


Développer de nouvelles habitudes de codage pour réduire les erreurs dans les logiciels embarqués
La taille et la complexité des applications se sont considérablement alourdies au cours de la dernière décennie. Prenons l'exemple du secteur automobile. Selon Le New York Times , il y a 20 ans, la voiture moyenne avait un million de lignes de code, mais 10 ans plus tard, la Chevrolet Volt 2010 de General Motors avait environ 10 millions de lignes de code, soit plus qu'un avion de chasse F-35. Aujourd'hui, une voiture moyenne a plus de 100 millions de lignes de code.
Le passage aux processeurs 32 bits et supérieurs avec beaucoup de mémoire et de puissance a permis aux entreprises d'intégrer beaucoup plus de fonctionnalités et de capacités à valeur ajoutée dans les conceptions; c'est le bon côté. L'inconvénient est que la quantité de code et sa complexité entraînent souvent des défaillances qui ont un impact sur la sécurité et la sûreté des applications.
Il est temps pour une meilleure approche. Deux principaux types d'erreurs peuvent être détectés dans le logiciel et résolus à l'aide d'outils qui empêchent l'introduction d'erreurs :
- Erreurs de codage :un exemple est le code qui tente d'accéder en dehors des limites d'un tableau. Ces types de problèmes peuvent être détectés en effectuant une analyse statique.
- Erreurs d'application :elles ne peuvent être détectées qu'en sachant exactement ce que l'application est censée faire, ce qui signifie tester par rapport aux exigences.
Corrigez ces erreurs et les ingénieurs de conception auront parcouru un long chemin vers un code plus sûr et sécurisé.
Une once de prévention via la vérification de code
Les erreurs de code se produisent aussi facilement que les erreurs de courrier électronique et de messagerie instantanée. Ce sont les erreurs simples qui se produisent parce que les ingénieurs sont pressés et ne relisent pas. Mais avec la complexité vient une gamme d'erreurs de conception qui créent d'énormes défis. La complexité engendre le besoin d'un tout nouveau niveau de compréhension du fonctionnement du système, de la transmission des données et de la définition des valeurs. Que les erreurs soient causées par la complexité ou une sorte de problème humain, elles peuvent entraîner un morceau de code essayant d'accéder à une valeur en dehors des limites d'un tableau. Et, une norme de codage capture cela.
Vous pourriez également être intéressé par ces articles connexes d'Embedded :
Construisez des systèmes embarqués sécurisés et fiables avec MISRA C/C++
Utilisation de l'analyse statique pour détecter les erreurs de codage dans les applications serveur open source critiques pour la sécurité
Comment éviter de telles erreurs ? Ne les mettez pas là en premier lieu. Bien que cela semble évident et presque impossible, c'est exactement la valeur qu'une norme de codage apporte à la table.
Dans le monde C et C++, 80% des défauts logiciels sont causés par l'utilisation incorrecte ou malavisée d'environ 20% du langage. La norme de codage crée des restrictions sur les parties de la langue connues pour être problématiques. Résultat :les défauts sont évités et la qualité du logiciel augmente considérablement. Jetons un coup d'œil à quelques exemples.
La plupart des erreurs de programmation C et C++ sont causées par des comportements non définis, définis par l'implémentation et non spécifiés inhérents à chaque langage, ce qui entraîne des bogues logiciels et des problèmes de sécurité. Ce comportement défini par l'implémentation propage un bit de poids fort lorsqu'un entier signé est décalé vers la droite. Selon l'utilisation par les ingénieurs du compilateur, le résultat peut être 0x4000000 ou 0xC0000000 car C ne spécifie pas l'ordre dans lequel les arguments d'une fonction sont évalués.
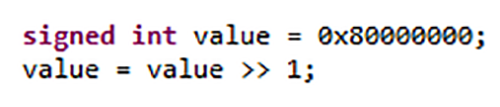
Figure 1. Le comportement de certaines constructions C et C++ dépend du compilateur utilisé. Source :LDRA
Dans la figure 2, où le rollDice() La fonction lit simplement la valeur suivante à partir d'un tampon circulaire contenant les valeurs "1,2,3 et 4" - la valeur renvoyée attendue serait 1234. Mais il n'y a aucune garantie à ce sujet. Au moins un compilateur génère du code qui renvoie la valeur 3412.

Figure 2. Le comportement de certaines constructions C et C++ n'est pas spécifié par les langages. Source :LDRA
Il y a beaucoup d'autres pièges dans le langage C/C++ :l'utilisation de constructions telles que goto ou malloc; mélanges de valeurs signées et non signées ; ou un code « intelligent » qui peut être très efficace et compact, mais qui est si cryptique et complexe que d'autres ont du mal à le comprendre. N'importe lequel de ces problèmes peut entraîner des défauts, des débordements de valeur qui deviennent soudainement négatifs, ou simplement rendre le code impossible à maintenir.
Les normes de codage fournissent une once de prévention pour ces maux. Ils peuvent empêcher l'utilisation de ces constructions problématiques et empêcher les développeurs de créer du code non documenté et trop complexe, ainsi que de vérifier la cohérence du style. Même des choses comme vérifier que le caractère de tabulation n'est pas utilisé ou que les parenthèses sont positionnées dans une position spécifique peuvent être surveillées. Bien que cela semble trivial, suivre le style aide énormément à la révision manuelle du code et évite les confusions causées par une taille d'onglet différente lorsque le code est affiché dans un autre éditeur, autant de distractions qui empêchent un réviseur de se concentrer sur le code.
MISRA à la rescousse
Les normes de programmation les plus connues sont les directives MISRA, publiées pour la première fois en 1998 pour l'industrie automobile et maintenant couramment adoptées par de nombreux compilateurs embarqués qui offrent un certain niveau de vérification MISRA. MISRA se concentre sur les constructions et les pratiques problématiques au sein des langages C et C++, en recommandant l'utilisation de caractéristiques stylistiques cohérentes tout en s'abstenant d'en suggérer.
Les directives MISRA fournissent des explications utiles sur la raison de l'existence de chaque règle, ainsi que des détails sur les diverses exceptions à cette règle et des exemples de comportement non défini, non spécifié et défini par l'implémentation. La figure 3 illustre le niveau de guidage.

Figure 3. Ces références MISRA C concernent un comportement non défini, non spécifié et défini par l'implémentation. Source :LDRA
La majorité des directives MISRA sont « décidables », ce qui signifie que l'outil peut identifier s'il y a une violation ; mais certains sont « indécidables », ce qui implique qu'il n'est pas toujours possible pour l'outil de déduire s'il y a une violation.
Une variable non initialisée transmise à une fonction système qui doit l'initialiser peut ne pas être enregistrée comme une erreur si l'outil d'analyse statique n'a pas accès au code source de la fonction système. Il existe un risque de faux négatif ou de faux positif.
En 2016, 14 directives ont été ajoutées à MISRA pour permettre la vérification du code critique pour la sécurité, et pas seulement pour la sécurité. La figure 4 illustre comment l'une des nouvelles directives, la directive 4.14, résout ce problème et aide à éviter les pièges dus à un comportement indéfini.

Figure 4. La directive MISRA 4.14 permet d'éviter les pièges causés par un comportement indéfini. Source :LDRA
Les rigueurs des normes de codage étaient traditionnellement associées à des logiciels fonctionnellement sûrs pour des applications critiques telles que les voitures, les avions et les appareils médicaux. Cependant, la complexité du code, la criticité de la sécurité et l'importance commerciale de la création d'un code robuste de haute qualité, facile à entretenir et à mettre à niveau rendent les normes de codage cruciales dans toutes les opérations de développement.
En veillant à ce que les erreurs ne soient pas introduites dans le code en premier lieu, les équipes de développement doivent :
- réduire le besoin d'un débogage approfondi,
- mieux contrôler le calendrier, et
- contrôler le retour sur investissement en réduisant les coûts globaux.
La vérification du code offre une boîte à outils avec d'énormes avantages potentiels.
Une livre de remède avec des outils de test
Alors que la vérification du code résout de nombreux problèmes, les bogues d'application ne peuvent être détectés qu'en testant que le produit fait ce qu'il est censé faire, ce qui signifie avoir des exigences. Éviter les bogues d'application nécessite à la fois de concevoir le bon produit et de bien concevoir le produit.
Concevoir le bon produit signifie établir des exigences dès le départ et assurer une traçabilité bidirectionnelle entre les exigences et le code source, de sorte que chaque exigence soit implémentée et que chaque fonction logicielle remonte à une exigence. Toute fonctionnalité manquante ou inutile (qui ne répond pas à une exigence) est un bogue d'application. Concevoir correctement le produit consiste à confirmer que le code système développé répond aux exigences du projet. Vous y parvenez en effectuant des tests basés sur les exigences.
La figure 5 montre un exemple de traçabilité bidirectionnelle. La fonction unique sélectionnée remonte en amont de la fonction à une exigence de bas niveau, puis à une exigence de haut niveau et enfin à une exigence de niveau système.
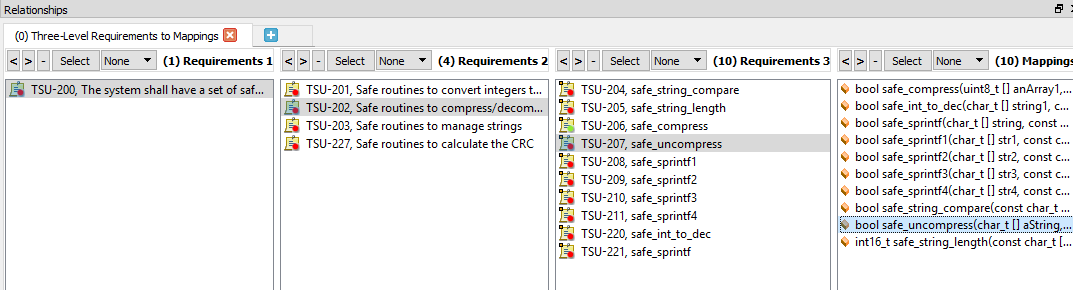
Figure 5. Voici un exemple de traçabilité bidirectionnelle avec une seule fonction sélectionnée. Source :LDRA
La figure 6 montre comment la sélection d'une exigence de haut niveau affiche à la fois la traçabilité en amont vers une exigence de niveau système et en aval vers les exigences de bas niveau et vers les fonctions du code source.
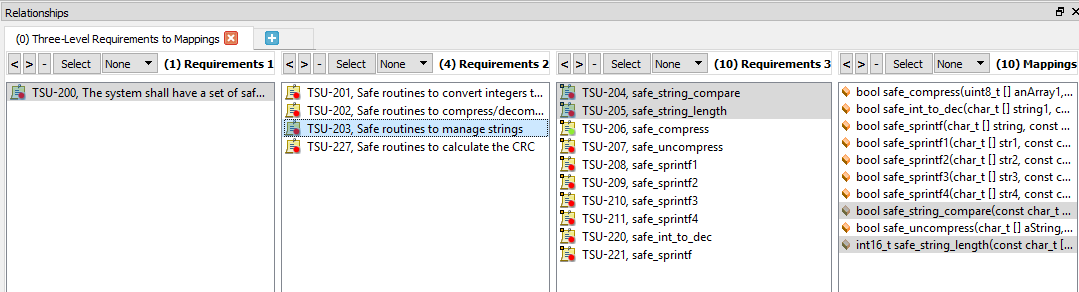
Figure 6. Voici un exemple de traçabilité bidirectionnelle avec des exigences sélectionnées. Source :LDRA
Cette capacité à visualiser la traçabilité peut conduire à la détection de bugs applicatifs tôt dans le cycle de vie.
Tester la fonctionnalité du code exige une connaissance de ce qu'il est censé faire, ce qui signifie avoir des exigences de bas niveau indiquant ce que fait chaque fonction. La figure 7 montre un exemple d'exigence de bas niveau, qui, dans ce cas, décrit entièrement une fonction unique.
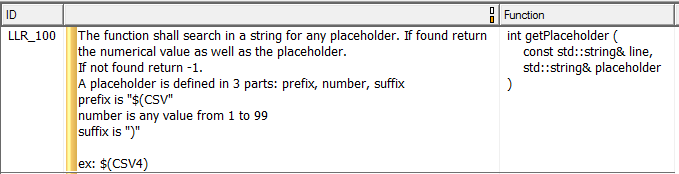
Figure 7. Voici un exemple d'exigence de bas niveau décrivant une fonction unique. Source :LDRA
Les cas de test sont dérivés d'exigences de bas niveau, comme illustré à la figure 8.
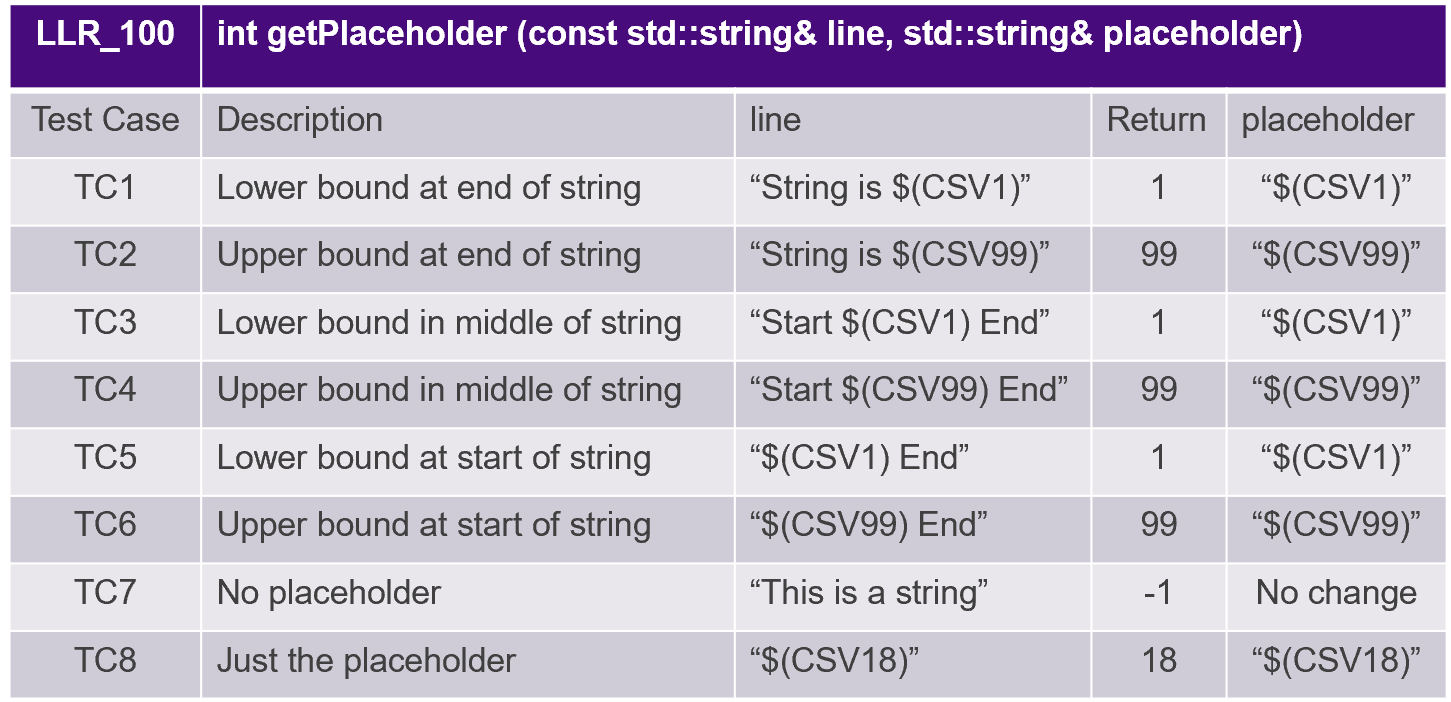
Figure 8. Les cas de test sont dérivés d'exigences de bas niveau. Source :LDRA
À l'aide d'un outil de test unitaire, ces cas de test peuvent ensuite être exécutés sur l'hôte ou la cible pour garantir que le code se comporte comme l'exigence le dit. La figure 9 montre que tous les cas de test ont été régressés et réussis.
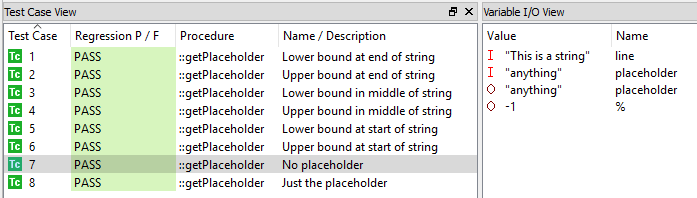
Figure 9. Voici comment un outil effectue des tests unitaires. Source :LDRA
Une fois les cas de test exécutés, la couverture structurelle doit être mesurée pour s'assurer que tout le code a été exercé. Si la couverture n'est pas à 100 %, il est possible que d'autres cas de test soient nécessaires ou que le code superflu soit supprimé.
Nouvelles habitudes de codage
Il ne fait aucun doute que la complexité logicielle et ses erreurs se sont multipliées avec la connectivité, une mémoire plus rapide, des plates-formes matérielles riches et des demandes spécifiques des clients. L'adoption d'une norme de codage de pointe, la mesure des métriques sur le code, le traçage des exigences et la mise en œuvre de tests basés sur les exigences offrent aux équipes de développement la possibilité de créer un code de haute qualité et de réduire la responsabilité.
La mesure dans laquelle une équipe adopte ces nouvelles habitudes lorsqu'aucune norme n'exige la conformité dépend de la reconnaissance par l'entreprise du changement qu'elles apportent. L'adoption de ces pratiques, qu'un produit soit critique pour la sécurité ou la sûreté, peut faire une différence jour et nuit dans la maintenabilité et la robustesse du code. Un code propre simplifie l'ajout de nouvelles fonctionnalités, facilite la maintenance des produits et réduit les coûts et le calendrier au minimum, autant de caractéristiques qui améliorent le retour sur investissement de votre entreprise.
Qu'un produit soit critique pour la sécurité ou non, c'est certainement un résultat qui ne peut être que bénéfique pour l'équipe de développement.
>> Cet article a été initialement publié le notre site frère, EDN.
Embarqué
- Les chaînes de texte sont-elles une vulnérabilité dans les logiciels embarqués ?
- L'architecture SOAFEE pour la périphérie embarquée permet des voitures définies par logiciel
- Pixus :nouvelles façades épaisses et robustes pour cartes embarquées
- GE Digital lance un nouveau logiciel de gestion des actifs
- Comment ne pas être nul dans l'enseignement de nouveaux logiciels
- Risques logiciels :sécurisation de l'open source dans l'IoT
- Trois étapes pour sécuriser les chaînes d'approvisionnement logicielles
- Saelig lance un nouveau PC embarqué fabriqué par Amplicon
- Utiliser DevOps pour relever les défis des logiciels embarqués