela élimine le goulot d'étranglement de la mémoire dans le calcul MAC car il n'y a pas de mouvement de données pour les poids - seules les données d'entrée doivent passer d'un capteur d'entrée tel qu'une caméra ou un microphone à la matrice de mémoire.
Ce concept de mémoire est basé sur deux principes fondamentaux :(a) la réponse de courant électrique analogique d'un transistor est basée sur sa tension de seuil (Vt) et les données d'entrée, et (b) la loi actuelle de Kirchhoff, qui stipule que la somme algébrique des courants dans un réseau de conducteurs se réunissant en un point est nul.
Il est également important de comprendre la cellule binaire fondamentale de la mémoire non volatile (NVM) qui est utilisée dans cette architecture de mémoire à plusieurs niveaux. Le schéma ci-dessous (Figure 4) est une coupe transversale de deux ESF3 (Embedded SuperFlash 3 rd génération) bitcells avec Erase Gate (EG) et Source Line (SL) partagés. Chaque bitcell a cinq terminaux :Control Gate (CG), Work Line (WL), Erase Gate (EG), Source Line (SL) et Bitline (BL). L'opération d'effacement sur la bitcell se fait en appliquant une haute tension sur EG. L'opération de programmation est effectuée en appliquant des signaux de polarisation haute/basse tension sur WL, CG, BL et SL. L'opération de lecture est effectuée en appliquant des signaux de polarisation basse tension sur WL, CG, BL et SL.
Figure 4 :Cellule SuperFlash ESF3. (Source :Microchip Technology)
Avec cette architecture mémoire, l'utilisateur peut programmer les bitcells mémoire à différents niveaux de Vt par une opération de programmation fine. La technologie de mémoire utilise un algorithme intelligent pour régler la grille flottante (FG) Vt de la cellule mémoire afin d'obtenir une certaine réponse de courant électrique à partir d'une tension d'entrée. Selon les exigences de l'application finale, les cellules peuvent être programmées dans une région de fonctionnement linéaire ou sous-seuil.
La figure 5 illustre la capacité de stockage et de lecture de plusieurs niveaux sur la cellule mémoire. Disons que nous essayons de stocker une valeur entière de 2 bits dans une cellule de mémoire. Pour ce scénario, nous devons programmer chaque cellule dans une matrice mémoire avec l'une des quatre valeurs possibles des valeurs entières de 2 bits (00, 01, 10, 11). Les quatre courbes ci-dessous sont une courbe IV pour chacun des quatre états possibles, et la réponse du courant électrique de la cellule dépendrait de la tension appliquée sur CG.
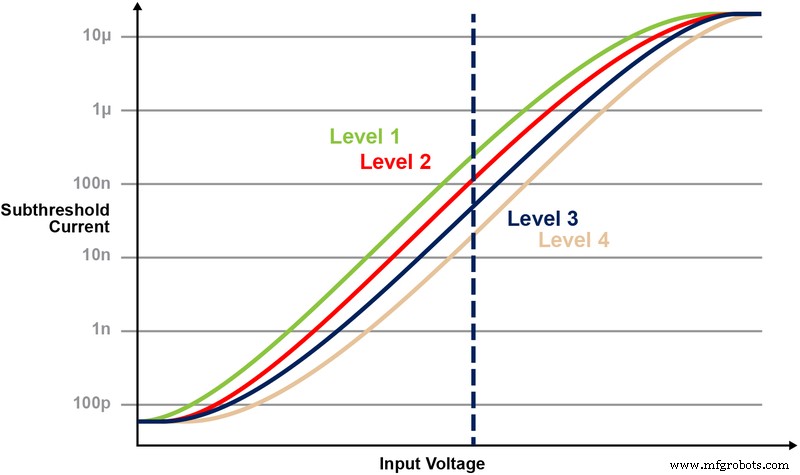
Figure 5 :Programmation des niveaux de Vt dans la cellule ESF3. (Source :Microchip Technology)
Opération de multiplication-accumulation avec l'informatique en mémoire
Chaque cellule ESF3 peut être modélisée comme une conductance variable (gm ). La conductance d'une cellule ESF3 dépend de la grille flottante Vt de la cellule programmée. Un poids d'un modèle entraîné est programmé en tant que grille flottante Vt de la cellule mémoire, par conséquent, gm de la cellule représente un poids du modèle entraîné. Lorsqu'une tension d'entrée (Vin) est appliquée sur la cellule ESF3, le courant de sortie (Iout) serait donné par l'équation Iout =gm * Vin, qui est l'opération de multiplication entre la tension d'entrée et le poids stocké sur la cellule ESF3.
La figure 6 ci-dessous illustre le concept de multiplication-accumulation dans une configuration de petit réseau (réseau 2x2) dans lequel l'opération d'accumulation est effectuée en ajoutant des courants de sortie (à partir des cellules (à partir de l'opération de multiplication) connectées à la même colonne (par exemple I1 =I11 + I21). Selon l'application, la fonction d'activation peut être effectuée dans le bloc ADC ou elle peut être effectuée avec une implémentation numérique en dehors du bloc mémoire.
cliquez pour agrandir l'image
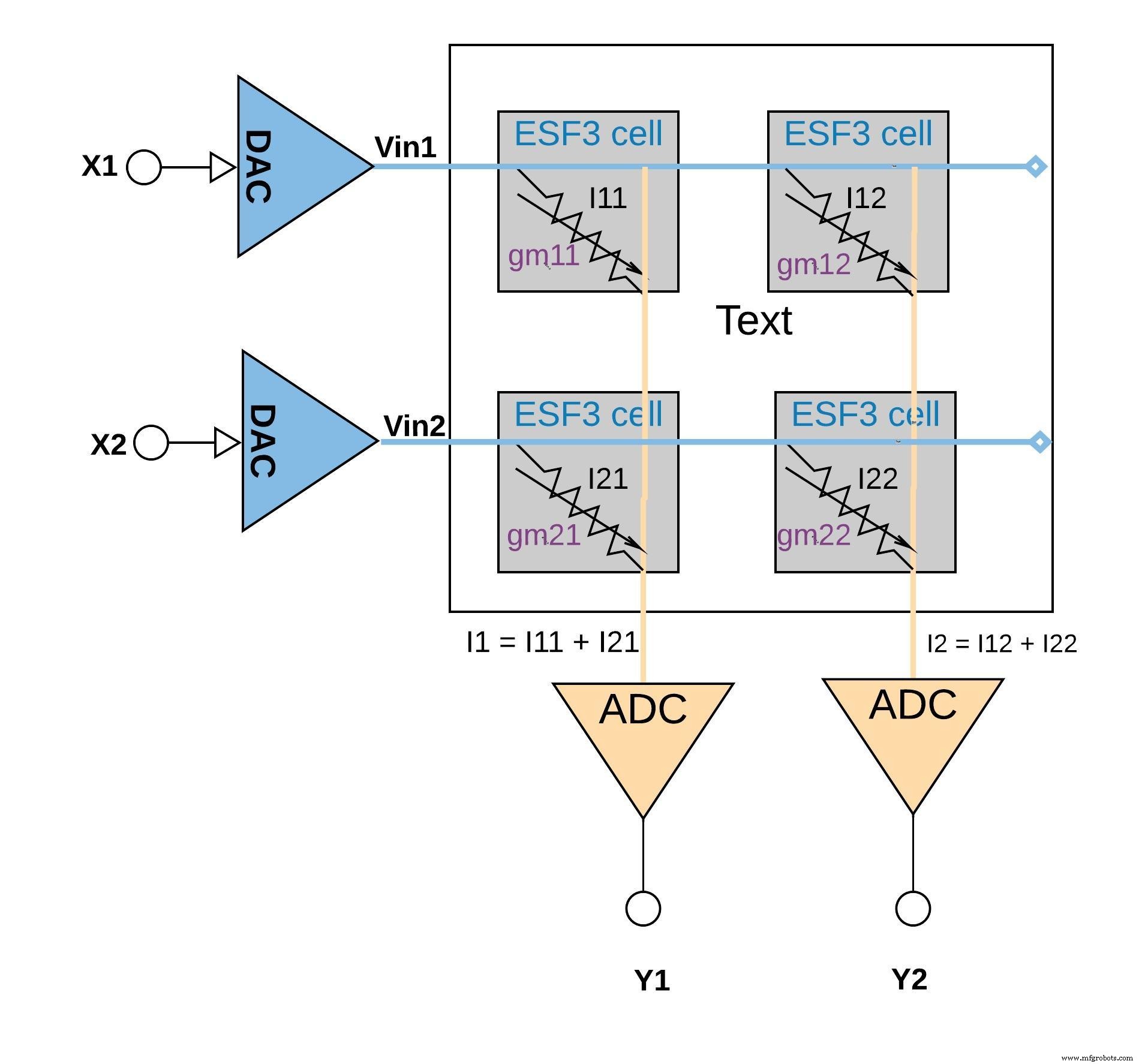
Figure 6 :opération de multiplication-accumulation avec la matrice ESF3 (2×2). (Source :Microchip Technology)
Illustrer davantage le concept à un niveau supérieur ; les poids individuels d'un modèle entraîné sont programmés en tant que grille flottante Vt de la cellule mémoire, de sorte que tous les poids de chaque couche du modèle entraîné (disons une couche entièrement connectée) peuvent être programmés sur une matrice mémoire qui ressemble physiquement à une matrice de poids , comme illustré à la Figure 7.
cliquez pour agrandir l'image
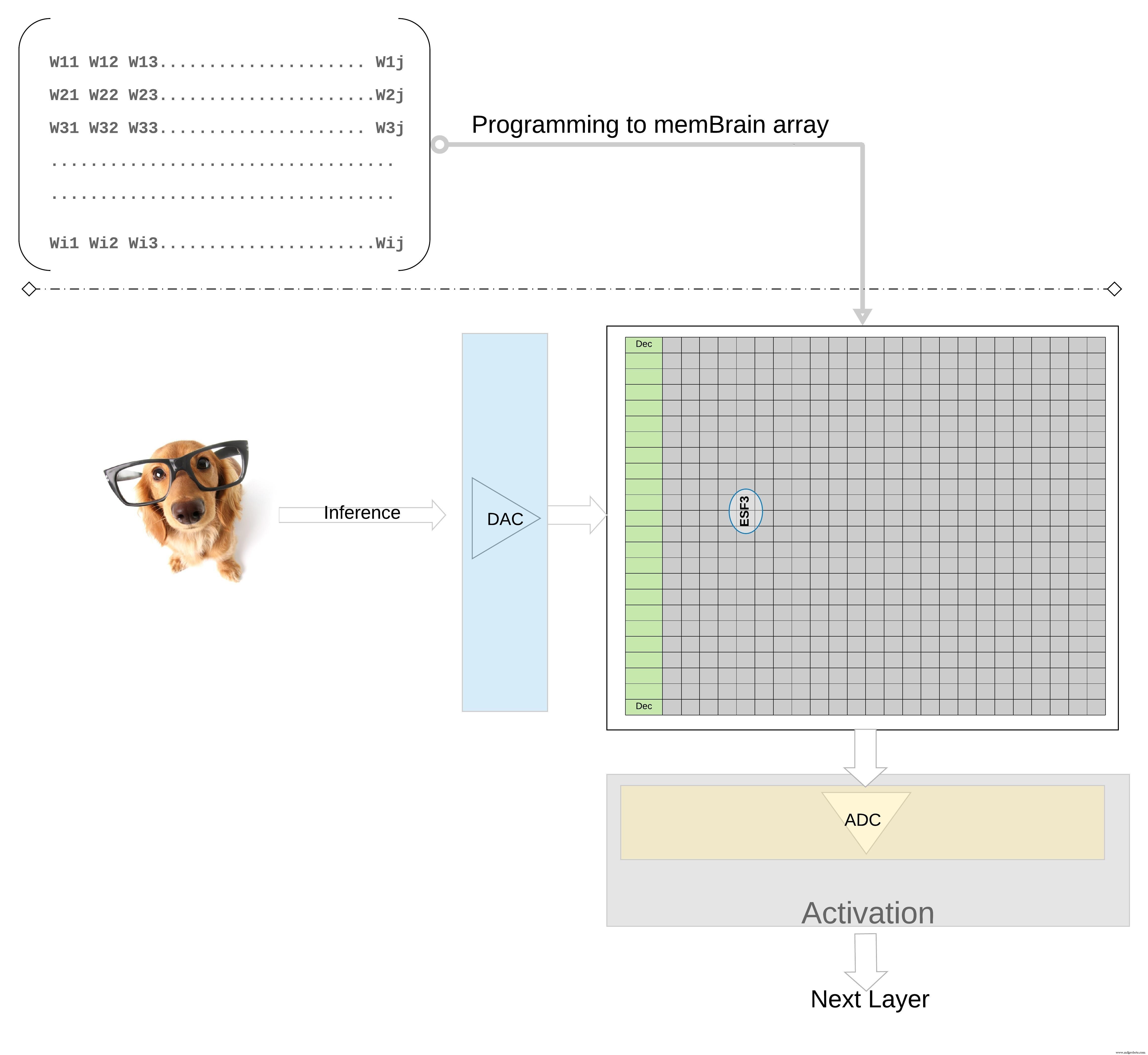
Figure 7 :Matrice de mémoire de matrice de poids pour l'inférence. (Source :Microchip Technology)
Pour une opération d'inférence, une entrée numérique, disons des pixels d'image, est d'abord convertie en un signal analogique à l'aide d'un convertisseur numérique-analogique (DAC) et appliquée à la matrice mémoire. Le réseau exécute ensuite des milliers d'opérations MAC en parallèle pour le vecteur d'entrée donné et produit une sortie qui peut aller à l'étape d'activation des neurones respectifs, qui peuvent ensuite être reconvertis en signaux numériques à l'aide d'un convertisseur analogique-numérique (ADC). Les signaux numériques sont ensuite traités pour être mis en commun avant de passer à la couche suivante.
Ce type d'architecture mémoire est très modulaire et flexible. De nombreuses tuiles memBrain peuvent être cousues ensemble pour créer une variété de grands modèles avec un mélange de matrices de poids et de neurones, comme illustré à la Figure 8. Dans cet exemple, une configuration de tuile 3 × 4 est cousue avec un tissu analogique et numérique entre le tuiles, et les données peuvent être déplacées d'une tuile à l'autre via un bus partagé.
cliquez pour agrandir l'image
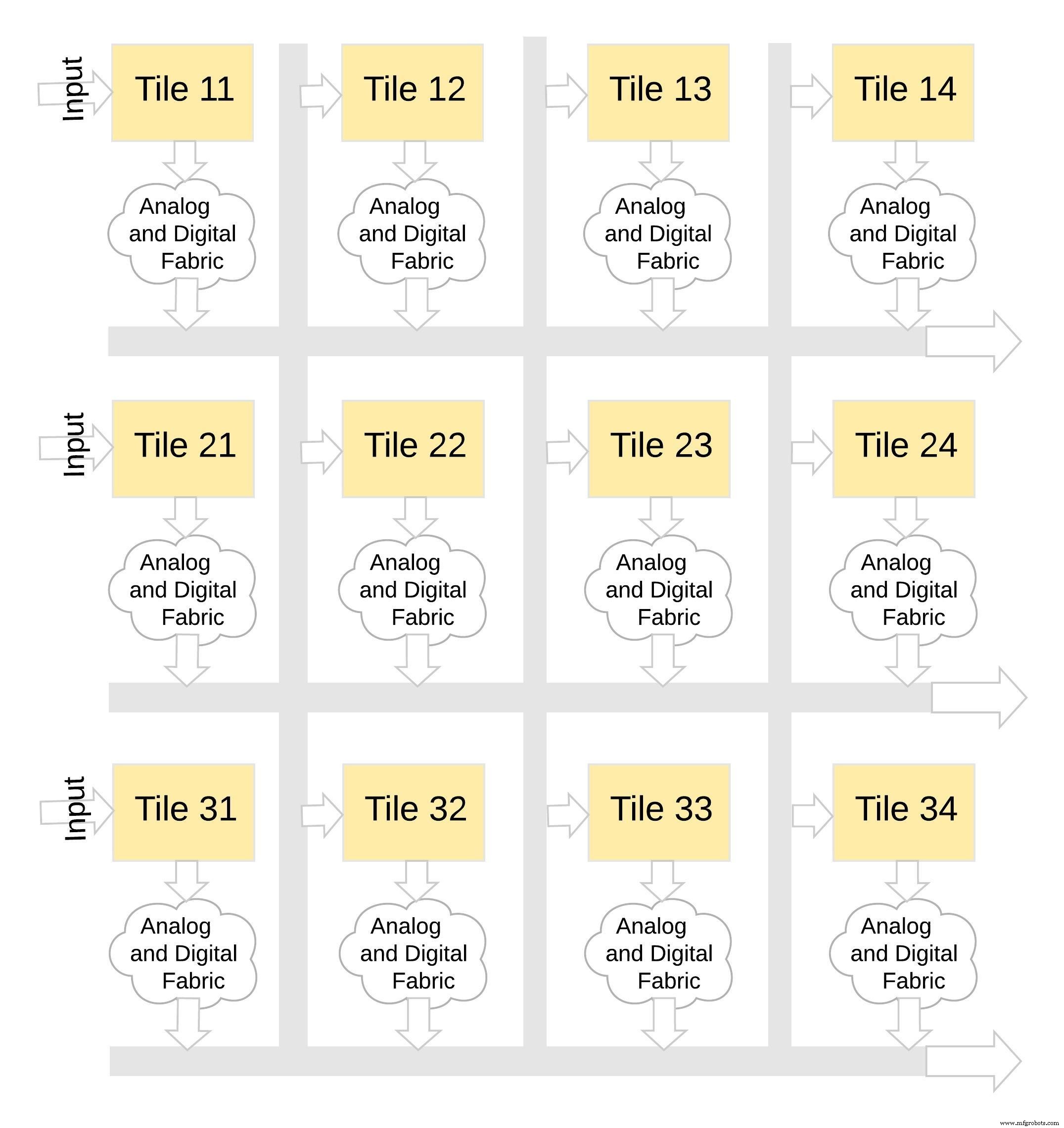
Figure 8 :memBrain™ est modulaire. (Source :Microchip Technology)
Jusqu'à présent, nous avons principalement discuté de la mise en œuvre sur silicium de cette architecture. La disponibilité d'un kit de développement logiciel (SDK) (Figure 9) facilite le déploiement de la solution. En plus du silicium, le SDK facilite le déploiement du moteur d'inférence.
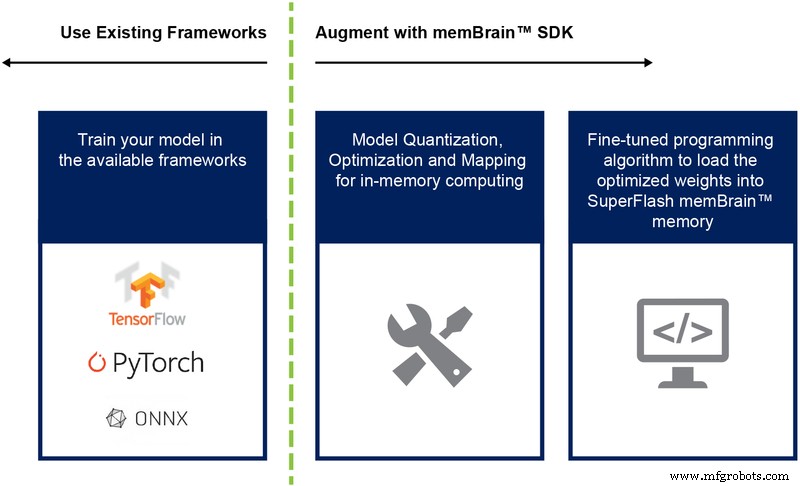
Figure 9 :flux du SDK memBrain™. (Source :Microchip Technology)
Le flux du SDK est indépendant du cadre de formation. L'utilisateur peut créer un modèle de réseau neuronal dans l'un des frameworks disponibles tels que TensorFlow, PyTorch ou autres, en utilisant le calcul en virgule flottante comme il le souhaite. Une fois qu'un modèle est créé, le SDK aide à quantifier le modèle de réseau neuronal formé et à le mapper sur la matrice mémoire où la multiplication vecteur-matrice peut être effectuée avec le vecteur d'entrée provenant d'un capteur ou d'un ordinateur.
Conclusion
Les avantages de cette approche de mémoire à plusieurs niveaux avec ses capacités de calcul en mémoire incluent :
- Puissance extrêmement faible : La technologie est conçue pour les applications à faible consommation. L'avantage de puissance de premier niveau vient du fait que la solution est un calcul en mémoire, de sorte que l'énergie n'est pas gaspillée dans le transfert de données et de poids depuis la SRAM/DRAM pendant le calcul. Le deuxième avantage énergétique provient du fait que les cellules flash fonctionnent en mode sous-seuil avec des valeurs de courant très faibles, de sorte que la dissipation de puissance active est très faible. Le troisième avantage est qu'il n'y a presque pas de dissipation d'énergie en mode veille, car la cellule de mémoire non volatile n'a pas besoin d'alimentation pour conserver les données pour un appareil toujours allumé. L'approche est également bien adaptée pour exploiter la rareté des poids et des données d'entrée. La mémoire bitcell ne s'active pas si les données d'entrée ou le poids sont nuls.
- Encombrement réduit du package : La technologie utilise une architecture de cellule à grille divisée (1,5T) alors qu'une cellule SRAM dans une implémentation numérique est basée sur une architecture 6T. De plus, la cellule est une bitcell beaucoup plus petite par rapport à une cellule SRAM 6T. De plus, une cellule de cellule peut stocker la valeur entière de 4 bits, contrairement à une cellule SRAM qui a besoin de 4*6 =24 transistors pour le faire. Cela offre une empreinte sur puce considérablement plus petite.
- Coût de développement réduit : En raison des goulots d'étranglement des performances de la mémoire et des limitations de l'architecture von Neumann, de nombreux appareils spécialement conçus (tels que Jetsen de Nvidia ou TPU de Google) ont tendance à utiliser des géométries plus petites pour gagner en performances par watt, ce qui est un moyen coûteux de résoudre le défi informatique de pointe. Avec l'approche de la mémoire à plusieurs niveaux utilisant des méthodes de calcul analogiques sur mémoire, le calcul est effectué sur puce dans des cellules flash, ce qui permet d'utiliser des géométries plus grandes et de réduire les coûts de masque et les délais.
Les applications Edge computing sont très prometteuses. Pourtant, il y a des problèmes de puissance et de coûts à résoudre avant que l'informatique de périphérie ne puisse décoller. Un obstacle majeur peut être supprimé en utilisant une approche mémoire qui effectue des calculs sur puce dans des cellules flash. Cette approche tire parti d'une solution de technologie de mémoire à plusieurs niveaux éprouvée et de facto de type standard, optimisée pour les applications d'apprentissage automatique.
Embarqué
- Comment Edge Computing pourrait bénéficier à l'informatique d'entreprise
- Comment le cloud computing peut-il profiter au personnel informatique ?
- Une introduction à l'informatique de pointe et des exemples de cas d'utilisation
- Edge computing :5 pièges potentiels
- Comment les données IIoT peuvent améliorer la rentabilité de la production au plus juste
- Plus près de la périphérie :comment l'informatique de pointe stimulera l'industrie 4.0
- Comment une panne de courant peut endommager vos alimentations
- 6 bonnes raisons d'adopter Edge Computing
- Edge Computing et 5G font évoluer l'entreprise