


Introduction à la science des données | Composants clés | Types et opportunités
Qu'est-ce que la science des données ?
La science des données est un domaine interdisciplinaire impliquant l'utilisation de méthodes, de processus et de systèmes scientifiques pour collecter, préparer et analyser des données sous forme structurée et non structurée. La science des données fait appel à divers domaines, notamment les mathématiques, les statistiques, les bases de données, les sciences de l'information et l'informatique. Les données peuvent être de plusieurs types et de différentes tailles.
Besoin de Data Science en tant que domaine distinct :
La principale raison de la mise à niveau de la science des données au niveau d'un domaine distinct est le taux de croissance exponentielle des données qui nous entourent. Les estimations montrent qu'environ 1,7 mégaoctets de données seront produits par seconde d'ici 2020. L'accumulation de données numériques atteindra 44 000 milliards de gigaoctets. Avec de telles quantités de données, leur donner un sens et les stocker devient de plus en plus difficile. En conséquence, nous avons besoin d'un moyen d'étudier et de donner un sens à ces données. La science des données a donc été reconnue comme un domaine distinct. 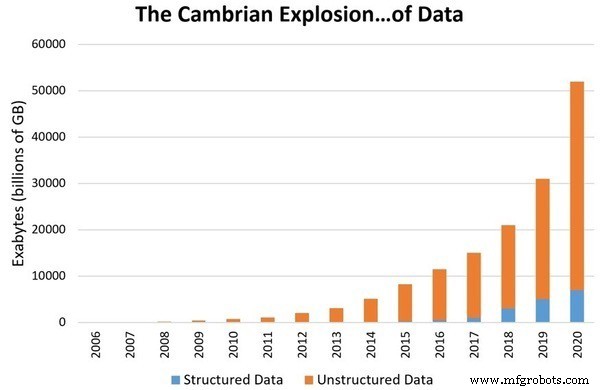
La science des données autour de nous :
Les entreprises utilisent la science des données pour comprendre et trier facilement leurs processus de données au sein de l'entreprise. Par exemple, Google utilise Data Science pour personnaliser les publicités affichées aux utilisateurs sur les sites Web qu'ils utilisent. Cela se fait via leur programme AdSense qui permet aux éditeurs de diffuser du contenu à des publics ciblés.
De même, Uber calcule combien un client doit être facturé, quand accorder des remises et à qui. Airbnb aide les gens en estimant le prix auquel ils devraient louer leur logement en utilisant Data Science. En termes simples, nous pouvons comprendre cela en considérant les clients et les utilisateurs comme des données brutes et la science des données aide à interpréter ces données. 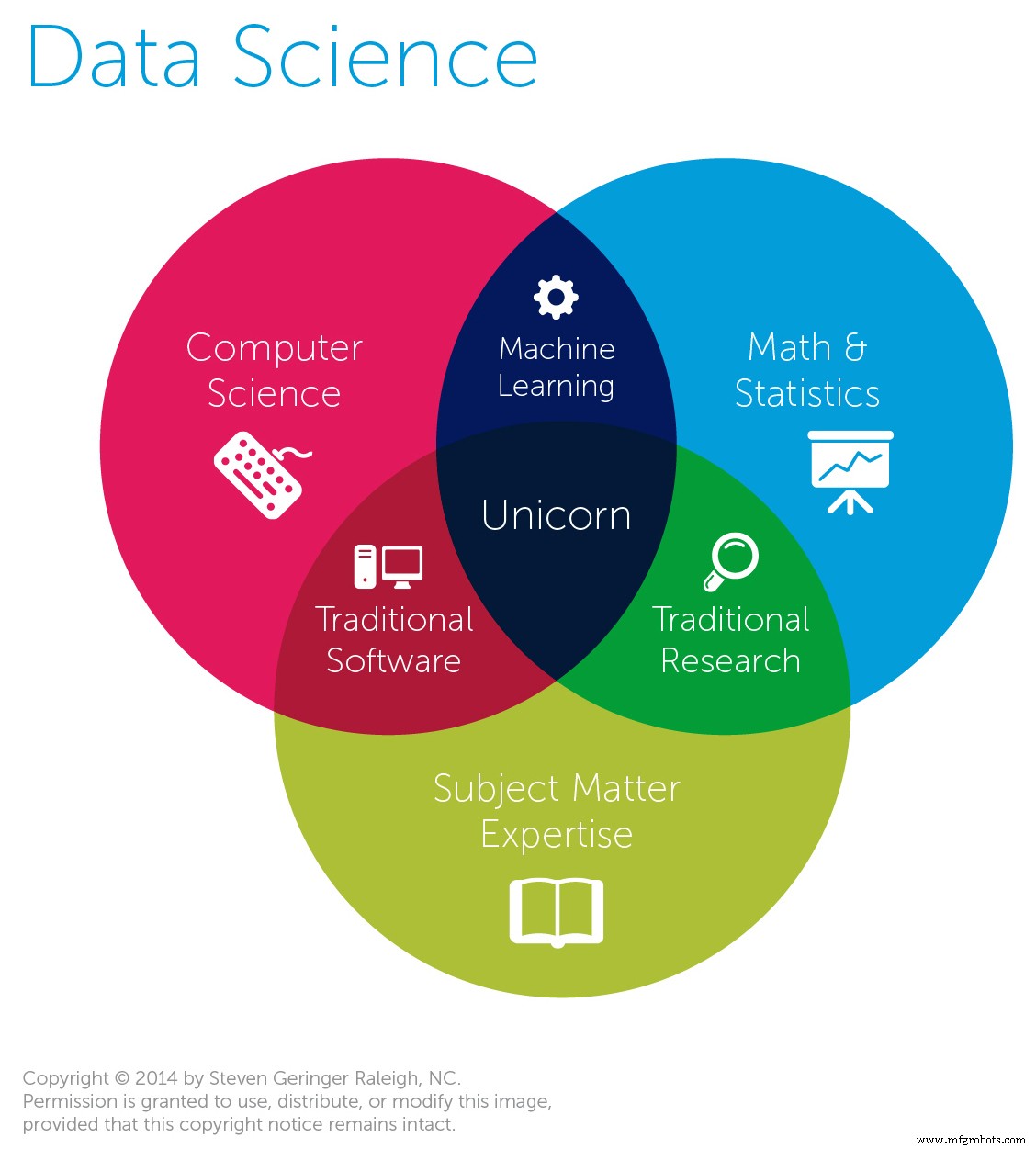
La science des données dans les organisations gouvernementales et non gouvernementales :
Les données sont un atout essentiel pour les organisations gouvernementales. De plus en plus de données sont collectées chaque jour. Par conséquent, ils ont besoin d'un moyen de trier et de stocker toutes ces données, ce qui peut être fait via Data Science. De même, les organisations non gouvernementales utilisent également la science des données. Le WWF utilise les sciences des données pour montrer des informations sous forme de statistiques concernant les problèmes de la faune et ainsi rendre leur cause efficace.
Opportunités en science des données :
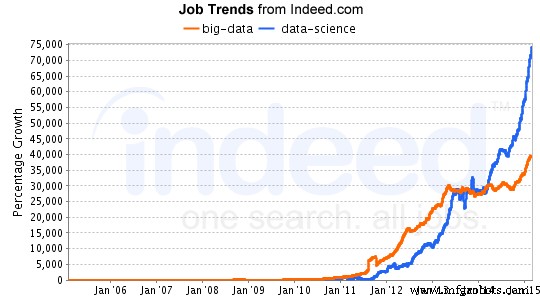
Alors que le domaine de la science des données continue de se développer, les opportunités d'emploi dans ce domaine augmentent également de manière exponentielle. L'analyse effectuée par LinkedIn sur la croissance de l'emploi en science des données a montré une forte augmentation dans le domaine de la science des données, en particulier au cours des 30 dernières années. Si vous êtes intéressé par la science des données, vous pouvez obtenir des cours gratuits en ligne. Découvrez ce tutoriel sur un salon commun.
Composants clés :
Nous allons maintenant vous donner un aperçu de la science des données et de ses différentes composantes.
1 :Programmation :
La science des données concerne les données. Pour organiser et analyser ces données, nous utilisons la programmation. Les langages de programmation sont de plusieurs types. Les deux plus répandus étant Python et R.
Python : Python est le langage de programmation le plus lisible et le plus flexible, d'où son utilisation généralisée. Il dispose de nombreux packages statistiques et numériques puissants, notamment NumPy et pandas, Matplotlib, Tensorflow, iPython, etc. Python est beaucoup plus rapide et plus facile à apprendre.
R : R est un autre langage de programmation, mais il est principalement axé sur les techniques statistiques et graphiques. R est largement utilisé par les statisticiens et les mineurs de données pour le développement de logiciels statistiques et l'analyse de données. C'est un langage open source.
2 :Les données et leurs types :
Le prochain élément clé est les données elles-mêmes. Afin de comprendre les données, nous devons d'abord comprendre leurs types.
Données structurées : Les données structurées font référence à des informations présentant un degré élevé d'organisation. Il peut être facilement représenté sous forme de tableau, peut être stocké et traité dans des bases de données.
Données non structurées : Les données non structurées sont des informations qui n'ont pas de modèle de données ou qui ne sont pas organisées. Il peut s'agir de texte ou de données telles que des dates, des chiffres, des e-mails, des fichiers PDF, des images, des vidéos, etc.
Langage naturel : Données sous forme de langues écrites utilisées pour communiquer telles que l'anglais, l'espagnol, l'ourdou, etc. Elles peuvent être considérées comme un sous-type de données non structurées.
Image, Vidéo, Audio : Les images, les vidéos et les audios sont également de forme non structurée. Ils sont générés à l'aide de caméras et de microphones. L'utilisation croissante est constatée dans les smartphones où les images et les vidéos sont enregistrées et traitées chaque jour.
Données basées sur des graphiques : Un graphe est un ensemble de sommets et d'arêtes. C'est une structure mathématique utilisée pour montrer la relation entre deux entités.
Généré par la machine : Les données générées par les machines sont créées par des systèmes informatiques, des applications ou des machines sans l'intervention d'humains.
3 :Statistiques, probabilités et leur relation avec la science des données :
Statistiques : La statistique est une branche des mathématiques qui traite de la collecte, de l'interprétation, de l'analyse, de la présentation et de l'organisation des données. Il utilise pro0gamming pour analyser les données.
Probabilité : La probabilité est la mesure de la probabilité qu'un événement se produise. Il est quantifié par un nombre compris entre 0 et 1, où 0 indique l'impossibilité et 1 indique la certitude.
Relation avec la science des données : Les statistiques et les probabilités sont toutes deux liées à la science des données. Ils sont à la base du traitement et de l'analyse des données. Nous utilisons ces deux sciences en relation avec la science des données pour interpréter correctement les données.
4 :Apprentissage automatique :
Le machine learning est le domaine de l'informatique issu de l'IA. Il utilise des techniques statistiques pour donner aux ordinateurs la capacité d'apprendre sans être programmés. La machine améliore progressivement ses performances sur une tâche spécifique en modifiant la structure ou le programme. L'apprentissage automatique a trois objectifs principaux. Un, pour apprendre les changements et la représentation de ces changements. Deuxièmement, pour généraliser la performance, elle est donc efficace non pas sur une seule tâche mais sur des tâches similaires. Troisième. Pour améliorer les performances d'une machine et trouver des moyens d'empêcher la dégradation des performances. En science des données, l'apprentissage automatique est utilisé dans les algorithmes, les méthodes de régression et de classification. Il est utilisé pour prédire le résultat des données traitées de différentes manières.
5 : Mégadonnées :
Le Big Data est le nom donné aux données en si grande quantité que le stockage ou le traitement de ces données nécessite un grand nombre d'ordinateurs. Elle se caractérise par trois V :
Volume : Données en gros volumes allant de téraoctets à zettaoctets.
Variété : Les données peuvent montrer beaucoup de variété et de diversité. Il peut s'agir d'un mélange de deux types de données ou plus, par exemple, à la fois structurées et non structurées.
Vitesse : Les données sont générées à un rythme en croissance constante. C'est essentiellement la vitesse des données. 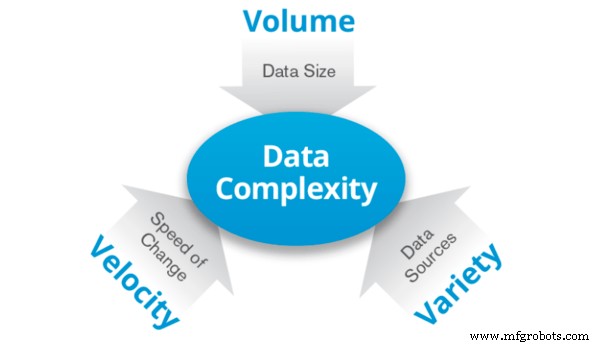
En science des données, les données sont regroupées sous plusieurs formes et types. Les mégadonnées peuvent faire référence à d'énormes volumes de données qui ne peuvent pas être traités à l'aide d'applications traditionnelles. Les scientifiques des données utilisent différents outils pour étudier et traiter le Big Data, par exemple, Hadoop, Spark, R et Java, etc.
Technologie industrielle
- Variables C# et types de données (primitifs)
- Types de données Python
- Une introduction à l'informatique de pointe et des exemples de cas d'utilisation
- 5 types de centres de données différents [avec exemples]
- C - Types de données
- MATLAB - Types de données
- C# - Types de données
- Types et classification des processus d'usinage | Sciences de la fabrication
- Fraiseuses - Introduction et types discutés