


Combinaison de deux modèles d'apprentissage en profondeur
L'apprentissage en profondeur est un outil inestimable dans l'arsenal des analystes de données avec de nouvelles applications dans différentes sphères, y compris les applications industrielles. Le principe de base de l'apprentissage en profondeur consiste à utiliser de gros volumes de données pour créer un modèle capable de faire des prédictions précises.
Considérons un petit exemple où les ingénieurs en automatisation industrielle pourraient rencontrer le besoin de combiner deux modèles d'apprentissage en profondeur. Une entreprise de smartphones emploie une ligne de production qui fabrique plusieurs modèles de smartphones. La vision informatisée utilisant des algorithmes d'apprentissage en profondeur effectue le contrôle qualité de la ligne de production.
Actuellement, la ligne de production fabrique deux smartphones :le téléphone A et le téléphone B. Les modèles A et B effectuent le contrôle qualité pour les téléphones A et B, respectivement. L'entreprise présente un nouveau smartphone, le téléphone C. Le site de production peut avoir besoin d'un nouveau modèle pour effectuer le contrôle qualité du troisième téléphone appelé modèle C. La construction d'un nouveau modèle nécessite une énorme quantité de données et de temps.
Figure 1. Vidéo utilisée avec l'aimable autorisation de Matt Chan
Une autre alternative consiste à combiner les apprentissages des modèles A et B pour construire le modèle C. Le modèle combiné peut effectuer un contrôle qualité avec des ajustements mineurs des poids.
Un autre scénario où les modèles doivent être combinés est lorsqu'un nouveau modèle doit effectuer deux tâches simultanément. Deux modèles d'apprentissage en profondeur pourraient effectuer ces tâches. Un modèle qui doit classer un ensemble de données et faire des prédictions dans chaque catégorie peut être créé en combinant deux modèles :un qui peut classer de grands ensembles de données et un qui peut faire des prédictions.
Ensemble d'apprentissage
La combinaison de plusieurs modèles d'apprentissage en profondeur est un apprentissage d'ensemble. Ceci est fait pour faire de meilleures prédictions, classifications ou autres fonctions d'un modèle d'apprentissage en profondeur. L'apprentissage d'ensemble peut également créer un nouveau modèle avec les fonctionnalités combinées de différents modèles d'apprentissage en profondeur.
La création d'un nouveau modèle présente de nombreux avantages par rapport à la formation complète d'un nouveau modèle à partir de zéro.
- Nécessite très peu de données pour entraîner le modèle combiné, car la plupart des apprentissages sont dérivés des modèles combinés.
- La création d'un modèle combiné prend moins de temps que la création d'un nouveau modèle.
- Nécessite moins de ressources informatiques lorsque les modèles sont combinés.
- Les nouveaux modèles combinés ont une précision et des capacités supérieures à celles combinées pour obtenir le nouveau modèle.
En raison des différents avantages de l'apprentissage d'ensemble, il est souvent effectué pour créer un nouveau modèle. Les algorithmes d'apprentissage en profondeur, les packages et les modèles entraînés respectifs doivent combiner différents modèles, et les algorithmes d'apprentissage en profondeur les plus avancés sont écrits avec Python.
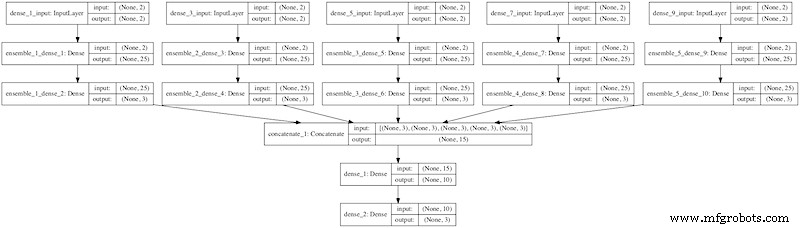
Figure 2. Un ensemble d'empilement pour les réseaux de neurones d'apprentissage en profondeur en Python. Image utilisée avec l'aimable autorisation de Maîtrise de l'apprentissage automatique
Connaître Python et les outils de deep learning respectifs utilisés sont des prérequis pour combiner différents modèles. Une fois tous ces éléments en place, différentes techniques sont mises en œuvre pour combiner différents algorithmes d'apprentissage en profondeur. Ils sont expliqués dans les sections suivantes.
Méthode moyenne (pondérée)
Dans cette méthode, la moyenne des deux modèles est utilisée comme nouveau modèle. C'est la méthode la plus simple pour combiner deux modèles d'apprentissage en profondeur. Le modèle créé en prenant la moyenne simple de deux modèles a plus de précision que les deux modèles combinés.
Pour améliorer encore la précision et les résultats du modèle combiné, la moyenne pondérée est une option viable. Les pondérations attribuées aux différents modèles pourraient être basées sur les performances des modèles ou sur la quantité de formation subie par chaque modèle. Dans cette méthode, deux modèles différents sont combinés pour former un nouveau modèle.
Méthode d'ensachage
Le même modèle d'apprentissage en profondeur peut avoir plusieurs itérations. Les différentes itérations seraient entraînées avec différents ensembles de données et auraient différents niveaux d'amélioration. La méthode d'ensachage consiste à combiner les différentes versions du même modèle d'apprentissage en profondeur.
La méthodologie reste la même que celle de la méthode des moyennes. Différentes versions du même modèle d'apprentissage en profondeur sont combinées selon une moyenne simple ou une moyenne pondérée. Cette méthode permet de créer un nouveau modèle qui n'a pas le biais de confirmation construit avec un seul modèle, ce qui rend le modèle plus précis et plus performant.
Méthode de boost
La méthode d'amplification est similaire à l'utilisation d'une boucle de rétroaction pour les modèles. La performance d'un modèle est utilisée pour ajuster les modèles suivants. Cela crée une boucle de rétroaction positive qui accumule tous les facteurs qui contribuent au succès du modèle.
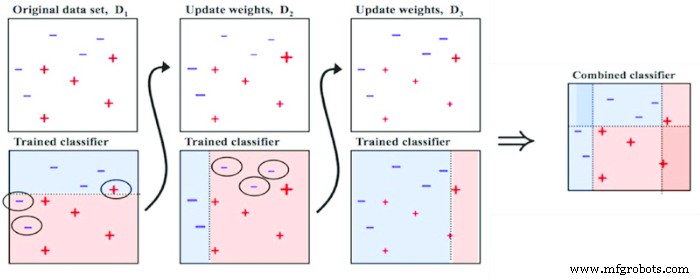
Figure 3. Méthode de stimulation pour l'apprentissage en groupe. Image utilisée avec l'aimable autorisation de Ashish Patel
La méthode de boosting réduit le biais et la variance rencontrés par les modèles. Cela est possible car ces côtés négatifs sont filtrés dans les itérations suivantes. Le boost peut se faire de deux manières distinctes :le boost basé sur le poids et le boost basé sur les résidus.
Méthode de concaténation
Cette méthode est utilisée lorsque différentes sources de données doivent être fusionnées dans le même modèle. Cette technique de combinaison prend différentes entrées et les concatène dans le même modèle. L'ensemble de données résultant aura plus de dimensions que l'ensemble de données d'origine.
Lorsqu'elles sont effectuées plusieurs fois de manière séquentielle, les dimensions des données augmenteront jusqu'à un très grand nombre, ce qui pourrait entraîner un surajustement et une perte d'informations critiques, réduisant ainsi les performances du modèle combiné.
Méthode d'empilement
La méthode d'empilement pour les modèles d'apprentissage en profondeur d'ensemble intègre les différentes méthodes pour développer des modèles d'apprentissage en profondeur en utilisant les performances des itérations précédentes pour booster les modèles précédents. L'ajout d'un élément de prise de moyenne pondérée à ce modèle empilé améliore les contributions positives des sous-modèles.
De même, des techniques d'ensachage et des techniques de concaténation peuvent être ajoutées aux modèles. La méthode consistant à combiner différentes techniques pour combiner des modèles peut améliorer les performances du modèle combiné.
Les méthodologies, techniques et algorithmes qui peuvent être utilisés pour combiner des modèles d'apprentissage en profondeur sont innombrables et en constante évolution. Il y aura de nouvelles techniques pour accomplir la même tâche offrant de meilleurs résultats. Les idées clés à connaître sur la combinaison de modèles sont données ci-dessous.
- La combinaison de modèles d'apprentissage en profondeur est également appelée apprentissage d'ensemble.
- La combinaison de différents modèles est effectuée pour améliorer les performances des modèles d'apprentissage en profondeur.
- Créer un nouveau modèle par combinaison nécessite moins de temps, de données et de ressources de calcul.
- La méthode la plus courante pour combiner des modèles consiste à faire la moyenne de plusieurs modèles, où la prise d'une moyenne pondérée améliore la précision.
- L'ensachage, le boosting et la concaténation sont d'autres méthodes utilisées pour combiner des modèles d'apprentissage en profondeur.
- L'apprentissage par ensemble empilé utilise différentes techniques de combinaison pour créer un modèle.
Technologie de l'Internet des objets
- IA se déplaçant lentement vers l'usine
- ICP :carte accélératrice basée sur FPGA pour l'inférence d'apprentissage en profondeur
- IA externalisée et apprentissage en profondeur dans le secteur de la santé :la confidentialité des données est-elle menacée ?
- Deux chaînes de valeur IoT industrielles
- Prédiction précise de la durée de vie de la batterie avec des modèles d'apprentissage automatique
- Intelligence artificielle vs apprentissage automatique vs apprentissage en profondeur | La différence
- HPE applique DevOps aux modèles d'IA
- Le Deep Learning et ses nombreuses applications
- Comment le Deep Learning automatise l'inspection pour l'industrie des sciences de la vie