


SOLID :principes de conception orientés objet
SOLID est un acronyme mnémotechnique pour la conception de classe dans la programmation orientée objet. Les principes établissent des pratiques qui aident à développer de bonnes habitudes de programmation et un code maintenable.
En considérant la maintenance et l'extensibilité du code à long terme, les principes SOLID enrichissent l'environnement de développement de code Agile. La comptabilisation et l'optimisation des dépendances de code permettent de créer un cycle de vie de développement logiciel plus simple et organisé.

Que sont les principes SOLID ?
SOLID représente un ensemble de principes pour la conception de classes. Robert C. Martin (Oncle Bob) a introduit la plupart des principes de conception et a inventé l'acronyme.
SOLIDE signifie :
- Principe de responsabilité unique
- Principe Ouvert-Fermé
- Principe de substitution de Liskov
- Principe de séparation des interfaces
- Principe d'inversion des dépendances
Les principes SOLID représentent un ensemble de meilleures pratiques pour la conception de logiciels. Chaque idée représente un cadre de conception, conduisant à de meilleures habitudes de programmation, à une conception de code améliorée et à moins d'erreurs.
SOLIDE : 5 principes expliqués
La meilleure façon de comprendre le fonctionnement des principes SOLID consiste à utiliser des exemples. Tous les principes sont complémentaires et s'appliquent à des cas d'utilisation individuels. L'ordre dans lequel les principes sont appliqués n'a pas d'importance, et tous les principes ne sont pas applicables dans toutes les situations.
Chaque section ci-dessous donne un aperçu de chaque principe SOLID dans le langage de programmation Python. Les idées générales de SOLID s'appliquent à tout langage orienté objet, tel que PHP, Java ou C#. La généralisation des règles les rend applicables aux approches de programmation modernes, telles que les microservices.
Principe de responsabilité unique (SRP)
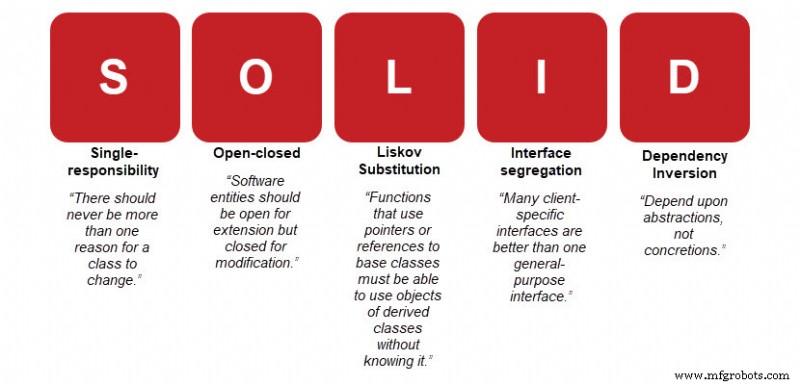
Le principe de responsabilité unique (SRP) stipule :"Il ne devrait jamais y avoir plus d'une raison pour qu'une classe change."
Lors du changement d'une classe, nous ne devons modifier qu'une seule fonctionnalité, ce qui implique que chaque objet ne doit avoir qu'un seul travail.
À titre d'exemple, regardez la classe suivante :
# A class with multiple responsibilities
class Animal:
# Property constructor
def __init__(self, name):
self.name = name
# Property representation
def __repr__(self):
return f'Animal(name="{self.name}")'
# Database management
def save(animal):
print(f'Saved {animal} to the database')
if __name__ == '__main__':
# Property instantiation
a = Animal('Cat')
# Saving property to a database
Animal.save(a)
Lorsque vous apportez des modifications au save() méthode, le changement se produit dans le Animal classer. Lors de modifications de propriétés, les modifications se produisent également dans le Animal classe.
La classe a deux raisons de changer et viole le principe de responsabilité unique. Même si le code fonctionne comme prévu, le non-respect du principe de conception rend le code plus difficile à gérer à long terme.
Pour implémenter le principe de responsabilité unique, notez que la classe d'exemple a deux tâches distinctes :
- Gestion des propriétés (le constructeur et
get_name()). - Gestion de la base de données
(save()).
Par conséquent, la meilleure façon de résoudre le problème consiste à séparer la méthode de gestion de base de données dans une nouvelle classe. Par exemple :
# A class responsible for property management
class Animal:
def __init__(self, name):
self.name = name
def __repr__(self):
return f'Animal(name="{self.name}")'
# A class responsible for database management
class AnimalDB:
def save(self, animal):
print(f'Saved {animal} to the database')
if __name__ == '__main__':
# Property instantiation
a = Animal('Cat')
# Database instantiation
db = AnimalDB()
# Saving property to a database
db.save(a)
Modification du AnimalDB la classe n'affecte pas le Animal classe avec le principe de responsabilité unique appliqué. Le code est intuitif et facile à modifier.
Principe Ouvert-Fermé (OCP)
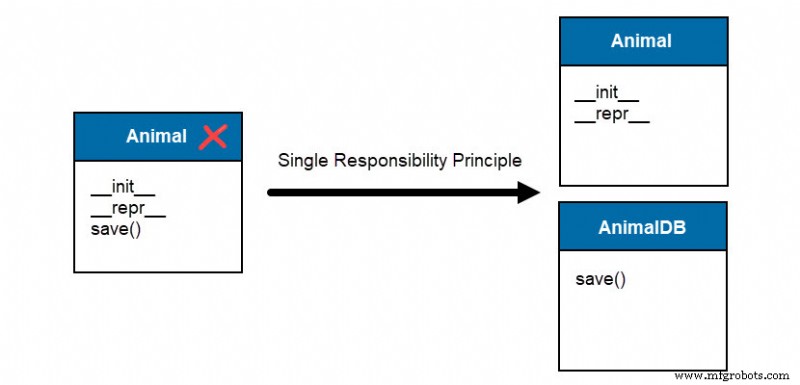
Le principe ouvert-fermé (OCP) stipule :"Les entités logicielles doivent être ouvertes pour extension mais fermées pour modification."
L'ajout de fonctionnalités et de cas d'utilisation au système ne devrait pas nécessiter la modification d'entités existantes. La formulation semble contradictoire - ajouter de nouvelles fonctionnalités nécessite de modifier le code existant.
L'idée est simple à comprendre à travers l'exemple suivant :
class Animal:
def __init__(self, name):
self.name = name
def __repr__(self):
return f'Animal(name="{self.name}")'
class Storage:
def save_to_db(self, animal):
print(f'Saved {animal} to the database')
Le Storage classe enregistre les informations d'un Animal instance à une base de données. L'ajout de nouvelles fonctionnalités, telles que l'enregistrement dans un fichier CSV, nécessite l'ajout de code au Storage classe :
class Animal:
def __init__(self, name):
self.name = name
def __repr__(self):
return f'Animal(name="{self.name}")'
class Storage:
def save_to_db(self, animal):
print(f'Saved {animal} to the database')
def save_to_csv(self,animal):
printf(f’Saved {animal} to the CSV file’)
Le save_to_csv la méthode modifie un Storage existant classe pour ajouter la fonctionnalité. Cette approche viole le principe ouvert-fermé en modifiant un élément existant lorsqu'une nouvelle fonctionnalité apparaît.
Le code nécessite la suppression du Storage à usage général classe et création de classes individuelles pour le stockage dans des formats de fichiers spécifiques.
Le code suivant illustre l'application du principe ouvert-fermé :
class DB():
def save(self, animal):
print(f'Saved {animal} to the database')
class CSV():
def save(self, animal):
print(f'Saved {animal} to a CSV file')
Le code respecte le principe ouvert-fermé. Le code complet ressemble maintenant à ceci :
class Animal:
def __init__(self, name):
self.name = name
def __repr__(self):
return f'"{self.name}"'
class DB():
def save(self, animal):
print(f'Saved {animal} to the database')
class CSV():
def save(self, animal):
print(f'Saved {animal} to a CSV file')
if __name__ == '__main__':
a = Animal('Cat')
db = DB()
csv = CSV()
db.save(a)
csv.save(a)
L'extension avec des fonctionnalités supplémentaires (telles que l'enregistrement dans un fichier XML) ne modifie pas les classes existantes.
Principe de substitution de Liskov (LSP)
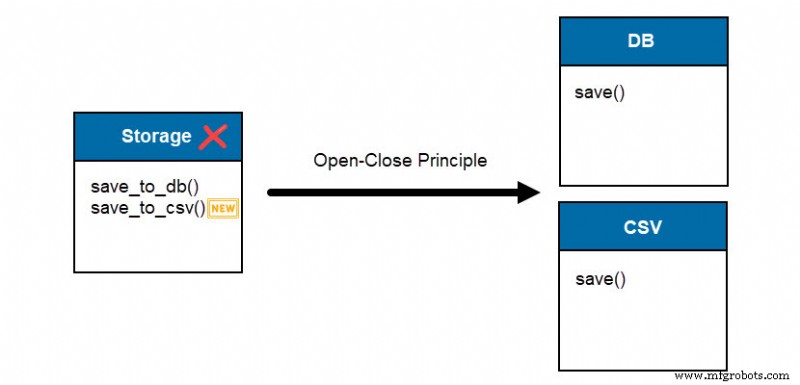
Le principe de substitution de Liskov (LSP) stipule :"Les fonctions qui utilisent des pointeurs ou des références à des classes de base doivent pouvoir utiliser des objets de classes dérivées sans le savoir."
Le principe stipule qu'une classe parent peut remplacer une classe enfant sans aucun changement notable de fonctionnalité.
Découvrez l'exemple d'écriture de fichier ci-dessous :
# Parent class
class FileHandling():
def write_db(self):
return f'Handling DB'
def write_csv(self):
return f'Handling CSV'
# Child classes
class WriteDB(FileHandling):
def write_db(self):
return f'Writing to a DB'
def write_csv(self):
return f"Error: Can't write to CSV, wrong file type."
class WriteCSV(FileHandling):
def write_csv(self):
return f'Writing to a CSV file'
def write_db(self):
return f"Error: Can't write to DB, wrong file type."
if __name__ == "__main__":
# Parent class instantiation and function calls
db = FileHandling()
csv = FileHandling()
print(db.write_db())
print(db.write_csv())
# Children classes instantiations and function calls
db = WriteDB()
csv = WriteCSV()
print(db.write_db())
print(db.write_csv())
print(csv.write_db())
print(csv.write_csv())
La classe parent (FileHandling ) consiste en deux méthodes d'écriture dans une base de données et un fichier CSV. La classe gère les deux fonctions et renvoie un message.
Les deux classes enfants (WriteDB et WriteCSV ) héritent des propriétés de la classe parent (FileHandling ). Cependant, les deux enfants génèrent une erreur lorsqu'ils tentent d'utiliser la fonction d'écriture inappropriée, ce qui viole le principe de substitution de Liskov puisque les fonctions prioritaires ne correspondent pas aux fonctions parentes.
Le code suivant résout les problèmes :
# Parent class
class FileHandling():
def write(self):
return f'Handling file'
# Child classes
class WriteDB(FileHandling):
def write(self):
return f'Writing to a DB'
class WriteCSV(FileHandling):
def write(self):
return f'Writing to a CSV file'
if __name__ == "__main__":
# Parent class instantiation and function calls
db = FileHandling()
csv = FileHandling()
print(db.write())
print(csv.write())
# Children classes instantiations and function calls
db = WriteDB()
csv = WriteCSV()
print(db.write())
print(csv.write())
Les classes filles correspondent bien à la fonction mère.
Principe de séparation des interfaces (ISP)
Le principe de ségrégation d'interface (ISP) stipule :"De nombreuses interfaces spécifiques au client valent mieux qu'une interface à usage général."
En d'autres termes, les interfaces d'interaction plus étendues sont divisées en plus petites. Le principe garantit que les classes n'utilisent que les méthodes dont elles ont besoin, ce qui réduit la redondance globale.
L'exemple suivant illustre une interface à usage général :
class Animal():
def walk(self):
pass
def swim(self):
pass
class Cat(Animal):
def walk(self):
print("Struts")
def fly(self):
raise Exception("Cats don't swim")
class Duck(Animal):
def walk(self):
print("Waddles")
def swim(self):
print("Floats")
Les classes enfants héritent du parent Animal classe, qui contient walk et fly méthodes. Bien que les deux fonctions soient acceptables pour certains animaux, certains animaux ont des fonctionnalités redondantes.
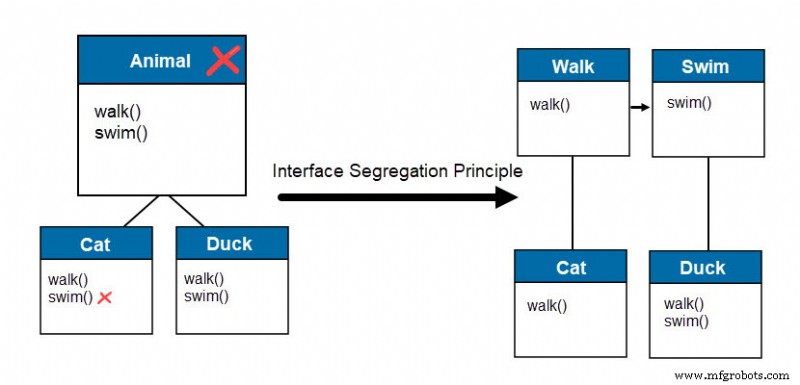
Pour gérer la situation, divisez l'interface en sections plus petites. Par exemple :
class Walk():
def walk(self):
pass
class Swim(Walk):
def swim(self):
pass
class Cat(Walk):
def walk(self):
print("Struts")
class Duck(Swim):
def walk(self):
print("Waddles")
def swim(self):
print("Floats")
Le Fly la classe hérite du Walk , fournissant des fonctionnalités supplémentaires aux classes enfants appropriées. L'exemple satisfait au principe de ségrégation d'interface.
L'ajout d'un autre animal, tel qu'un poisson, nécessite d'atomiser davantage l'interface puisque le poisson ne peut pas marcher.
Principe d'inversion de dépendance (DIP)
Le principe d'inversion de dépendance stipule :"Dépendez d'abstractions, pas de concrétions."
Le principe vise à réduire les connexions entre les classes en ajoutant une couche d'abstraction. Le déplacement des dépendances vers les abstractions rend le code robuste.
L'exemple suivant illustre la dépendance de classe sans couche d'abstraction :
class LatinConverter:
def latin(self, name):
print(f'{name} = "Felis catus"')
return "Felis catus"
class Converter:
def start(self):
converter = LatinConverter()
converter.latin('Cat')
if __name__ == '__main__':
converter = Converter()
converter.start()
L'exemple a deux classes :
LatinConverterutilise une API imaginaire pour récupérer le nom latin d'un animal (codé en dur "Felis catus” pour plus de simplicité).Converterest un module de haut niveau qui utilise une instance deLatinConverteret sa fonction pour convertir le nom fourni. LeConverterdépend fortement duLatinConverterclasse, qui dépend de l'API. Cette approche enfreint le principe.
Le principe d'inversion de dépendance nécessite l'ajout d'une couche d'interface d'abstraction entre les deux classes.
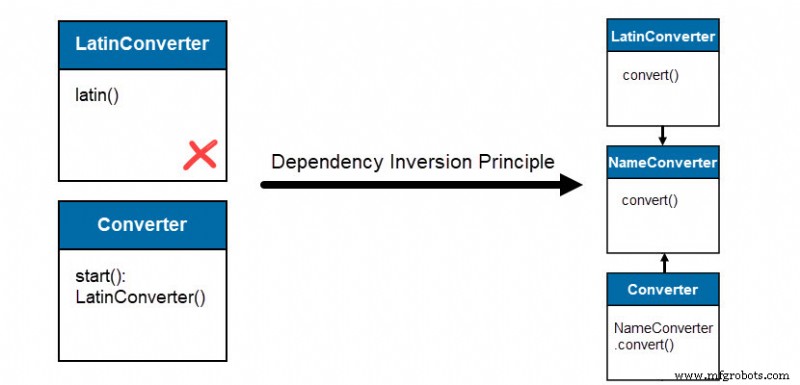
Un exemple de solution ressemble à ceci :
from abc import ABC
class NameConverter(ABC):
def convert(self,name):
pass
class LatinConverter(NameConverter):
def convert(self, name):
print('Converting using Latin API')
print(f'{name} = "Felis catus"')
return "Felis catus"
class Converter:
def __init__(self, converter: NameConverter):
self.converter = converter
def start(self):
self.converter.convert('Cat')
if __name__ == '__main__':
latin = LatinConverter()
converter = Converter(latin)
converter.start()
Le Converter la classe dépend maintenant du NameConverter interface au lieu de sur le LatinConverter directement. Les futures mises à jour permettent de définir des conversions de noms à l'aide d'un langage et d'une API différents via le NameConverter interface.
Pourquoi faut-il des principes SOLIDES ?
Les principes SOLID permettent de lutter contre les problèmes de design pattern. L'objectif global des principes SOLID est de réduire les dépendances de code, et l'ajout d'une nouvelle fonctionnalité ou la modification d'une partie du code ne casse pas l'ensemble de la construction.
Grâce à l'application des principes SOLID à la conception orientée objet, le code devient plus facile à comprendre, à gérer, à maintenir et à modifier. Étant donné que les règles sont mieux adaptées aux grands projets, l'application des principes SOLID augmente la vitesse et l'efficacité globales du cycle de développement.
Les principes SOLID sont-ils toujours pertinents ?
Bien que les principes SOLID aient plus de 20 ans, ils fournissent toujours une bonne base pour la conception d'architecture logicielle. SOLID fournit des principes de conception solides applicables aux programmes et environnements modernes, et pas seulement à la programmation orientée objet.
Les principes SOLID s'appliquent dans les situations où le code est écrit et modifié par des personnes, organisé en modules et contient des éléments internes ou externes.
Conclusion
Les principes SOLID aident à fournir un bon cadre et un bon guide pour la conception de l'architecture logicielle. Les exemples de ce guide montrent que même un langage à typage dynamique tel que Python bénéficie de l'application des principes à la conception de code.
Ensuite, découvrez les 9 principes DevOps qui aideront votre équipe à tirer le meilleur parti de DevOps.
Cloud computing