


La puce d'inférence matérielle cible les applications automobiles
La société hongroise AImotive, développeur de technologies de conduite automatisée basées sur des logiciels et du matériel, a commencé à livrer la propriété intellectuelle (IP) de son moteur d'inférence matériel de réseau neuronal (NN) aiWare3 à ses principaux clients.
Son cœur IP aiWare3P, annoncé l'année dernière, offre un accélérateur NN matériel pour les applications de vision automobile haute résolution et en tant que composant au sein des sous-systèmes certifiés ISO26262 ASIL A, B et supérieurs. Le cœur, qui peut être déployé dans un système sur puce (SoC), ou en tant qu'accélérateur NN autonome, est fourni sous forme de RTL entièrement synthétisable ; sa microarchitecture de bas niveau est conçue pour utiliser beaucoup moins de ressources CPU hôte ou de mémoire partagée que les autres accélérateurs matériels NN.
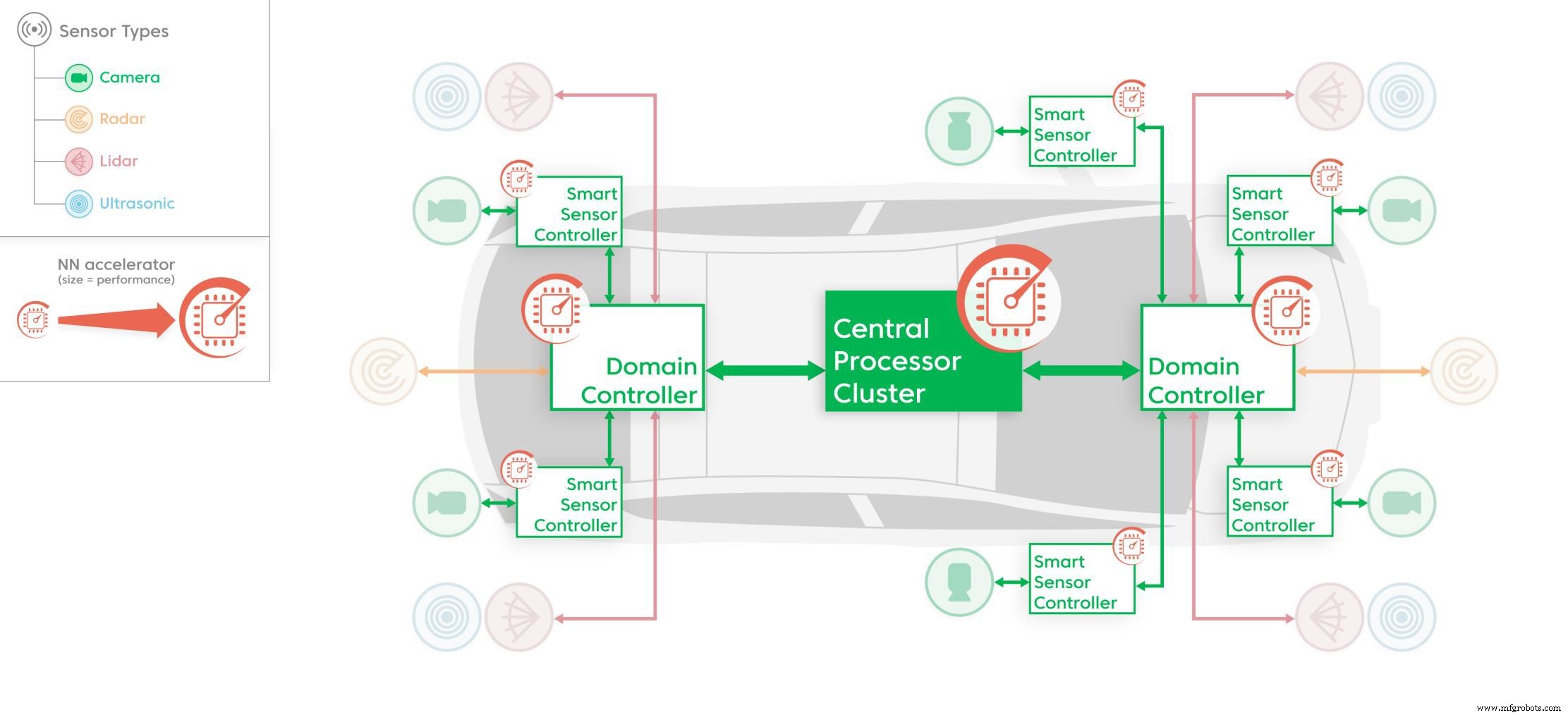 Accélérateurs NN dédiés comme l'IP aiWare3P utilisé dans diverses parties de la plate-forme électronique du véhicule (Source :AImotive)
Accélérateurs NN dédiés comme l'IP aiWare3P utilisé dans diverses parties de la plate-forme électronique du véhicule (Source :AImotive)
S'adressant à EE Times Europe sur la façon dont l'offre AIMotive est différente des autres solutions, Tony-King Smith, conseiller exécutif de l'entreprise, a déclaré que la plupart des joueurs de puces parlent en termes académiques d'accélérateurs basés sur des GPU et des SoC, testés dans un environnement de laboratoire, ce qui ne se traduit pas vraiment bien au monde réel. « La différence cruciale est qu'il est nécessaire de comprendre les principes des réseaux de neurones plutôt que l'accélérateur. Dans notre solution, il n'y a pas de DSP, pas de NOC (réseau sur puce). aiWare est uniquement conçu pour l'inférence automobile, nous sommes donc en mesure de fournir une faible latence de l'entrée à la sortie. Il a ajouté que les améliorations apportées à la sortie RTL du nouveau cœur signifient qu'il libère le sous-système principal du processeur, et que le cœur peut ensuite être attaché à n'importe quel SoC d'accélérateur.
Le noyau IP aiWare3P intègre des fonctionnalités qui se traduisent par des performances améliorées, une consommation d'énergie réduite, un déchargement plus important du processeur hôte et une disposition plus simple pour les conceptions de puces plus grandes. Chaque cœur offre jusqu'à 16 TMAC/s (> 32 TOPS) à 2 GHz, avec des implémentations multi-cœurs et multi-puces capables de fournir jusqu'à 50+ TMAC/s (> 100 INT8 TOPS) - utile pour multi-caméras ou hétérogène applications riches en capteurs. Le noyau est conçu pour un fonctionnement à température étendue AEC-Q100 et comprend des fonctionnalités permettant aux utilisateurs d'obtenir la certification ASIL-B et supérieure.
L'évolutivité des performances du cœur IP à plus de 50 TMAC/s (> 100 TOPS) par puce et l'inférence soutenue à faible latence sont le résultat de sa micro-architecture de bas niveau. Il utilise une conception de base brevetée pour une gestion des flux de données hautement déterministe, avec une architecture centrée sur la mémoire hautement parallèle offrant jusqu'à 100 fois plus de bande passante mémoire sur puce que les autres accélérateurs NN matériels, garantissant jusqu'à 95 % d'efficacité soutenue pour les DNN complexes utilisés avec de grands entrées telles que plusieurs caméras HD.
Prenant en charge le NNEF de Khronos ainsi que les entrées ONNX standard ouvertes, le SDK aiWare compile directement les binaires sans avoir besoin de programmation de bas niveau de DSP ou de MCU. Il comprend des outils automatisés pour la quantification FP32 à INT8 avec peu ou pas de perte de précision, ainsi qu'un portefeuille croissant d'outils sophistiqués d'analyse des performances DNN. Ces derniers sont conçus pour aider les ingénieurs logiciels et IA à migrer et à transformer les NN formés en laboratoire en solutions efficaces en temps réel s'exécutant sur des plates-formes matérielles automobiles de production alimentées par aiWare.
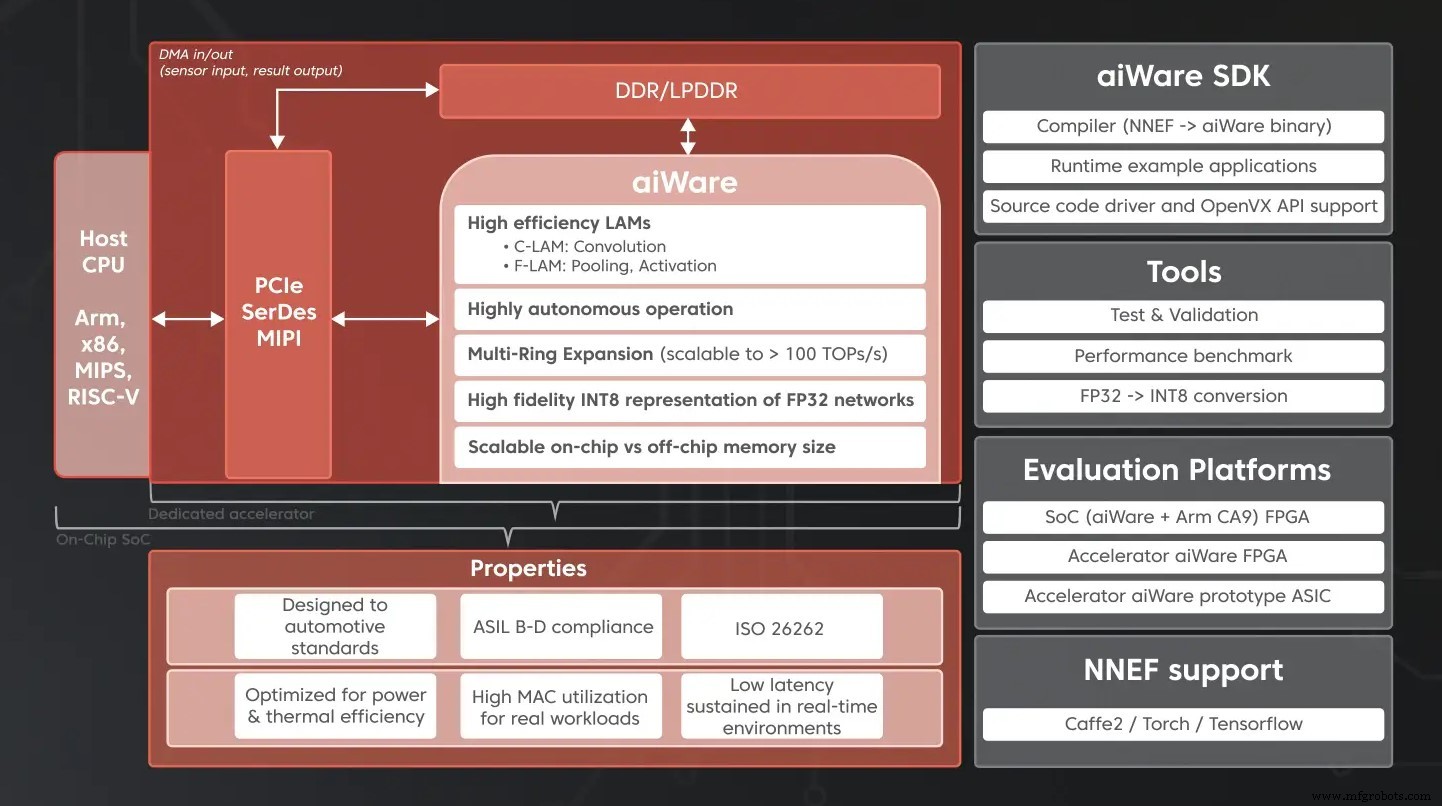 Les éléments constitutifs d'un accélérateur d'IA automobile, y compris l'IP matérielle aiWare (Source :AImotive)
Les éléments constitutifs d'un accélérateur d'IA automobile, y compris l'IP matérielle aiWare (Source :AImotive)
Marton Feher, vice-président senior de l'ingénierie matérielle pour AImotive, a déclaré :« Notre version aiWare3P prête pour la production rassemble tout ce que nous savons sur l'accélération des réseaux de neurones pour les applications d'inférence d'IA automobile basées sur la vision. Nous disposons désormais de l'une des solutions d'accélération NN les plus efficaces et les plus convaincantes de l'industrie automobile pour la production en volume L2/L2+/L3 AI."
L'IP matérielle aiWare3P est déployée dans une gamme de solutions de production L2/L2+, et est également adoptée pour les études d'applications de capteurs hétérogènes plus avancées. Les clients incluent Nextchip pour leur prochain processeur Apache5 Imaging Edge Processor et ON Semiconductor pour leur projet de collaboration avec AImotive visant à démontrer les capacités avancées de fusion de capteurs hétérogènes.
AImotive a annoncé qu'il publierait une mise à jour complète de ses résultats de référence publics au premier trimestre 2020 sur la base du noyau IP aiWare3P. Cela fait partie de son engagement envers l'analyse comparative ouverte à l'aide d'analyses comparatives bien contrôlées reflétant des applications réelles telles que des entrées haute résolution pour les caméras plutôt que des analyses comparatives publiques irréalistes utilisant des entrées 224 x 224.
Aucune intervention du processeur hôte nécessaire
Les nouvelles fonctionnalités de l'IP matérielle aiWare3P incluent la prise en charge d'un portefeuille beaucoup plus large de fonctions d'activation et de pooling intégrées pré-optimisées, garantissant que 100 % de la plupart des NN s'exécutent dans le noyau aiWare3P sans aucune intervention du processeur hôte ; compression des données en temps réel, réduisant les besoins en bande passante de la mémoire externe, en particulier pour les tailles d'entrée plus importantes et les réseaux plus profonds ; et un couplage croisé avancé entre les moteurs de convolution C-LAM et les moteurs de fonction F-LAM, pour augmenter l'efficacité d'exécution superposée et entrelacée.
La microarchitecture physique basée sur des tuiles permet une mise en œuvre physique plus facile de grands cœurs aiWare en minimisant les contraintes de temps difficiles sur n'importe quel nœud de processus; et la gestion des données basée sur des tuiles logiques permet une évolutivité efficace de la charge de travail jusqu'à un maximum de 16 TMAC/s par cœur, sans avoir besoin de caches, de NOC ou d'autres approches complexes basées sur des processeurs multicœurs qui créent des goulots d'étranglement, réduisent le déterminisme et consomment plus d'énergie et zone silicium Le RTL aiWare3P sera expédié à tous les clients à partir de janvier 2020, et un SDK mis à niveau comprend un compilateur amélioré et de nouveaux outils d'analyse des performances pour l'estimation hors ligne et l'analyse précise du matériel cible en temps réel.
Embarqué
- Infineon lance la série de puissance embarquée TLE985x pour les applications automobiles
- L'architecture de la puce IA cible le traitement des graphes
- Les accélérateurs matériels servent les applications d'IA
- Le capteur Hall cible les systèmes automobiles critiques pour la sécurité
- Débuts du processeur radar d'imagerie automobile à 30 ips
- EKF :plate-forme robuste à montage mural pour applications ferroviaires, automobiles et industrielles
- La fibre de carbone dans les applications automobiles
- Composés PPA durcis et stabilisés à la chaleur pour les applications automobiles exigeantes
- Technologies SGL Carbon destinées aux applications automobiles et aérospatiales