


Apprendre le langage de programmation C intégré :comprendre l'objet de données Union
En savoir plus sur les objets de données appelés unions dans le langage C intégré.
En savoir plus sur les objets de données appelés unions dans le langage C intégré.
La différence entre la structure et l'union dans le C embarqué
Dans un article précédent de cette série, nous avons expliqué que les structures en C embarqué nous permettent de regrouper des variables de différents types de données et de les traiter comme un seul objet de données.
En plus des structures, le langage C prend en charge une autre construction de données, appelée union, qui peut regrouper différents types de données en un seul objet de données. Cet article fournira quelques informations de base sur les syndicats. Nous examinerons d'abord un exemple introductif de déclaration d'union, puis nous examinerons une application importante de cet objet de données.
Exemple d'introduction
Déclarer un syndicat, c'est un peu comme déclarer une structure. Il suffit de remplacer le mot-clé « struct » par « union ». Considérez l'exemple de code suivant :
test d'union { uint8_t c; uint32_t i;}; Ceci spécifie un modèle qui a deux membres :"c", qui prend un octet, et "i", qui occupe quatre octets.
Maintenant, nous pouvons créer une variable de ce modèle d'union :
test syndical u1 ; En utilisant l'opérateur membre (.), nous pouvons accéder aux membres de l'union « u1 ». Par exemple, le code suivant affecte 10 au deuxième membre de l'union ci-dessus et copie la valeur de "c" dans la variable "m" (qui doit être de type uint8_t).
u1.i=10;m=u1.c; Combien d'espace mémoire sera alloué pour stocker la variable « u1 » ? Alors que la taille d'une structure est au moins aussi grande que la somme des tailles de ses membres, la taille d'un syndicat est égale à la taille de sa plus grande variable. L'espace mémoire alloué à une union sera partagé entre tous les membres de l'union. Dans l'exemple ci-dessus, la taille de « u1 » est égale à la taille de uint32_t, c'est-à-dire quatre octets. Cet espace mémoire est partagé entre « i » et « c ». Par conséquent, attribuer une valeur à l'un de ces deux membres modifiera la valeur de l'autre membre.
Vous vous demandez peut-être « A quoi bon utiliser le même espace mémoire pour stocker plusieurs variables ? Existe-t-il une application pour cette fonctionnalité ? » Nous explorerons ce problème dans la section suivante.
Avons-nous besoin d'un espace mémoire partagé ?
Regardons un exemple où une union peut être un objet de données utile. Supposons que, comme le montre la figure 1 ci-dessous, il y a deux appareils dans votre système qui doivent communiquer entre eux.

Figure 1
« Device A » doit envoyer des informations sur l'état, la vitesse et la position à « Device B ». Les informations d'état se composent de trois variables qui indiquent la charge de la batterie, le mode de fonctionnement et la température ambiante. La position est représentée par deux variables qui montrent les positions des axes x et y. Enfin, la vitesse est représentée par une seule variable. Supposons que la taille de ces variables est celle indiquée dans le tableau suivant.
| Nom de la variable | Taille (octet) | Explication |
| puissance | 1 | Charge de la batterie |
| op_mode | 1 | Mode de fonctionnement |
| temp | 1 | Température |
| x_pos | 2 | Position X |
| y_pos | 2 | Position Y |
| vel | 2 | Vitesse |
Si « Device B » a constamment besoin de chaque élément de cette information, nous pouvons stocker toutes ces variables dans une structure et envoyer la structure à « Device B ». La taille de la structure sera au moins aussi grande que la somme de la taille de ces variables, c'est-à-dire neuf octets.
Ainsi, chaque fois que « Device A » parle à « Device B », il doit transférer une trame de données de 9 octets via la liaison de communication entre les deux appareils. La figure 2 décrit la structure que le « Dispositif A » utilise pour stocker les variables et la trame de données qui doit passer par le lien de communication.

Figure 2
Cependant, considérons un scénario différent où nous n'avons qu'occasionnellement besoin d'envoyer les informations d'état. Supposons également qu'il ne soit pas nécessaire d'avoir à la fois des informations de position et de vitesse à un moment donné. En d'autres termes, parfois nous n'envoyons que la position, parfois nous n'envoyons que la vélocité, et parfois nous n'envoyons que des informations de statut. Dans cette situation, il ne semble pas être une bonne idée de stocker les informations dans une structure de neuf octets et de les transférer via le lien de communication.
Les informations d'état ne peuvent être représentées que par trois octets; pour la position et la vitesse, nous n'avons besoin que de quatre et deux octets, respectivement. Par conséquent, le nombre maximal d'octets que le « périphérique A » doit envoyer dans un transfert est de quatre, et par conséquent, nous n'avons besoin que de quatre octets de mémoire pour stocker ces informations. Cet espace mémoire de quatre octets sera partagé entre nos trois types de messages (voir Figure 3).
De plus, notez que la longueur de la trame de données transmise via le lien de communication est réduite de neuf octets à quatre octets.
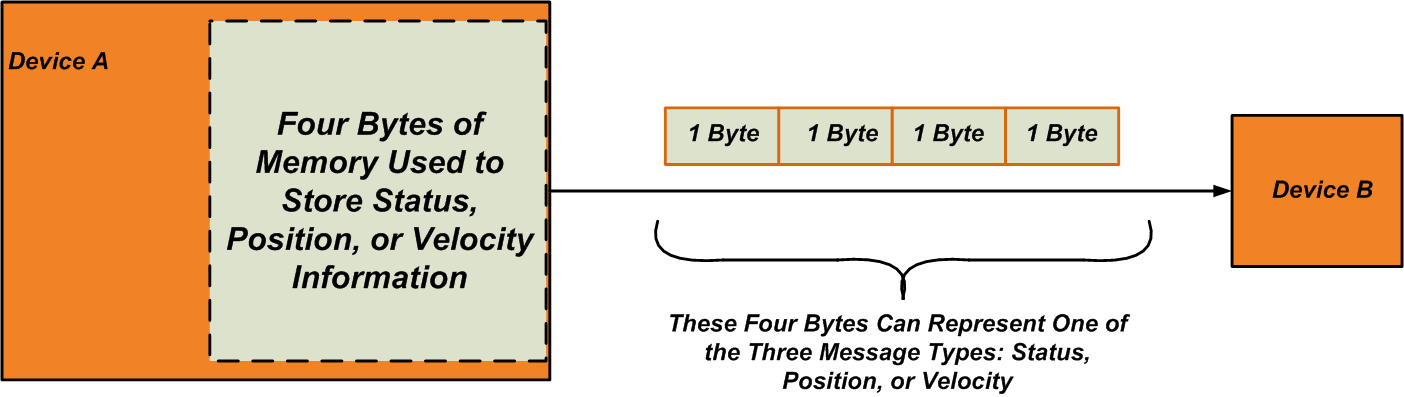
Figure 3
Pour résumer, si notre programme a des variables qui s'excluent mutuellement, nous pouvons les stocker dans une zone de mémoire partagée pour préserver un espace mémoire précieux. Cela peut être important, en particulier dans le contexte des systèmes embarqués à mémoire limitée. Dans de tels cas, nous pouvons utiliser des unions pour créer l'espace mémoire partagé requis.
L'exemple ci-dessus montre que l'utilisation d'une union pour gérer des variables mutuellement exclusives peut également nous aider à conserver la bande passante de communication. La conservation de la bande passante de communication est parfois encore plus importante que la conservation de la mémoire.
Utilisation d'unions pour les paquets de messages
Voyons comment nous pouvons utiliser une union pour stocker les variables de l'exemple ci-dessus. Nous avions trois types de messages différents :statut, position et vélocité. Nous pouvons créer une structure pour les variables des messages d'état et de position (afin que les variables de ces messages soient regroupées et manipulées comme un seul objet de données).
Les structures suivantes servent à cet effet :
struct { uint8_t power; unit8_t op_mode; uint8_t temp;} status;struct { uint16_t x_pos; unit16_t y_pos;} position; Maintenant, nous pouvons mettre ces structures avec la variable « vel » dans une union :
union {struct { uint8_t power; unit8_t op_mode; uint8_t temp;} status;struct { uint16_t x_pos; unit16_t y_pos;} position ; uint16_t vel;} msg_union; Le code ci-dessus spécifie un modèle d'union et crée une variable de ce modèle (nommée « msg_union »). A l'intérieur de cette union, il y a deux structures ("status" et "position") et une variable à deux octets ("vel"). La taille de cette union sera égale à la taille de son membre le plus grand, à savoir la structure « position », qui occupe quatre octets de mémoire. Cet espace mémoire est partagé entre les variables « status », « position » et « vel ».
Comment garder une trace du membre actif de l'Union
Nous pouvons utiliser l'espace mémoire partagé de l'union ci-dessus pour stocker nos variables; cependant, il reste une question :comment le destinataire doit-il déterminer quel type de message a été envoyé ? Le récepteur doit reconnaître le type de message pour pouvoir interpréter avec succès les informations reçues. Par exemple, si nous envoyons un message de "position", les quatre octets des données reçues sont importants, mais pour un message de "vitesse", seuls deux des octets reçus doivent être utilisés.
Pour résoudre ce problème, nous devons associer notre union à une autre variable, disons "msg_type", qui indique le type de message (ou le membre de l'union auquel on a écrit en dernier). Une union associée à une valeur discrète qui indique que le membre actif de l'union est appelée « union discriminée » ou « union étiquetée ».
Concernant le type de données de la variable « msg_type », nous pouvons utiliser le type de données énumération du langage C pour créer des constantes symboliques. Cependant, nous utiliserons un caractère pour spécifier le type de message, juste pour que les choses soient aussi simples que possible :
struct { uint8_t msg_type;union {struct { uint8_t power; unit8_t op_mode; uint8_t temp;} status;struct { uint16_t x_pos; unit16_t y_pos;} position ; uint16_t vel;} msg_union;} message; On peut considérer trois valeurs possibles pour la variable « msg_type » :« s » pour un message « status », « p » pour un message « position », et « v » pour un message « speed ». Maintenant, nous pouvons envoyer la structure « message » à « Device B » et utiliser la valeur de la variable « msg_type » comme indicateur du type de message. Par exemple, si la valeur du "msg_type" reçu est "p", "Device B" saura que l'espace mémoire partagé contient deux variables de 2 octets.
Notez que nous devrons ajouter un autre octet à la trame de données envoyée via le lien de communication car nous devons transférer la variable "msg_type". Notez également qu'avec cette solution, le destinataire n'a pas besoin de savoir à l'avance quel type de message arrive.
La solution alternative :l'allocation dynamique de mémoire
Nous avons vu que les unions permettent de déclarer une zone de mémoire partagée pour conserver à la fois l'espace mémoire et la bande passante de communication. Il existe cependant un autre moyen de stocker des variables mutuellement exclusives telles que celles de l'exemple ci-dessus. Cette seconde solution utilise l'allocation dynamique de mémoire pour stocker les variables de chaque type de message.
Encore une fois, nous aurons besoin d'une variable "msg_type" pour spécifier le type de message à la fois au niveau de l'émetteur et du récepteur de la liaison de communication. Par exemple, si "Device A" doit envoyer un message de position, il définira "msg_type" sur "p" et allouera quatre octets d'espace mémoire pour stocker les variables "x_pos" et "y_pos". Le récepteur vérifiera la valeur de « msg_type » et, en fonction de sa valeur, créera l'espace mémoire approprié pour stocker et interpréter la trame de données entrante.
L'utilisation de la mémoire dynamique peut être plus efficace en termes d'utilisation de la mémoire car nous allouons juste assez d'espace pour chaque type de message. Ce n'était pas le cas de la solution syndicale. Là, nous avions quatre octets de mémoire partagée pour stocker les trois types de messages, bien que les messages « état » et « vitesse » ne nécessitaient respectivement que trois et deux octets. Cependant, l'allocation dynamique de mémoire peut être plus lente et le programmeur doit inclure du code qui libère la mémoire allouée. C'est pourquoi les programmeurs préfèrent généralement utiliser la solution basée sur l'union.
Prochaine étape : Applications des syndicats
Il semble que le but initial des unions était de créer une zone de mémoire partagée pour des variables mutuellement exclusives. Cependant, les unions ont également été largement utilisées pour extraire de plus petites parties de données à partir d'un objet de données plus grand.
Le prochain article de cette série se concentrera sur cette application des unions, qui peut être particulièrement importante dans les applications embarquées.
Pour voir une liste complète de mes articles, veuillez visiter cette page.
Embarqué
- Programmation du microprocesseur
- Que dois-je faire avec les données ? !
- Démocratiser l'IoT
- 9 nouveaux langages de programmation à apprendre en 2021
- C - Syndicats
- L'avenir des centres de données
- Le Cloud dans l'IoT
- Commentaire :comprendre les méthodes de programmation des robots
- Parler le même langage industriel :comprendre les unités de mesure courantes d'un compresseur