


Comment les chaînes de traitement du signal étendues font que les assistants vocaux « fonctionnent »
Les haut-parleurs intelligents et les appareils à commande vocale sont de plus en plus populaires, avec des assistants vocaux tels qu'Alexa d'Amazon et l'assistant de Google qui comprennent de mieux en mieux nos demandes.
L'un des principaux attraits de ce type d'interface est qu'elle « fonctionne » :il n'y a pas d'interface utilisateur à apprendre, et nous pouvons de plus en plus parler à un gadget dans un langage naturel comme s'il s'agissait d'une personne, et obtenir une réponse utile. Mais pour atteindre cette capacité, il y a une énorme quantité de traitements sophistiqués en cours.
Dans cet article, nous examinerons l'architecture des solutions à commande vocale et discuterons de ce qui se passe sous le capot, ainsi que du matériel et des logiciels requis.
Flux de signaux et architecture
Bien qu'il existe de nombreux types d'appareils à commande vocale, les principes de base et le flux de signaux sont similaires. Considérons un haut-parleur intelligent, tel que l'Echo d'Amazon, et examinons les principaux sous-systèmes et modules de traitement du signal impliqués.
La figure 1 montre la chaîne de signal globale dans un haut-parleur intelligent.
cliquez pour agrandir l'image
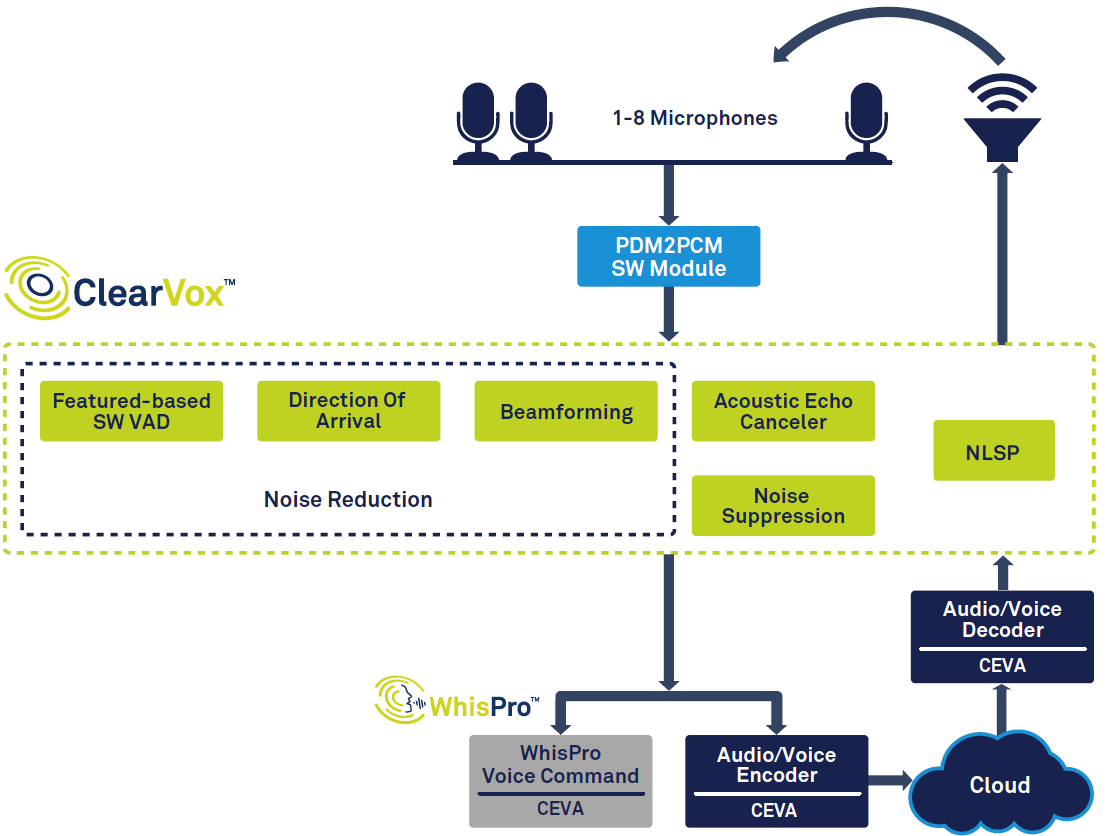
Figure 1 :Chaîne de signaux pour assistant vocal, basée sur ClearVox et WhisPro de CEVA. (Source :CEVA)
En partant de la gauche du diagramme, vous pouvez voir qu'une fois qu'une voix est détectée à l'aide de la détection d'activité vocale (VAD), elle est numérisée et passe par plusieurs étapes de traitement du signal pour améliorer la clarté de la voix à partir de la voix du locuteur principal souhaité. sens d'arrivée. Les données vocales numérisées et traitées sont ensuite transmises au traitement vocal principal, qui peut avoir lieu en partie à la périphérie (sur l'appareil) et en partie dans le cloud. Enfin, une réponse, si nécessaire, est créée et émise par le locuteur, ce qui nécessite un décodage et une conversion numérique-analogique.
Pour d'autres applications, il peut y avoir des différences et des priorités variables - par exemple, une interface vocale embarquée devrait être optimisée pour gérer le bruit de fond typique dans les voitures. Il existe également une tendance générale à la baisse de la consommation d'énergie et à la réduction des coûts, stimulée par la demande d'appareils plus petits tels que les écouteurs intra-auriculaires et les appareils électroménagers à bas prix.
Traitement du signal frontal
Une fois qu'une voix a été détectée et numérisée, plusieurs tâches de traitement du signal sont nécessaires. En plus du bruit externe, nous devons également considérer les sons générés par l'appareil d'écoute, par exemple un haut-parleur intelligent émettant de la musique ou une conversation avec une personne parlant à l'autre bout du fil. Pour supprimer ces sons, l'appareil utilise l'annulation de l'écho acoustique (AEC), afin que l'utilisateur puisse intervenir et interrompre un haut-parleur intelligent, même lorsqu'il joue déjà de la musique ou parle. Une fois ces échos supprimés, des algorithmes de suppression de bruit sont ensuite utilisés pour nettoyer le bruit externe.
Bien qu'il existe de nombreuses applications différentes, nous pouvons les généraliser en deux groupes pour les appareils à commande vocale :la prise de voix en champ proche et en champ lointain. Les appareils en champ proche, tels que les casques, les écouteurs, les appareils auditifs et les appareils portables, sont tenus ou portés près de la bouche de l'utilisateur, tandis que les appareils en champ lointain tels que les haut-parleurs intelligents et les téléviseurs sont conçus pour écouter la voix d'un utilisateur depuis l'autre bout d'une pièce.
Les appareils en champ proche utilisent généralement un ou deux microphones, mais les appareils en champ lointain en utilisent souvent entre trois et huit. La raison en est que l'appareil en champ lointain est confronté à plus de défis que le champ proche :à mesure que l'utilisateur s'éloigne, sa voix atteignant les microphones devient progressivement plus faible, tandis que le bruit de fond reste au même niveau. Dans le même temps, l'appareil doit également séparer le signal vocal direct des réflexions sur les murs et autres surfaces, c'est-à-dire la réverbération.
Pour gérer ces problèmes, les appareils à champ lointain utilisent une technique appelée formation de faisceau. Celui-ci utilise plusieurs microphones et calcule la direction de la source sonore en fonction des différences de temps entre les signaux sonores arrivant à chaque microphone. Cela permet à l'appareil d'ignorer les reflets et autres sons, et d'écouter simplement l'utilisateur, ainsi que de suivre ses mouvements et de zoomer sur la bonne voix lorsque plusieurs personnes parlent.
Pour les haut-parleurs intelligents, une autre tâche clé consiste à reconnaître le mot « déclencheur », tel que « Alexa ». Comme le locuteur écoute toujours, cette reconnaissance de déclencheur soulève des problèmes de confidentialité - si l'audio de l'utilisateur est toujours téléchargé sur le cloud, même s'il ne prononce pas le mot déclencheur, se sentent-ils à l'aise avec Amazon ou Google pour entendre toutes leurs conversations ? Au lieu de cela, il peut être préférable de gérer la reconnaissance du déclencheur, ainsi que de nombreuses commandes populaires telles que « augmenter le volume » localement sur le haut-parleur intelligent lui-même, l'audio n'étant envoyé au cloud qu'une fois que l'utilisateur a lancé une commande plus complexe.
Enfin, l'échantillon de voix propre doit être encodé avant d'être finalement envoyé au back-end cloud pour un traitement ultérieur.
Solutions spécialisées
Il ressort clairement de la description ci-dessus que le traitement vocal frontal doit être capable de gérer de nombreuses tâches. Il doit le faire rapidement et avec précision, et pour les appareils alimentés par batterie, la consommation d'énergie doit être réduite au minimum, même lorsque l'appareil est toujours à l'écoute d'un mot de déclenchement.
Pour répondre à ces demandes, il est peu probable que les processeurs de signaux numériques (DSP) ou les microprocesseurs à usage général soient à la hauteur - en termes de coût, de performances de traitement, de taille et de consommation d'énergie. Au lieu de cela, une meilleure solution sera probablement un DSP spécifique à l'application, avec des fonctions de traitement audio dédiées et un logiciel optimisé. Le choix d'une solution matérielle/logicielle déjà optimisée pour les tâches de saisie vocale réduira également les coûts de développement et le temps de mise sur le marché de manière substantielle, ainsi que les coûts globaux.
Par exemple, ClearVox de CEVA est une suite logicielle d'algorithmes de traitement d'entrée vocale, qui peut faire face à différents scénarios acoustiques et configurations de microphone, y compris la direction d'arrivée de la voix du locuteur, la formation de faisceaux multi-micros, la suppression du bruit et l'annulation de l'écho acoustique. ClearVox est optimisé pour fonctionner efficacement sur les DSP audio CEVA, afin de fournir une solution économique et à faible consommation d'énergie.
En plus du traitement vocal, le périphérique de périphérie aura besoin de la capacité de gérer la détection de mot de déclenchement. Une solution spécialisée, telle que WhisPro de CEVA, est un excellent moyen d'obtenir la précision et la faible consommation d'énergie nécessaires (voir Figure 2). WhisPro est un progiciel de reconnaissance vocale basé sur un réseau neuronal, disponible exclusivement pour les DSP de CEVA, qui permet aux OEM d'ajouter l'activation vocale à leurs produits à commande vocale. Il peut gérer l'écoute permanente requise, tandis qu'un processeur principal reste en veille jusqu'à ce que vous en ayez besoin, réduisant ainsi considérablement la consommation d'énergie globale du système.
cliquez pour agrandir l'image
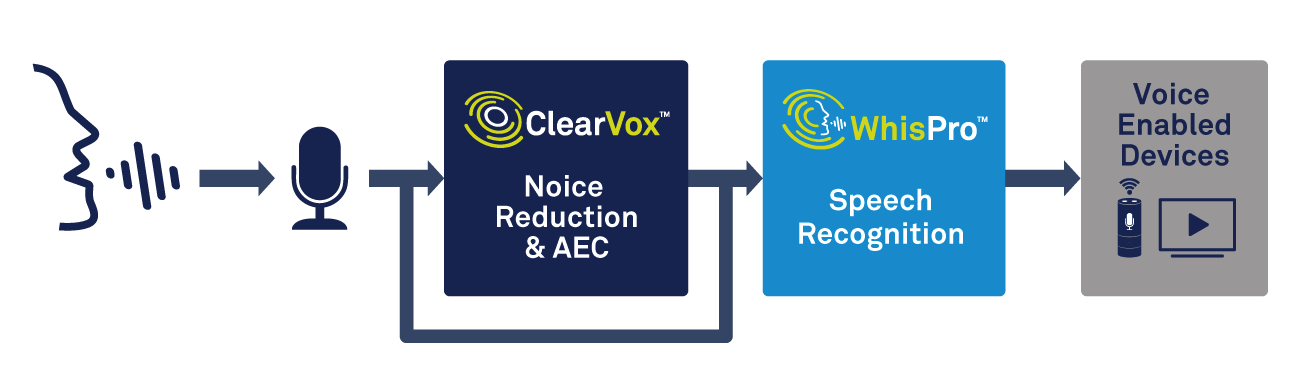
Figure 2 :utilisation du traitement vocal et de la reconnaissance vocale pour l'activation vocale. (Source :CEVA)
WhisPro peut atteindre un taux de reconnaissance de plus de 95 % et peut prendre en charge plusieurs phrases déclencheurs, ainsi que des mots déclencheurs personnalisés. Comme peut en témoigner toute personne ayant utilisé un haut-parleur intelligent, le faire réagir de manière fiable au mot de réveil - même dans un environnement bruyant - peut parfois être une expérience frustrante. Bien utiliser cette fonctionnalité peut faire une énorme différence dans la façon dont les consommateurs perçoivent la qualité d'un produit à commande vocale.
Reconnaissance vocale :locale ou cloud
Une fois que la voix a été numérisée et traitée, nous avons besoin d'une sorte de capacité de reconnaissance automatique de la parole (ASR). Il existe un large éventail de technologies ASR, allant de la simple détection de mots clés qui oblige un utilisateur à dire des mots clés spécifiques, jusqu'au traitement sophistiqué du langage naturel (NLP), où un utilisateur peut parler normalement comme s'il s'adressait à une autre personne.
La détection de mots-clés a de nombreuses utilisations, même si son vocabulaire est extrêmement limité. Par exemple, un simple appareil domestique intelligent tel qu'un interrupteur d'éclairage ou un thermostat peut simplement répondre à quelques commandes, telles que « marche », « arrêt », « plus lumineux », « gradateur » et ainsi de suite. Ce niveau d'ASR peut facilement être géré localement, à la périphérie, sans connexion Internet, ce qui réduit les coûts, garantit une réponse rapide et évite les problèmes de sécurité et de confidentialité.
Un autre exemple serait que de nombreux smartphones Android peuvent être invités à prendre une photo en disant « fromage » ou « sourire », alors que l'envoi de la commande au cloud prendrait tout simplement trop de temps. Et cela en supposant qu'une connexion Internet soit disponible, ce qui ne sera pas toujours le cas pour un appareil tel qu'une montre connectée ou un appareil auditif.
D'autre part, de nombreuses applications nécessitent la PNL. Si vous souhaitez demander à votre haut-parleur Echo la météo ou vous trouver un hôtel pour ce soir, vous pouvez formuler votre question de différentes manières. L'appareil doit être capable de comprendre les nuances et les expressions familières possibles dans la commande, et de déterminer de manière fiable ce qui a été demandé. En termes simples, il doit être capable de convertir la parole en sens, plutôt que simplement la parole en texte.
Pour prendre l'exemple de notre demande d'hôtel, il existe une vaste gamme de facteurs possibles sur lesquels vous pourriez vouloir poser des questions :prix, emplacement, avis et bien d'autres. Le système NLP doit interpréter toute cette complexité, ainsi que les nombreuses manières différentes dont une question peut être formulée, et un manque de clarté de la demande - dire « trouvez-moi un bon rapport qualité-prix, hôtel central » signifiera différentes choses pour différentes gens. Pour obtenir des résultats précis, l'appareil doit également tenir compte du contexte de la question et reconnaître lorsque l'utilisateur pose des questions de suivi connectées ou demande plusieurs informations au sein d'une même requête.
Cela peut prendre une énorme quantité de traitement, généralement en utilisant l'intelligence artificielle (IA) et les réseaux de neurones, ce qui n'est généralement pas pratique pour le traitement uniquement à la périphérie. Un appareil bon marché avec un processeur intégré n'aura pas assez de puissance pour gérer les tâches requises. Dans ce cas, la bonne option consiste à envoyer la parole numérisée pour traitement dans le cloud. Là, il peut être interprété et une réponse appropriée renvoyée à l'appareil à commande vocale.
Vous pouvez voir qu'il existe des compromis entre le traitement en périphérie sur l'appareil et le traitement à distance dans le cloud. Tout gérer localement peut être plus rapide et ne dépend pas d'une connexion Internet, mais aura du mal à traiter un plus large éventail de questions et de récupération d'informations. Cela signifie que pour un appareil à usage général, tel qu'un haut-parleur intelligent dans la maison, il est nécessaire de transférer au moins une partie du traitement vers le cloud.
Pour remédier aux inconvénients du traitement en nuage, des développements sont en cours dans les capacités des processeurs locaux, et dans un avenir proche, nous pouvons nous attendre à de grandes améliorations de la PNL et de l'IA dans les appareils de périphérie. De nouvelles techniques réduisent la quantité de mémoire requise, et les processeurs continuent de devenir plus rapides et moins gourmands en énergie.
Par exemple, la famille NeuPro de CEVA de processeurs d'IA basse consommation offre des capacités sophistiquées pour la périphérie. S'appuyant sur l'expérience de CEVA dans les réseaux de neurones pour la vision par ordinateur, cette famille offre une solution flexible et évolutive pour le traitement de la parole sur l'appareil.
Conclusion
Les interfaces à commande vocale deviennent rapidement une partie importante de notre vie quotidienne et seront ajoutées à de plus en plus de produits dans un avenir proche. Les améliorations sont motivées par de meilleures capacités de traitement du signal et de reconnaissance vocale, ainsi que par des ressources informatiques plus puissantes, à la fois localement et dans le cloud.
Pour répondre aux exigences des OEM, les composants utilisés pour le traitement audio et la reconnaissance vocale doivent relever des défis difficiles, en termes de performances, de coût et de puissance. Pour de nombreux concepteurs, les solutions spécialement optimisées pour les tâches à accomplir peuvent s'avérer la meilleure approche :répondre aux demandes des clients finaux et réduire les délais de mise sur le marché.
Quelle que soit la technologie sur laquelle elles reposent, les interfaces vocales deviendront plus précises et plus faciles à communiquer dans le langage de tous les jours, tandis que leurs coûts en baisse les rendront plus attrayantes pour les fabricants. Ce sera un voyage intéressant pour voir à quoi ils serviront ensuite.
Embarqué
- Les technologies améliorées accéléreront l'acceptation des assistants vocaux
- Comment fabriquer de la fibre de verre
- Comment tirer le meilleur parti de votre chaîne d'approvisionnement dès maintenant
- Comment fonctionnent les systèmes SCADA ?
- Comment faire un prototype
- Comment fonctionnent les sécheurs d'air ?
- Comment fabriquer l'électronique de demain à l'aide de graphène imprimé par jet d'encre
- Comment fonctionnent les freins électriques
- Comment faire fonctionner un programme de sécurité complet