


Note clé sur l'apprentissage automatique et ses quatre principaux types pour les débutants
Nul doute que le Big Data est un élément majeur du développement technologique futur. Cependant, l'apprentissage automatique (ML) et l'intelligence artificielle (IA) jouent tous deux un rôle important dans ce développement. La relation entre ces trois éléments est brièvement expliquée :les mégadonnées sont pour les matériaux, l'apprentissage automatique pour la méthode et l'intelligence artificielle pour les résultats.
Qu'est-ce que l'apprentissage automatique ?
L'apprentissage automatique (ML) est l'un des types d'intelligence artificielle (IA) dans lequel les algorithmes sont écrits de telle manière que le système a la capacité d'apprendre, de s'adapter et de s'améliorer automatiquement grâce à l'expérience sans être explicitement programmé .
Les algorithmes d'apprentissage automatique construisent un modèle exemplaire qui est basé sur le type de données qu'il est destiné à apprendre, ce type de données est appelé "données d'entraînement".
Types d'apprentissage automatique ?
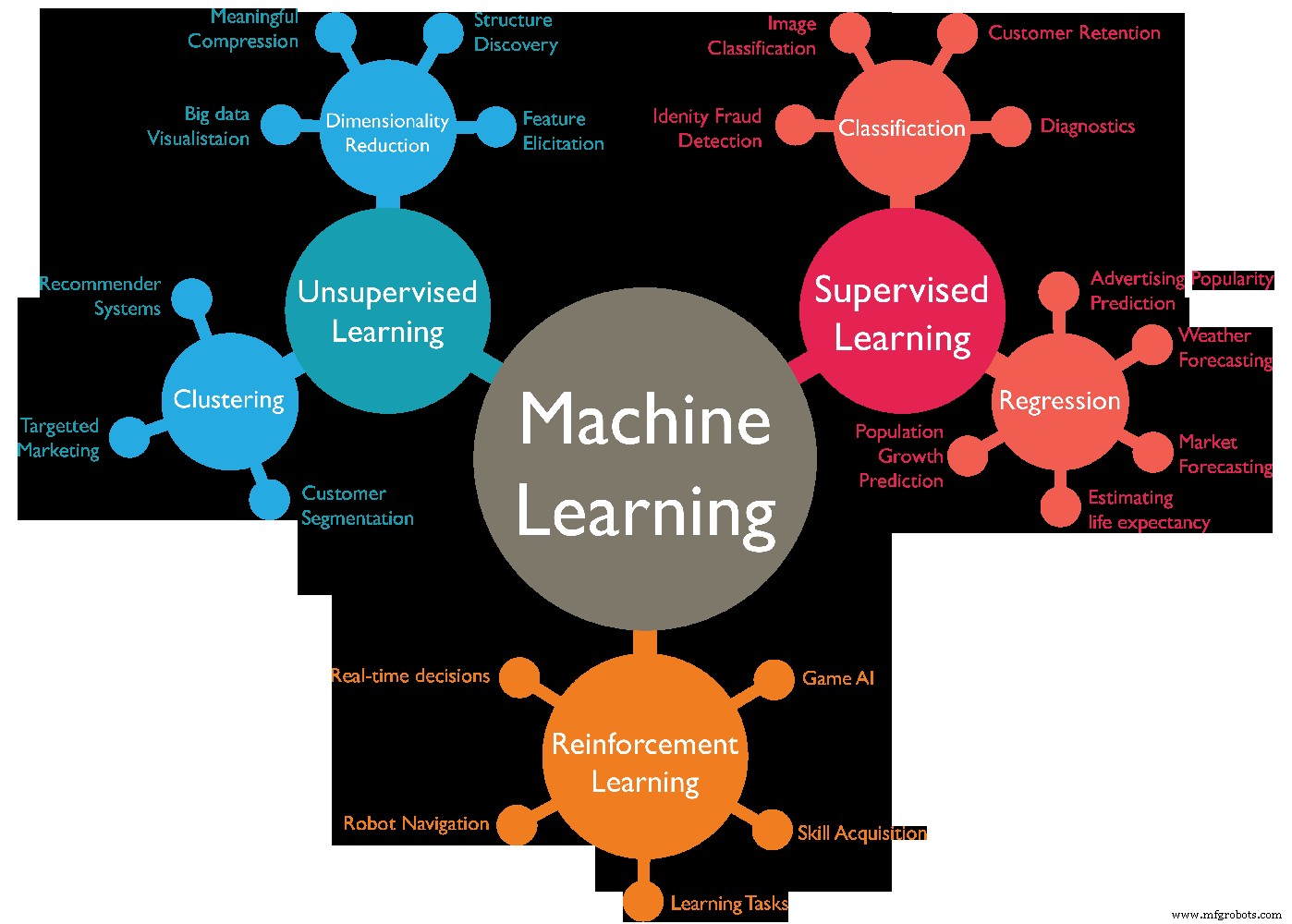
Il existe différents types d'algorithmes d'apprentissage automatique, il peut généralement être divisé en 4 catégories différents types d'apprentissage automatique sont les suivants :-
- Apprentissage supervisé.
- Apprentissage non supervisé.
- Apprentissage semi-supervisé.
- Apprentissage par renforcement.
Apprentissage supervisé
Lorsque la machine est supervisée alors qu'elle est dans sa phase « d'apprentissage », ce type d'entraînement est appelé apprentissage supervisé. Que voulons-nous vraiment dire lorsque nous disons qu'une machine est supervisée ? ?. Qu'est-ce que cela signifie vraiment d'appliquer des algorithmes de manière à permettre à la machine d'apprendre à utiliser ses anciennes données (données fournies dans le passé) et de les utiliser pour faire des prédictions d'événements futurs entourant le type de données saisies, c'est-à-dire les anciennes données.
L'analyse est lancée et tous les matériaux de l'ensemble de données d'apprentissage et étiquetés sont en corrélation avec la machine de telle manière qu'elle peut prédire les valeurs de sortie correctes. Cela signifie que nous fournissons à la machine beaucoup d'informations sur un cas particulier, puis qu'elle fournit un résultat de cas. Le résultat est appelé les données étiquetées tandis que le reste des informations est utilisé comme caractéristiques d'entrée. Le système peut alors également fournir des cibles pour de nouvelles entrées après une formation suffisante. L'algorithme peut comparer sa sortie avec la sortie prévue et trouver des différences pour modifier le modèle en conséquence.
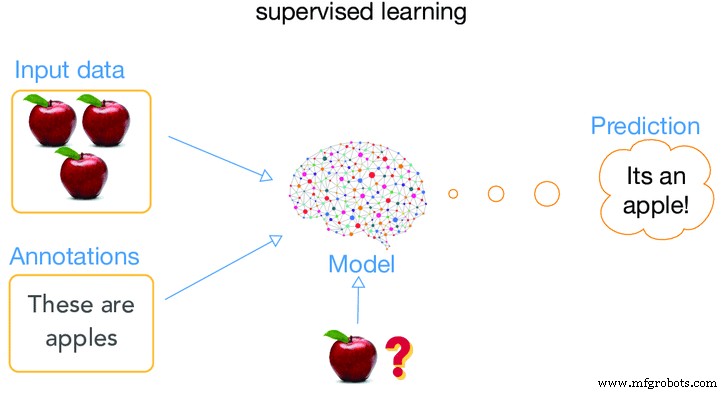
image Courtoisie artificialintelligence.oodles.io/
La plupart du temps, cette méthode est la classification manuelle, qui est la plus facile à réaliser pour un ordinateur et la plus difficile pour les humains. Un exemple de cette méthode consiste à dire à la machine des réponses standard, et lorsque la machine est testée, la machine répondra toujours en fonction de la réponse standard et, par conséquent, sa fiabilité sera également plus grande.
Apprentissage non supervisé
Le matériel fourni n'a pas d'étiquette, et la machine correspond alors aux caractéristiques des données et classe les matériaux. En raison du manque d'ensembles d'apprentissage étiquetés, la machine identifie alors des modèles dans les données qui ne sont pas si évidents pour les humains.
image Courtesy data-flair.training/Dans cette méthode, il n'y a pas de classification manuelle, qui est la plus facile pour les humains, mais la plus difficile pour l'ordinateur et peut causer beaucoup plus d'erreurs. Le système ne détermine généralement pas la sortie prévue, mais il recherche les données fournies et peut établir des relations à partir d'ensembles de données pour décrire des structures cachées à partir de données non étiquetées. Par conséquent, pour reconnaître des modèles dans les données, l'apprentissage non supervisé est extrêmement utile et nous aide également à prendre des décisions.
Apprentissage semi-supervisé
L'apprentissage semi-supervisé est différent de l'apprentissage supervisé et de l'apprentissage non supervisé dans lequel, soit il n'y a pas d'étiquettes présentes pour toutes les observations de données, soit des étiquettes sont présentes.
En semi-supervisé, les données étiquetées (supervisées) et non étiquetées (non supervisées) sont utilisées pour la formation. SSL est un mélange des deux types d'apprentissages dans lesquels une petite quantité de données est étiquetée et de grandes quantités de données ne sont pas étiquetées. La machine doit trouver des caractéristiques à travers des données étiquetées, puis en utilisant le modèle de base, elle classe les autres données en conséquence. Les systèmes SSL peuvent non seulement améliorer considérablement la précision de leur apprentissage, mais également effectuer des prédictions plus précises.
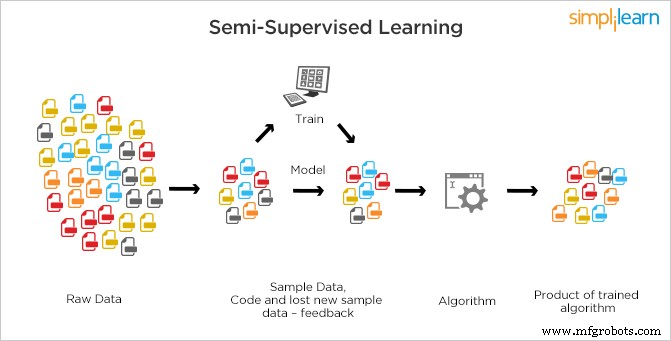
C'est la méthode la plus couramment utilisée car le coût de l'étiquetage est élevé car des experts humains qualifiés sont nécessaires. Il nécessite des ressources pertinentes pour le former et en tirer des enseignements, tandis que l'acquisition de données non étiquetées ne nécessite généralement pas de ressources supplémentaires. En raison du manque d'étiquettes dans la majorité des observations mais de la présence de quelques-uns, les algorithmes semi-supervisés sont préférés comme les meilleurs candidats pour construire un modèle.
Ces méthodes bénéficient de l'idée que même si les membres du groupe sont inconnus parce que les données non étiquetées le sont plus généralement, les informations sur les paramètres sont toujours transportées dans le étiqueté et peuvent être trouvées en l'utilisant.
Apprentissage par renforcement
L'apprentissage par renforcement est ce qui se rapproche le plus de la façon dont nous, les humains, apprenons. Les algorithmes RML sont une méthode d'apprentissage dans laquelle la machine interagit de manière répétée avec son environnement en construisant de nouvelles actions et découvre des erreurs ou des récompenses. Il utilise un système basé sur des récompenses positives ou négatives.
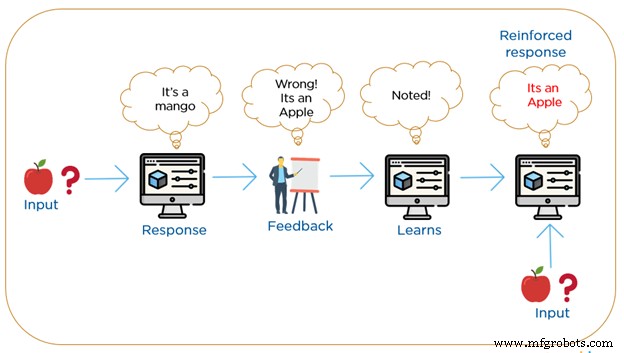
La recherche par essais et erreurs avec récompense différée est la caractéristique la plus pertinente de l'apprentissage par renforcement. La machine construit un comportement en utilisant les observations recueillies lors de l'interaction avec l'environnement et prend des mesures qui maximiseraient la récompense ou minimiseraient le risque. Cette méthode permet aux machines de déterminer automatiquement le comportement idéal dans un certain contexte pour augmenter ses performances. Dans l'apprentissage par renforcement, il n'y a pas de matériel étiqueté, mais à la place, il nécessite une simple rétroaction indiquant quelle étape est correcte et cette étape est fausse, c'est ce qu'on appelle le signal de renforcement.

Selon la norme de rétroaction, la machine révise progressivement sa classification jusqu'à ce qu'elle obtienne enfin le bon résultat. L'intégration de l'apprentissage par renforcement est nécessaire pour atteindre un certain niveau de précision dans l'apprentissage non supervisé,
RML est probablement le plus difficile à produire et à exécuter dans un environnement professionnel, mais il est couramment utilisé pour les voitures autonomes.
Technologie industrielle
- La chaîne d'approvisionnement et l'apprentissage automatique
- Quatre questions clés pour libérer la puissance des données de terrain en direct
- Elementary Robotics lève 13 millions de dollars pour ses offres d'apprentissage automatique et de vision par ordinateur destinées à l'industrie
- Apprentissage automatique sur le terrain
- Le rôle de l'analyse de données pour les propriétaires d'actifs dans l'industrie pétrolière et gazière
- AWS renforce ses offres d'IA et d'apprentissage automatique
- Qu'est-ce qu'une fraiseuse et à quoi sert-elle ?
- Kepware vs MachineMetrics :Quelle est la meilleure solution pour la collecte de données machine ?
- Les 9 applications d'apprentissage automatique que vous devez connaître