


Python RegEx :re.match(), re.search(), re.findall() avec l'exemple
Qu'est-ce que l'expression régulière en Python ?
Une expression régulière (RE) dans un langage de programmation est une chaîne de texte spéciale utilisée pour décrire un modèle de recherche. Il est extrêmement utile pour extraire des informations à partir de textes tels que du code, des fichiers, des journaux, des feuilles de calcul ou même des documents.
Lors de l'utilisation de l'expression régulière Python, la première chose à faire est de reconnaître que tout est essentiellement un caractère, et nous écrivons des modèles pour correspondre à une séquence spécifique de caractères également appelée chaîne. Les lettres ascii ou latines sont celles qui se trouvent sur vos claviers et Unicode est utilisé pour faire correspondre le texte étranger. Il comprend les chiffres et la ponctuation et tous les caractères spéciaux comme $#@!%, etc.
Dans ce tutoriel Python RegEx, nous allons apprendre-
- Syntaxe des expressions régulières
- Exemple d'expression w+ et ^
- Exemple d'expression \s dans la fonction re.split
- Utilisation des méthodes d'expression régulière
- Utiliser re.match()
- Rechercher un modèle dans le texte (re.search())
- Utiliser re.findall pour le texte
- Drapeaux Python
- Exemple de re.M ou Multiline Flags
Par exemple, une expression régulière Python pourrait indiquer à un programme de rechercher un texte spécifique dans la chaîne, puis d'imprimer le résultat en conséquence. L'expression peut inclure
- Correspondance de texte
- Répétition
- Branchement
- Motif-composition etc.
L'expression régulière ou RegEx en Python est désignée par RE (les RE, les regex ou le modèle de regex) sont importés via re module . Python prend en charge les expressions régulières via des bibliothèques. RegEx en Python prend en charge diverses choses comme les modificateurs, les identificateurs et les espaces blancs .
| Identifiants | Modificateurs | Caractères d'espace blanc | Évasion requise |
|---|---|---|---|
| \d=n'importe quel nombre (un chiffre) | \d représente un chiffre.Ex :\d{1,5} il déclarera un chiffre entre 1,5 comme 424 444 545 etc. | \n =nouvelle ligne | . + * ? [] $ ^ () {} | \ |
| \D=tout sauf un nombre (un non-chiffre) | + =correspond à 1 ou plus | \s=espace | |
| \s =espace (tabulation, espace, saut de ligne etc.) | ? =correspond à 0 ou 1 | \t =tab | |
| \S=tout sauf un espace | * =0 ou plus | \e =échapper | |
| \w =lettres (Reconnaître les caractères alphanumériques, y compris "_") | $ correspond à la fin d'une chaîne | \r =retour chariot | |
| \W =tout sauf des lettres ( Correspond à un caractère non alphanumérique à l'exception de "_") | ^ correspond au début d'une chaîne | \f=saut de formulaire | |
| . =tout sauf des lettres (points) | | correspond soit à x/y | —————– | |
| \b =n'importe quel caractère sauf pour le retour à la ligne | [] =plage ou "variance" | —————- | |
| \. | {x} =cette quantité de code précédent | —————– |
Syntaxe des expressions régulières (RE)
import re
- Module "re" inclus avec Python principalement utilisé pour la recherche et la manipulation de chaînes
- Également fréquemment utilisé pour le "scraping" de pages Web (extraction d'une grande quantité de données à partir de sites Web)
Nous allons commencer le didacticiel sur les expressions avec cet exercice simple en utilisant les expressions (w+) et (^).
Exemple d'expression w+ et ^
- "^" : Cette expression correspond au début d'une chaîne
- "w+ " :cette expression correspond au caractère alphanumérique de la chaîne
Ici, nous verrons un exemple Python RegEx de la façon dont nous pouvons utiliser les expressions w+ et ^ dans notre code. Nous couvrons la fonction re.findall() en Python, plus loin dans ce didacticiel, mais pendant un moment, nous nous concentrons simplement sur les expressions \w+ et \^.
Par exemple, pour notre chaîne "guru99, education is fun" si nous exécutons le code avec w+ et ^, cela donnera la sortie "guru99".
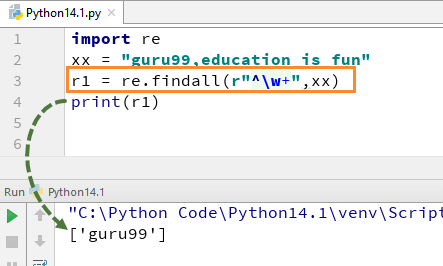
import re xx = "guru99,education is fun" r1 = re.findall(r"^\w+",xx) print(r1)
N'oubliez pas que si vous supprimez le signe + du w+, la sortie changera et ne donnera que le premier caractère de la première lettre, c'est-à-dire [g]
Exemple d'expression \s dans la fonction re.split
- "s" :cette expression est utilisée pour créer un espace dans la chaîne
Pour comprendre le fonctionnement de cette RegEx en Python, nous commençons par un simple exemple Python RegEx d'une fonction fractionnée. Dans l'exemple, nous avons divisé chaque mot en utilisant la fonction "re.split" et en même temps nous avons utilisé l'expression \s qui permet d'analyser chaque mot de la chaîne séparément.
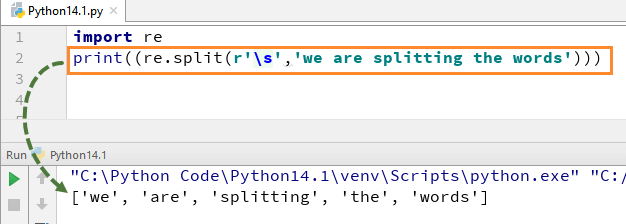
Lorsque vous exécutez ce code, il vous donnera la sortie ['we', 'are', 'splitting', 'the', 'words'].
Maintenant, voyons ce qui se passe si vous supprimez "\" de s. Il n'y a pas d'alphabet 's' dans la sortie, c'est parce que nous avons supprimé '\' de la chaîne, et il évalue "s" comme un caractère normal et divise ainsi les mots partout où il trouve "s" dans la chaîne.
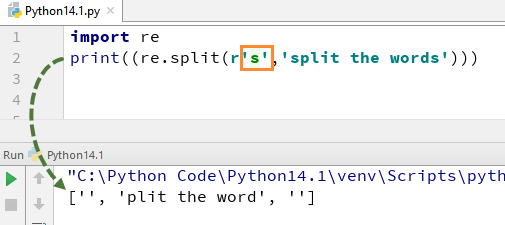
De même, il existe une série d'autres expressions régulières Python que vous pouvez utiliser de différentes manières dans Python comme \d,\D,$,\.,\b, etc.
Voici le code complet
import re xx = "guru99,education is fun" r1 = re.findall(r"^\w+", xx) print((re.split(r'\s','we are splitting the words'))) print((re.split(r's','split the words')))
Ensuite, nous verrons les types de méthodes utilisées avec les expressions régulières en Python.
Utilisation des méthodes d'expression régulière
Le package "re" fournit plusieurs méthodes pour effectuer des requêtes sur une chaîne d'entrée. Nous verrons les méthodes de re en Python :
- re.match()
- re.search()
- re.findall()
Remarque :Basé sur les expressions régulières, Python propose deux opérations primitives différentes. La méthode de correspondance recherche une correspondance uniquement au début de la chaîne tandis que la recherche recherche une correspondance n'importe où dans la chaîne.
re.match()
re.match() La fonction de re en Python recherchera le modèle d'expression régulière et renverra la première occurrence. La méthode Python RegEx Match recherche une correspondance uniquement au début de la chaîne. Ainsi, si une correspondance est trouvée dans la première ligne, elle renvoie l'objet match. Mais si une correspondance est trouvée dans une autre ligne, la fonction Python RegEx Match renvoie null.
Par exemple, considérez le code suivant de la fonction Python re.match(). L'expression "w+" et "\W" correspondra aux mots commençant par la lettre "g" et par la suite, tout ce qui ne commence pas par "g" n'est pas identifié. Pour vérifier la correspondance de chaque élément de la liste ou de la chaîne, nous exécutons la boucle for dans cet exemple Python re.match().
re.search() :trouver un modèle dans le texte
re.search() La fonction recherchera le modèle d'expression régulière et renverra la première occurrence. Contrairement à Python re.match(), il vérifiera toutes les lignes de la chaîne d'entrée. La fonction Python re.search() renvoie un objet match lorsque le modèle est trouvé et "null" si le modèle n'est pas trouvé
Comment utiliser la recherche() ?
Pour utiliser la fonction search(), vous devez d'abord importer le module Python re, puis exécuter le code. La fonction Python re.search() prend le "motif" et le "texte" à analyser à partir de notre chaîne principale
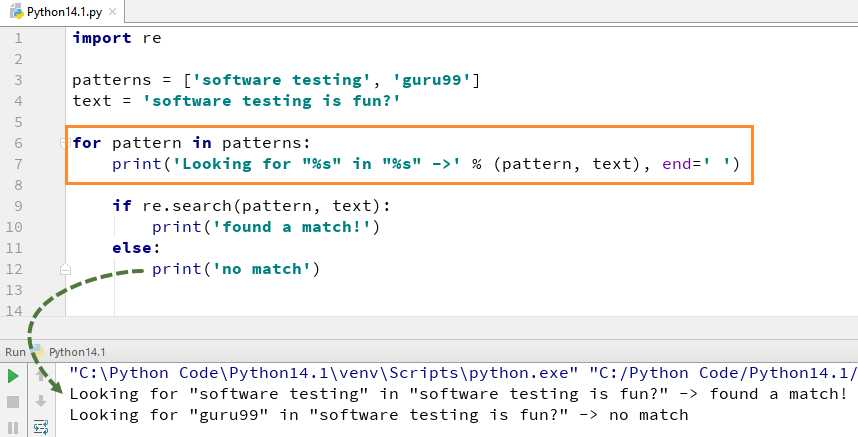
Par exemple, nous recherchons ici deux chaînes littérales "Software testing" "guru99", dans une chaîne de texte "Software Testing is fun". Pour les "tests de logiciels", nous avons trouvé la correspondance, donc il renvoie la sortie de Python re.search () Exemple comme "trouvé une correspondance", tandis que pour le mot "guru99", nous n'avons pas pu trouver dans la chaîne, donc il renvoie la sortie comme "Aucune correspondance ”.
re.findall()
trouvetout() module est utilisé pour rechercher "toutes" les occurrences qui correspondent à un modèle donné. En revanche, le module search() ne renverra que la première occurrence correspondant au modèle spécifié. findall() itérera sur toutes les lignes du fichier et renverra toutes les correspondances de motif qui ne se chevauchent pas en une seule étape.
Comment utiliser re.findall() en Python ?
Ici, nous avons une liste d'adresses e-mail, et nous voulons que toutes les adresses e-mail soient extraites de la liste, nous utilisons la méthode re.findall() en Python. Il trouvera toutes les adresses e-mail de la liste.
Voici le code complet pour Exemple de re.findall()
import re
list = ["guru99 get", "guru99 give", "guru Selenium"]
for element in list:
z = re.match("(g\w+)\W(g\w+)", element)
if z:
print((z.groups()))
patterns = ['software testing', 'guru99']
text = 'software testing is fun?'
for pattern in patterns:
print('Looking for "%s" in "%s" ->' % (pattern, text), end=' ')
if re.search(pattern, text):
print('found a match!')
else:
print('no match')
abc = 'guru99@google.com, careerguru99@hotmail.com, users@yahoomail.com'
emails = re.findall(r'[\w\.-]+@[\w\.-]+', abc)
for email in emails:
print(email) Drapeaux Python
De nombreuses méthodes Python Regex et fonctions Regex prennent un argument facultatif appelé Flags. Ces drapeaux peuvent modifier la signification du modèle Python Regex donné. Pour les comprendre, nous verrons un ou deux exemples de ces drapeaux.
Divers drapeaux utilisés dans Python incluent
| Syntaxe pour les drapeaux Regex | À quoi sert ce drapeau |
|---|---|
| [re.M] | Faire en sorte que début/fin considère chaque ligne |
| [re.I] | Il ignore la casse |
| [re.S] | Faire [ . ] |
| [re.U] | Faire en sorte que { \w,\W,\b,\B} respecte les règles Unicode |
| [re.L] | Faites en sorte que {\w,\W,\b,\B} suive les paramètres régionaux |
| [re.X] | Autoriser les commentaires dans Regex |
Exemple de re.M ou Multiline Flags
En multiligne, le caractère de modèle [^] correspond au premier caractère de la chaîne et au début de chaque ligne (suivant immédiatement après chaque saut de ligne). Alors que l'expression petit "w" est utilisée pour marquer l'espace avec des caractères. Lorsque vous exécutez le code, la première variable "k1" n'imprime que le caractère "g" pour le mot guru99, tandis que lorsque vous ajoutez un indicateur multiligne, il récupère les premiers caractères de tous les éléments de la chaîne.
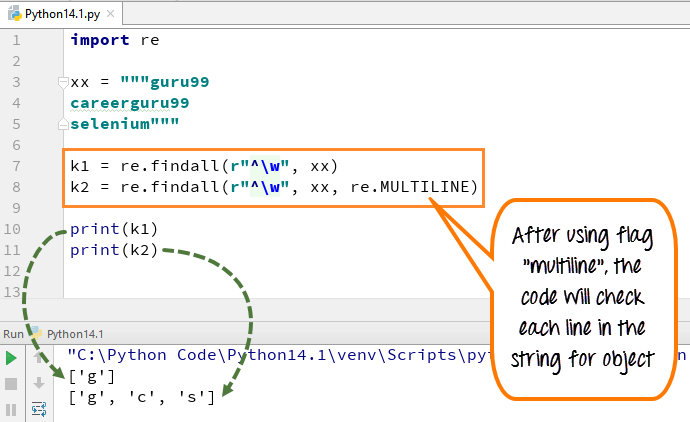
Voici le code
import re xx = """guru99 careerguru99 selenium""" k1 = re.findall(r"^\w", xx) k2 = re.findall(r"^\w", xx, re.MULTILINE) print(k1) print(k2)
- Nous avons déclaré la variable xx pour la chaîne ” guru99…. careerguru99….sélénium”
- Exécutez le code sans utiliser de drapeaux multilignes, il donne la sortie uniquement "g" à partir des lignes
- Exécutez le code avec le drapeau "multiline", lorsque vous imprimez "k2", il donne la sortie sous la forme "g", "c" et "s"
- Ainsi, la différence que nous pouvons voir après et avant l'ajout de plusieurs lignes dans l'exemple ci-dessus.
De même, vous pouvez également utiliser d'autres drapeaux Python comme re.U (Unicode), re.L (Suivre les paramètres régionaux), re.X (Autoriser les commentaires), etc.
Exemple Python 2
Les codes ci-dessus sont des exemples Python 3, si vous voulez exécuter en Python 2, veuillez considérer le code suivant.
# Example of w+ and ^ Expression
import re
xx = "guru99,education is fun"
r1 = re.findall(r"^\w+",xx)
print r1
# Example of \s expression in re.split function
import re
xx = "guru99,education is fun"
r1 = re.findall(r"^\w+", xx)
print (re.split(r'\s','we are splitting the words'))
print (re.split(r's','split the words'))
# Using re.findall for text
import re
list = ["guru99 get", "guru99 give", "guru Selenium"]
for element in list:
z = re.match("(g\w+)\W(g\w+)", element)
if z:
print(z.groups())
patterns = ['software testing', 'guru99']
text = 'software testing is fun?'
for pattern in patterns:
print 'Looking for "%s" in "%s" ->' % (pattern, text),
if re.search(pattern, text):
print 'found a match!'
else:
print 'no match'
abc = 'guru99@google.com, careerguru99@hotmail.com, users@yahoomail.com'
emails = re.findall(r'[\w\.-]+@[\w\.-]+', abc)
for email in emails:
print email
# Example of re.M or Multiline Flags
import re
xx = """guru99
careerguru99
selenium"""
k1 = re.findall(r"^\w", xx)
k2 = re.findall(r"^\w", xx, re.MULTILINE)
print k1
print k2
Résumé
Une expression régulière dans un langage de programmation est une chaîne de texte spéciale utilisée pour décrire un modèle de recherche. Il comprend des chiffres et des signes de ponctuation et tous les caractères spéciaux comme $#@!%, etc. L'expression peut inclure des littéraux
- Correspondance de texte
- Répétition
- Branchement
- Motif-composition etc.
En Python, une expression régulière est notée RE (les RE, les regex ou le modèle de regex) sont intégrés via le module Python re.
- Module "re" inclus avec Python principalement utilisé pour la recherche et la manipulation de chaînes
- Également fréquemment utilisé pour le "scraping" de pages Web (extraction d'une grande quantité de données à partir de sites Web)
- Les méthodes d'expression régulières incluent re.match(),re.search()&re.findall()
- Les autres méthodes de remplacement Python RegEx sont sub() et subn() qui sont utilisées pour remplacer les chaînes correspondantes dans re
- Drapeaux Python De nombreuses méthodes Python Regex et fonctions Regex prennent un argument facultatif appelé Flags
- Ce drapeau peut modifier la signification du modèle Regex donné
- Les différents drapeaux Python utilisés dans les méthodes Regex sont re.M, re.I, re.S, etc.
Python
- Python String strip() Fonction avec EXAMPLE
- Python String count() avec des EXEMPLES
- Python String format() Expliquer avec des EXEMPLES
- Longueur de la chaîne Python | Méthode len() Exemple
- Méthode Python String find() avec exemples
- Fonction Python round() avec EXEMPLES
- Fonction Python map() avec EXEMPLES
- Python Timeit() avec des exemples
- Compteur Python dans les collections avec exemple